RESTBase/HyperSwitch (allegedly )uses RFC 7807 HTTP problems, JSON-encoded response objects that describe errors. We should determine/decide what attributes and values (if any) are considered a part of the AQS contract. Additionally, in any instances where the current production system deviates from RFC 7807 (intentional or otherwise), do we treat this as a bug (read: fix it), or reproduce this in the new system?
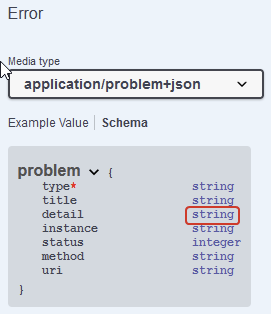
For example: The RFC describes the detail attribute as a string, but see the following:
$ curl -X GET -H 'accept: application/json' 'https://wikimedia.org/api/rest_v1/metrics/pageviews/per-article/EN.WIKIPEDIA.ORG/all-access/all-agents/Banana/daily/20190101/201901a2' { "type": "https://mediawiki.org/wiki/HyperSwitch/errors/invalid_request", "method": "get", "detail": [ "end timestamp is invalid, must be a valid date in YYYYMMDD format" ], "uri": "/analytics.wikimedia.org/v1/pageviews/per-article/EN.WIKIPEDIA.ORG/all-access/all-agents/Banana/daily/20190101/201901a2" } $
In the returned error object, detail is an array.
See also: RFC7807: Problem Details for HTTP APIs