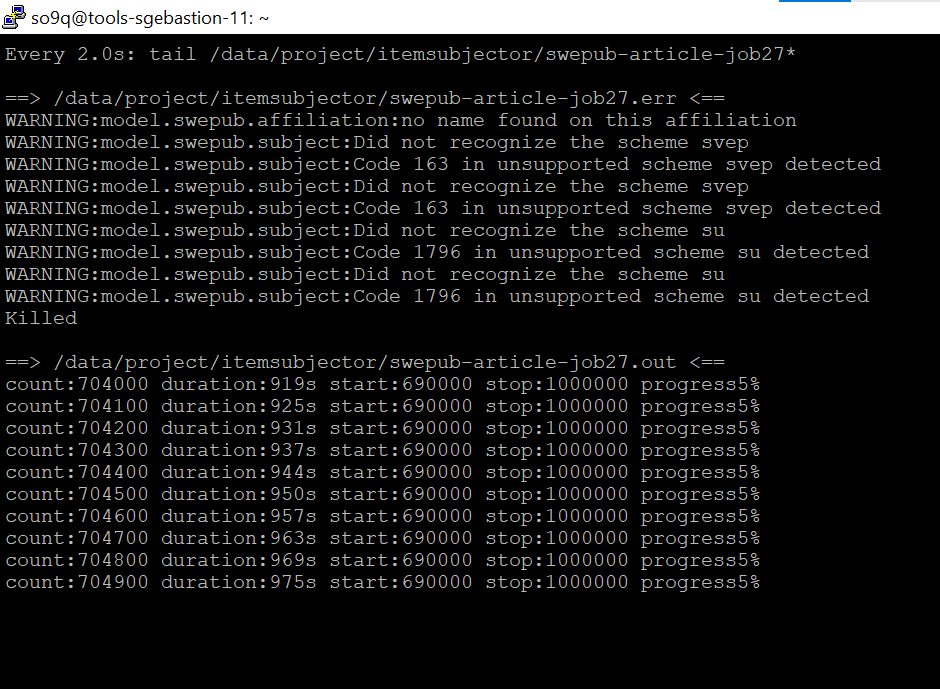
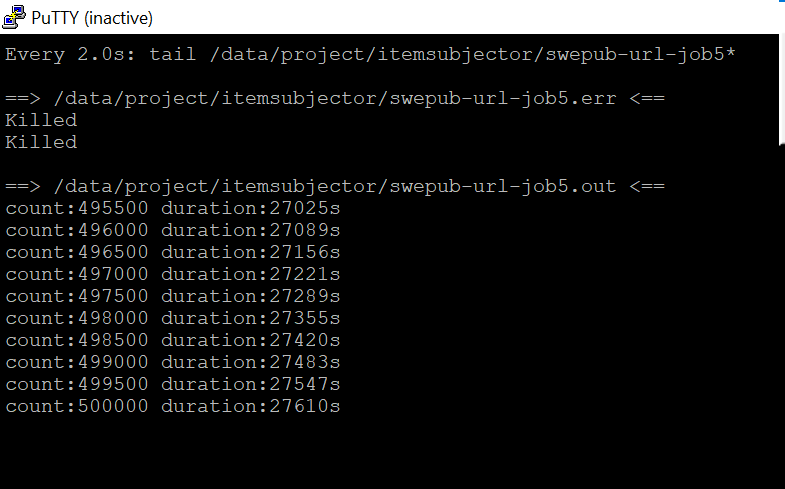
Jobs with large output from pandas seem to get killed consistently on k8s
List of steps to reproduce (step by step, including full links if applicable):
- git clone https://github.com/dpriskorn/WikidataMLSuggester/
- edit export_every_x_linenumber variable in extract-articles-from-swepub.py and set it to some huge number like 400000
- run ./create_kubernettes_article_job_and_watch_the_log.sh 1
- wait for it to get killed during the pd.to_pickle() call
What happens?:
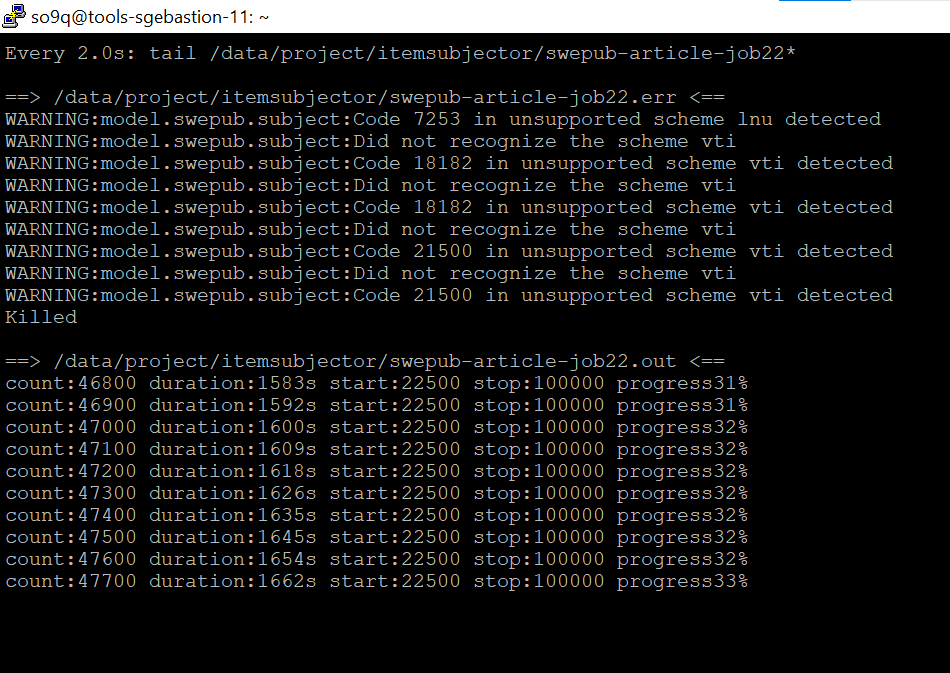
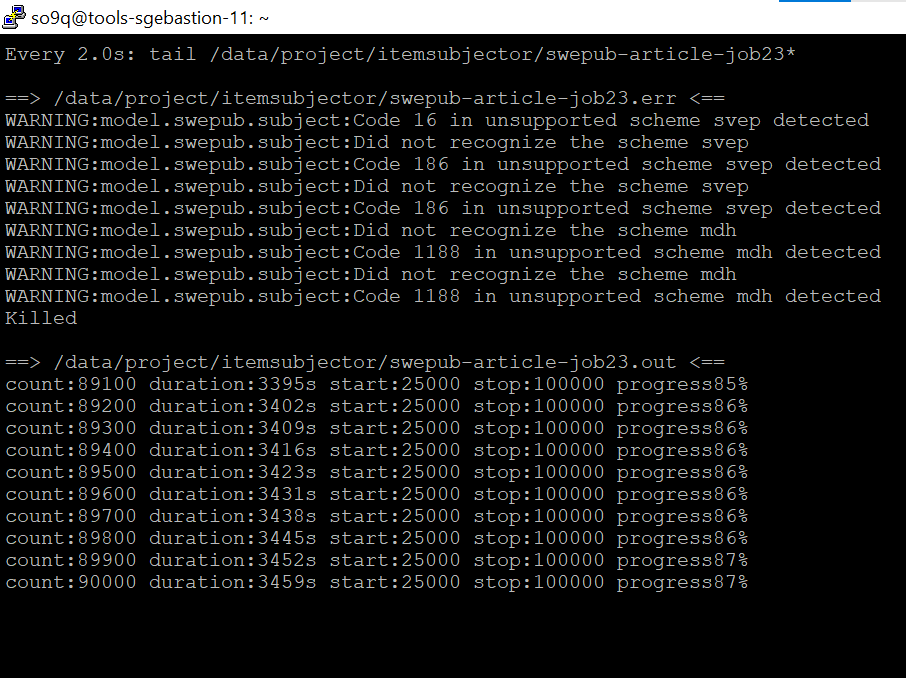
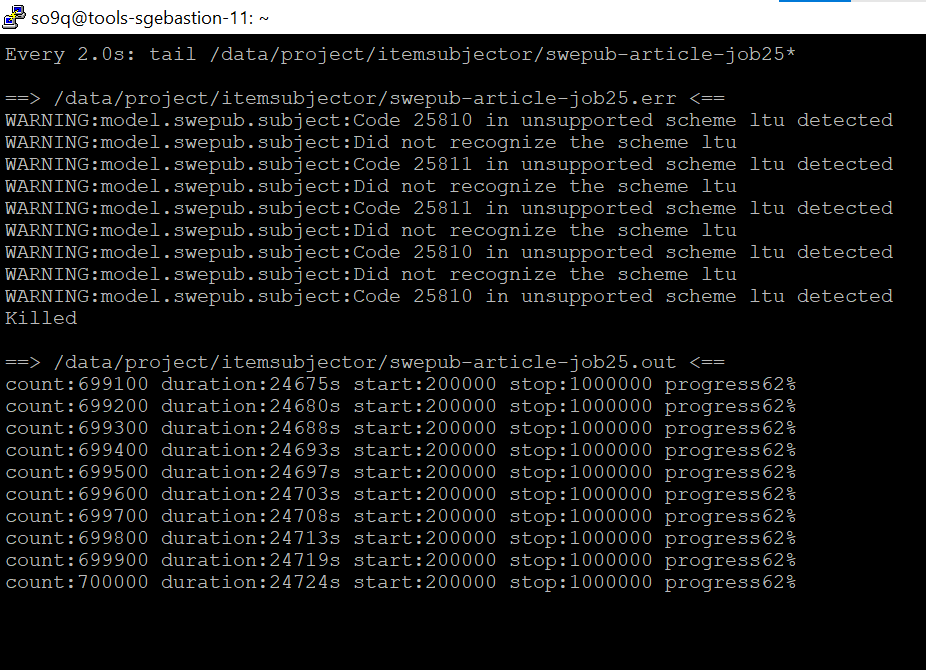
the job gets killed and has "Killed" in the error log, see screenshot above
What should have happened instead?:
error that is easy for the user to understand and/or better documentation on the limits of the pods / k8s cluster
Software version (if not a Wikimedia wiki), browser information, screenshots, other information, etc.: