Description: An instance of the WMF fork of LinkedIn's DataHub software. This will act as a metadata repository, facilitating data discovery by users and improving overall data governance. This is in support of the Foundation's Data as a Service OKR.
The design document for this is here. (Currently retricted to WMF)
Timeline: As soon as possible please. We are at an MVP phase and we would like to begin working with the system as soon as possible.
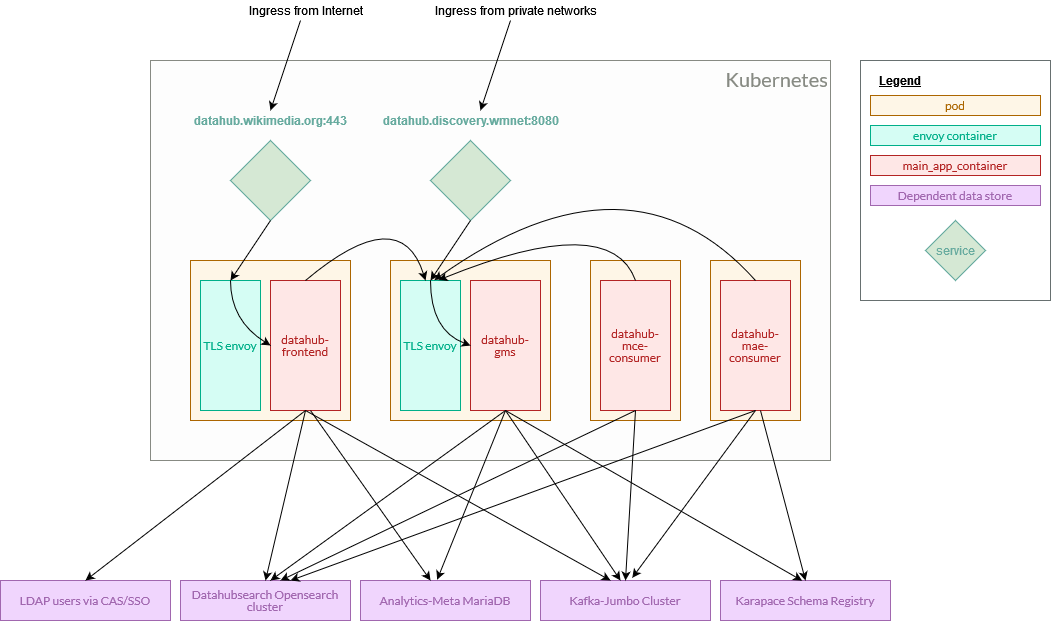
Diagram: Here is a simplified diagram (src), showing the four types of daemon pod, along with their expected network requests. The Kubernetes deployments are all stateless and can be deployed to either data centre, but the back-end data tiers (MariaDB, Elasticsearch, Kafka, Karapace) are all located in eqiad.
Technologies: All components are written in Java, but the front-end also has a React component
Point person: @BTullis and anyone else from the Data-Engineering team
All of the containers have been created using PipelineLib and are hosted on docker-registry.wikimedia.org
Changelog:
- Uploaded a second version of the diagram, clarifying traffic paths, removing default port numbers, and including the karapace backend.