It would be really useful to be able to ingest from Superset into our DataHub MVP.
https://datahubproject.io/docs/metadata-ingestion/source_docs/superset
This creates chart and dashboard objects in DataHub with associated metadata.
| BTullis | |
| Apr 26 2022, 2:11 PM |
| F35318056: image.png | |
| Jul 15 2022, 2:49 PM |
| F35178630: image.png | |
| May 26 2022, 10:03 AM |
| F35178637: image.png | |
| May 26 2022, 10:03 AM |
| F35178628: image.png | |
| May 26 2022, 10:03 AM |
| F35178650: image.png | |
| May 26 2022, 10:03 AM |
It would be really useful to be able to ingest from Superset into our DataHub MVP.
https://datahubproject.io/docs/metadata-ingestion/source_docs/superset
This creates chart and dashboard objects in DataHub with associated metadata.
| Subject | Repo | Branch | Lines +/- | |
|---|---|---|---|---|
| Add base_uri config parameter to Superset source | analytics/datahub | wmf | +12 -4 |
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | BTullis | T299910 Data Catalog MVP | |||
| Resolved | BTullis | T306903 Integrate Superset with DataHub |
I did a little work on this, but it is a little complicated by the way that we have authentication configured for Superset.
With superset we set AUTH_TYPE = REMOTE_USER here which means that we trust the gunicorn web server to authenticate the user and then set the REMOTE_USER header to the shell login name.
gunicorn itself offloads authentication to Apereo-CAS for single-sign-on.
So our users are created in the superset database, but have no password assigned.
The superset plugin for datahub supports the db provider for passwords, or the ldap provider it seems. I can't find a way to either bypass the authentication requirements or to select something that is compatibel with our setup.
I tried manually modifying the configuration of the staging environment on an-tool1005 (in /etc/superset/superset_config.py) in order to make it work, by:
Then restarting the superset service and using back-to-back SSH tunnels to allow my ingestion recipe to contact an-tool1005 port 9080
There is an admin user in the database and I even tried resetting the password for that user, but I couldn't log in.
I then tried an alternative approach, which is to modify the superset plugin to add the X-Remote-User header and set it to btullis
Once again this didn't work. There might be a way, but I would need to experiment a little more.
I can also ask on the DataHub Slack to see if anyone has already tackled this.
Good progress on this now. I have performed a manual ingestion from Superset. We now have metadata about 2,001 charts and 221 dashboards, as well as references to presto sources and lineage information.
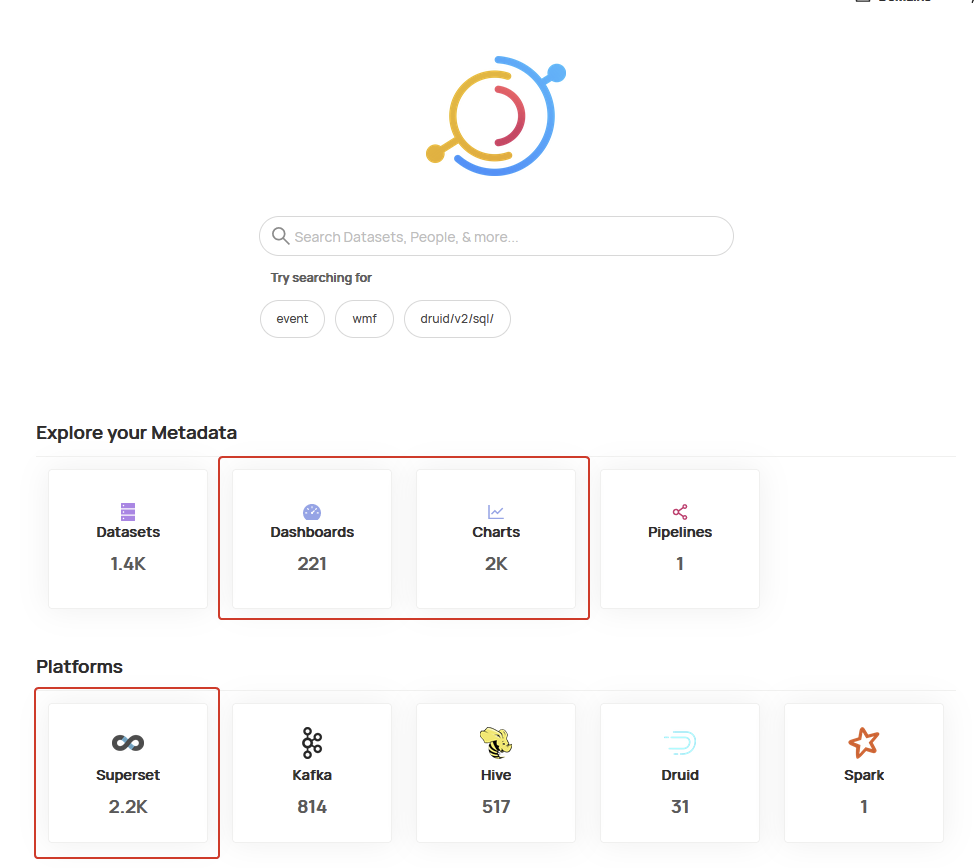
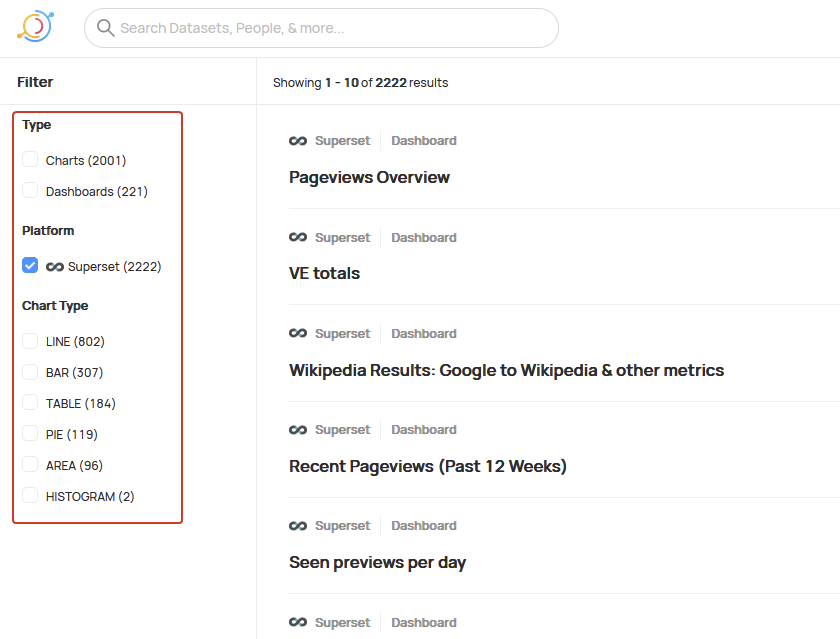
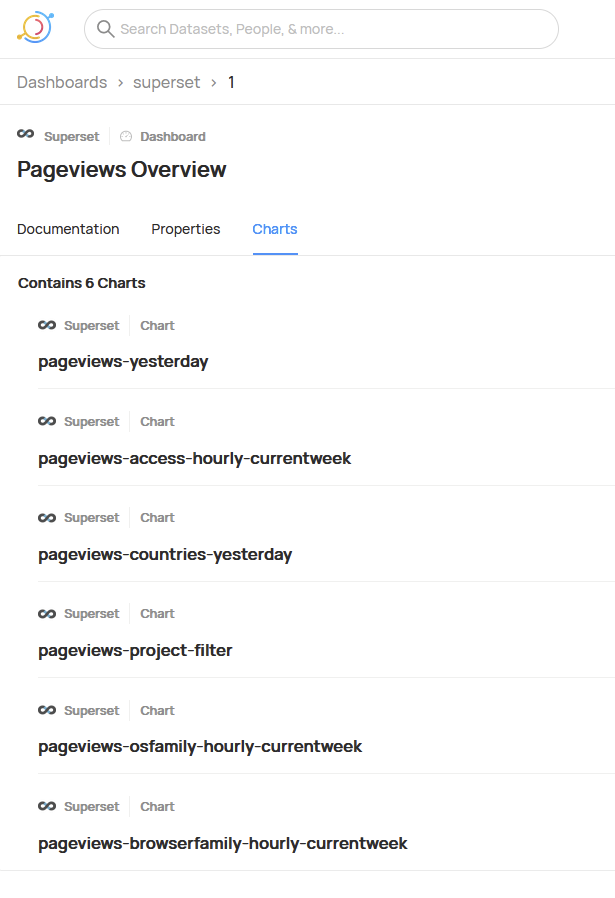
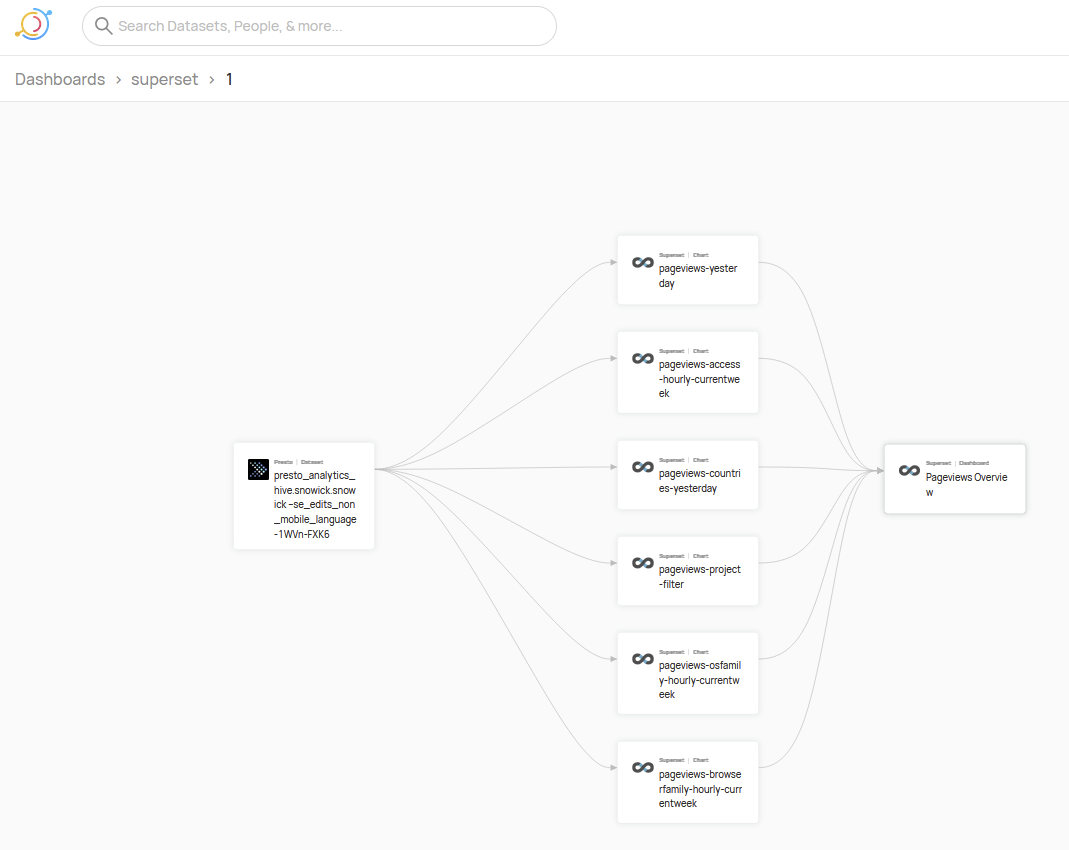
There were a few 400 errors on import, which I will log for analysis.
I will also note the procedure so that we can work out how best to automate it.
The approach I took to carry out the ingestion was this:
This instance of Superset connects to the same database, but uses AUTH_TYPE=AUTH_DB and therefore allows us to connect as the admin user.
The recipe for ingestion was as follows.
source:
type: "superset"
config:
connect_uri: "http://localhost:8088"
username: admin
password: <obtained from private repo /srv/private/hieradata/role/common/analytics_cluster/ui/superset.yaml>
provider: db
sink:
type: "datahub-rest"
config:
server: 'https://datahub-gms.discovery.wmnet:30443'One notable issue with this method is that the View in Superset link doesn't work correctly. It references the connect_uri of http://localhost:8088 instead of https://superset.wikimedia.org - I will work on fixing this.
I have created a paste with the errors that occurred during ingestion: P28592
There were some 500 errors with invalid character sequences, but there were also some 400 errors.
The 400 errors referenced the charts and dashboards that failed to ingest, which include:
Most of these exhibit an error similar to this:
urn:li:dataset:(urn:li:dataPlatform:presto,presto_analytics_hive.blahblah,PROD)" is invalid: Failed to convert urn to entity key: urns parts and key fields do not have same length
From a quick look at it, the common factor seems to be something related to commas somewhere in the metadata, resulting in an invalid urn.
Idea:
What about running a second instance of superset on the same node, accessible only via backend network, but with AUTH_TYPE = AUTH_DB in its superset_config.py? This instance could be used for internal API access only.
Change 812023 had a related patch set uploaded (by Milimetric; author: Milimetric):
[analytics/datahub@wmf] Add base_uri config parameter to Superset source
Thanks, yes I think that this is a possible solution. That might be easier than spinning up a local superset process along with the ingester each time.
I think we will still need the base_uri option that @Milimetric has been working on, because the connect_uri for this private service would be different from https://superset.wikimedia.org
We've decided that we will test the functionality with a manual ingestion run from a stat box - using the patch that @Milimetric has made https://gerrit.wikimedia.org/r/c/812023
If that works, rather than merging it to our fork, we will send a PR upstream to DataHub. The reason for this is that it will be much easier for us to use the python module if DataHub themselves merge it to master and release a new module version to PyPi.
The benefit is that we still have a fully ingested up-to-date Superset with working URLs, but it will be easier for us to do the datahub-cli environment in the Airflow conda-dist environment.
In the meantime, I will work on the deployment of Superset that will be used for the ingestion.
I tried in vain to get this working. Our environment is very painful, I'll explain a bit below.
This is all just too painful. If we're going to develop in these ecosystems we need simple foolproof ways to do it. I think we spend most of our time fighting with stuff like this instead of getting work done.
On stat1008, gradlew fails because it launches a java process and I couldn't find a way to hack it to pass the web proxy through, so it can't build.
With mvwn, I set the usual web proxy env vars, and then pass -Djava.net.useSystemProxies=true. According to https://stackoverflow.com/a/22666646, it looks like this should work for gradle, and if not, you might be able to do JAVA_OPTS=-Djava.net.useSystemProxies=true also?
If we're going to develop in these ecosystems we need simple foolproof ways to do it. I think we spend most of our time fighting with stuff like this instead of getting work done.
You're not wrong, but what you are encountering is I think python env issues. Python is nice to program in but painful in many ways when it comes to deploying and standardizing environments. Think of how much time we've put into conda stuff!
k8s/docker would help, but we have the kerbarrier. The pain we often feel is a consequence of the safety and privacy constraints we put on ourselves for philosophical reasons.
I think that there is an easier way to test this patch, given that we don't need the whole toolchain. We just need to patch the python script that we are using to run the test.
In my case the superset ingestion plugin was installed into my conda environment on stat1008 with the command:
pip install 'acryl-datahub[superset]'
The resulting files are in this directory:
~/.conda/envs/2022-04-14T15.32.43_btullis/lib/python3.7/site-packages/datahub/ingestion/source
I'll go into that directory and take a backup of the superset.py file:
btullis@stat1008:~$ cd ~/.conda/envs/2022-04-14T15.32.43_btullis/lib/python3.7/site-packages/datahub/ingestion/source btullis@stat1008:~/.conda/envs/2022-04-14T15.32.43_btullis/lib/python3.7/site-packages/datahub/ingestion/source$ cp superset.py ~/
Then I can download the patch from gerrit and apply it directly to the superset.py file
curl -s https://gerrit.wikimedia.org/r/changes/analytics%2Fdatahub~812023/revisions/1/patch?download|base64 -d|patch superset.py -
Output from the command looks good:
patching file superset.py
I can diff this against the backup to make sure that it looks right.
(2022-04-14T15.32.43_btullis) btullis@stat1008:~/.conda/envs/2022-04-14T15.32.43_btullis/lib/python3.7/site-packages/datahub/ingestion/source$ diff superset.py ~/superset.py
7c7
< from pydantic.class_validators import validator, root_validator
---
> from pydantic.class_validators import validator
62d61
< base_uri: str = Field(default=None, description="optional URL to use in links (if `connect_uri` is only for ingestion)")
76c75
< @validator("connect_uri", "base_uri")
---
> @validator("connect_uri")
80,85d78
< @root_validator
< def default_base_uri_to_connect_uri(cls, values):
< base = values.get('base_uri')
< if base is None:
< values.set('base_uri', values.get('connect_uri'))
<
218c211
< dashboard_url = f"{self.config.base_uri}{dashboard_data.get('url', '')}"
---
> dashboard_url = f"{self.config.connect_uri}{dashboard_data.get('url', '')}"
290c283
< chart_url = f"{self.config.base_uri}{chart_data.get('url', '')}"
---
> chart_url = f"{self.config.connect_uri}{chart_data.get('url', '')}"Seems legit, so I'm going to try adding the base_uri parameter to my recipe and ingesting again. I wonder if I should delete all previous superset entities first, or try a stateful ingestion?
I have tried a stateful ingestion but it fails validation:
btullis@stat1008:~/src/datahub/ingestion$ datahub ingest -c superset.yml
[2022-07-15 14:16:23,916] INFO {datahub.cli.ingest_cli:99} - DataHub CLI version: 0.8.38
1 validation error for SupersetConfig
stateful_ingestion
extra fields not permitted (type=value_error.extra)The recipe looked like this:
btullis@stat1008:~/src/datahub/ingestion$ cat superset.yml | grep -v password
source:
type: "superset"
config:
connect_uri: "http://localhost:8088"
base_uri: "https://superset.wikimedia.org"
username: admin
provider: db
stateful_ingestion:
enabled: True
remove_stale_metadata: True
sink:
type: "datahub-rest"
config:
server: 'https://datahub-gms.discovery.wmnet:30443'I will try deleting the superset data and ingesting again.
Deleted the entities associated with superset.
(2022-04-14T15.32.43_btullis) btullis@stat1008:~/src/datahub/ingestion$ datahub delete --entity_type dashboard --platform superset --hard
This will permanently delete data from DataHub. Do you want to continue? [y/N]: y
[2022-07-15 14:19:58,653] INFO {datahub.cli.delete_cli:234} - datahub configured with https://datahub-gms.discovery.wmnet:30443
[2022-07-15 14:19:58,756] INFO {datahub.cli.delete_cli:248} - Filter matched 221 entities. Sample: ['urn:li:dashboard:(superset,32)', 'urn:li:dashboard:(superset,276)', 'urn:li:dashboard:(superset,270)', 'urn:li:dashboard:(superset,115)', 'urn:li:dashboard:(superset,190)']
This will delete 221 entities. Are you sure? [y/N]: y
100% (221 of 221) |#######################################################################################################################################################| Elapsed Time: 0:00:03 Time: 0:00:03
Took 11.786 seconds to hard delete 884 rows for 221 entities
(2022-04-14T15.32.43_btullis) btullis@stat1008:~/src/datahub/ingestion$ datahub delete --entity_type chart --platform superset --hard
This will permanently delete data from DataHub. Do you want to continue? [y/N]: y
[2022-07-15 14:20:17,714] INFO {datahub.cli.delete_cli:234} - datahub configured with https://datahub-gms.discovery.wmnet:30443
[2022-07-15 14:20:18,062] INFO {datahub.cli.delete_cli:248} - Filter matched 2001 entities. Sample: ['urn:li:chart:(superset,1206)', 'urn:li:chart:(superset,945)', 'urn:li:chart:(superset,1171)', 'urn:li:chart:(superset,1550)', 'urn:li:chart:(superset,1502)']
This will delete 2001 entities. Are you sure? [y/N]: y
100% (2001 of 2001) |#####################################################################################################################################################| Elapsed Time: 0:00:32 Time: 0:00:32
Took 38.028 seconds to hard delete 8004 rows for 2001 entitiesLooking good. After one small modification to the patch (https://gerrit.wikimedia.org/r/c/analytics/datahub/+/812023/2..1) the ingestion worked and the link to Superset is working.
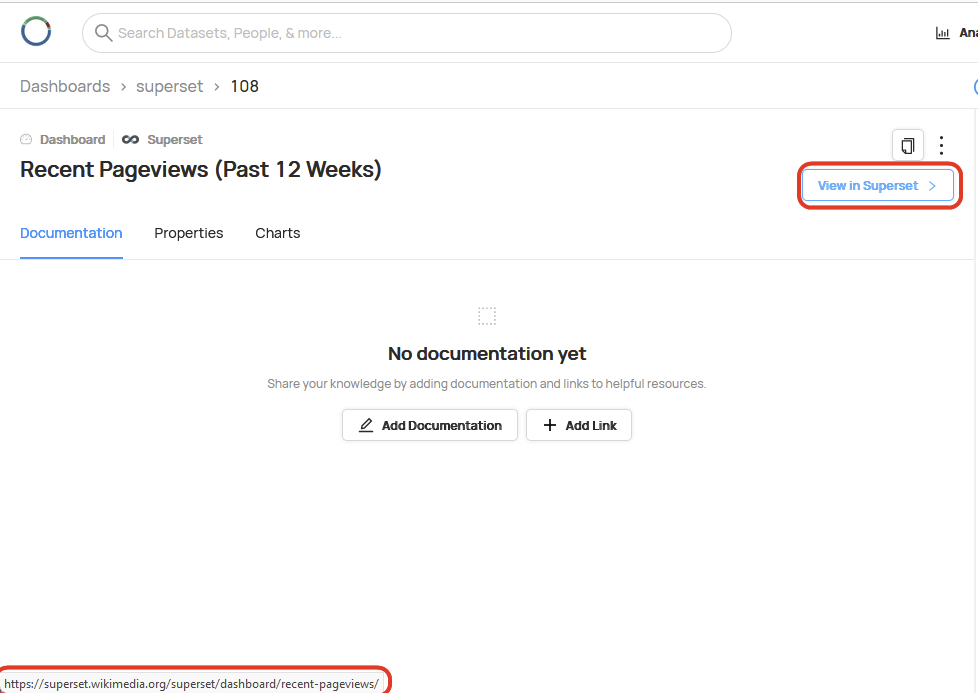
I think that this is good enough to call our MVP integration done, but we know that we still want to productionize this and schedule it.
@Milimetric is going to upstream the patch to DataHub. I'll create a follow-up ticket to work on the puppet code to run an instance of Superset specifically for this ingestion.
Change 812023 abandoned by Milimetric:
[analytics/datahub@wmf] Add base_uri config parameter to Superset source
Reason:
upstreamed instead