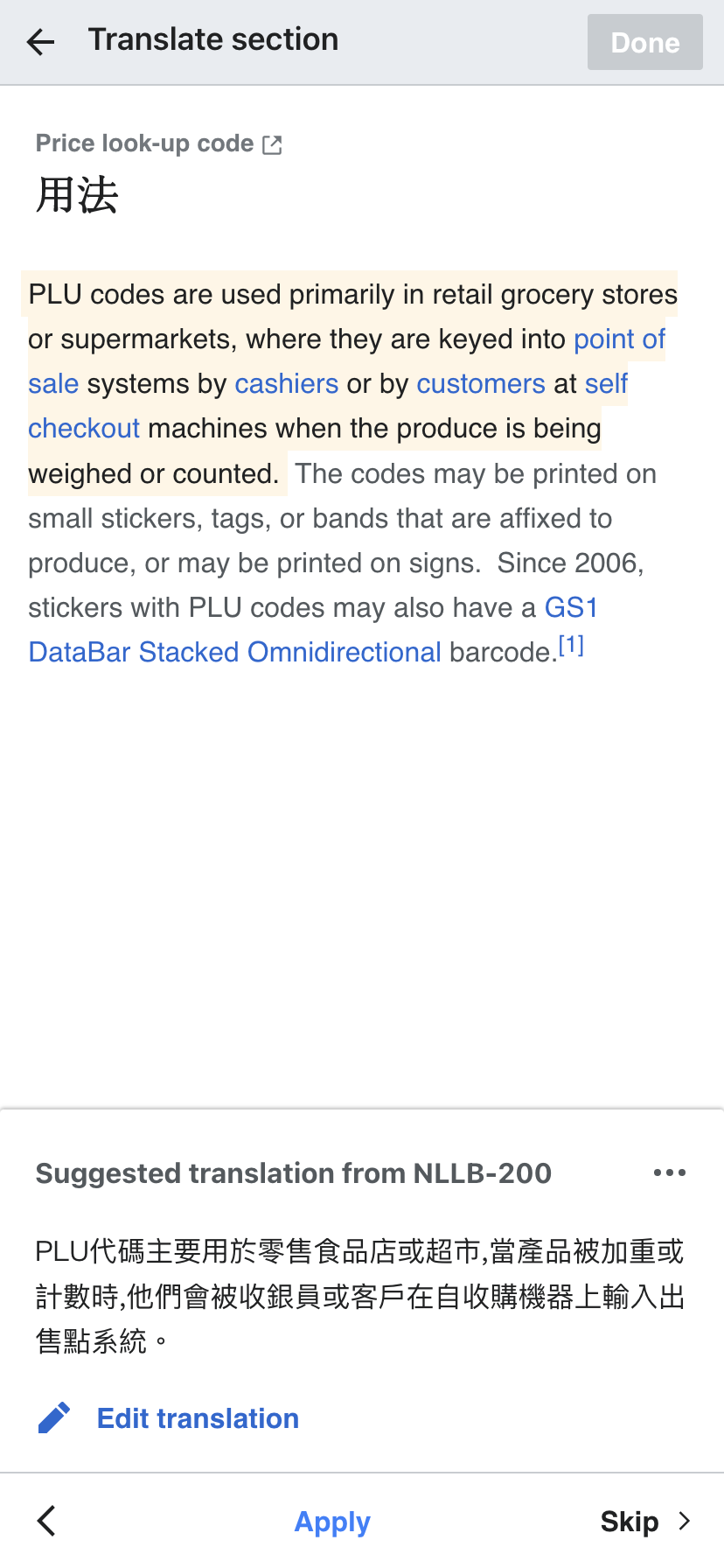
Content Translation has been used to translate more than a million articles across all languages. Content Translation is provided by default in 92 language Wikipedias, and Section Translation is available in 18 wikis.
Given the editor activity on Cantonese Wikipedia and the mobile usage we consider that they could benefit from having both Content and Section Translation enabled by default. As part of this process, we want to learn from the Cantonese editing community how well those tools suit their needs and identify potential improvements. We'll communicate with the editing community and only proceed with the enablement if there is no major concern.
Steps:
-
Generate template parameter alignments (T221211)(not available as per T304865#7866874) - Enable selected wikis on Test Wikipedia
- Communicate with the communities
- Enable in the selected Wikipedias