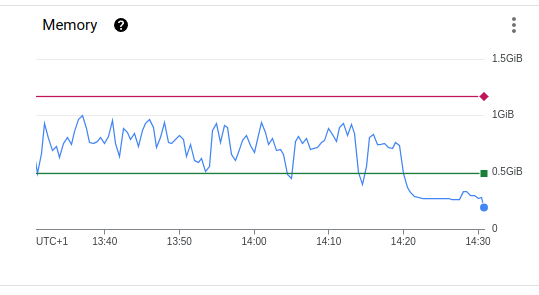
Not sure whats happening but it's reporting OOMkilling something and that's usually not good.
None of the pods report being restarted so doesn't make much sense to me.
logs: https://cloudlogging.app.goo.gl/rZu695w2NRjEEDPc7
kubectl describe node gke-wbaas-3-medium-pool-f591592a-k67c Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 689m (73%) 2060m (219%) memory 1367Mi (48%) 3341Mi (118%) ephemeral-storage 0 (0%) 0 (0%) hugepages-1Gi 0 (0%) 0 (0%) hugepages-2Mi 0 (0%) 0 (0%) attachable-volumes-gce-pd 0 0 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning OOMKilling 47m kernel-monitor Memory cgroup out of memory: Killed process 541912 (apache2) total-vm:458228kB, anon-rss:141820kB, file-rss:15828kB, shmem-rss:45480kB, UID:33 pgtables:552kB oom_score_adj:937 Warning OOMKilling 44m kernel-monitor Memory cgroup out of memory: Killed process 542334 (apache2) total-vm:471132kB, anon-rss:154468kB, file-rss:16636kB, shmem-rss:49848kB, UID:33 pgtables:584kB oom_score_adj:937 Warning OOMKilling 15m kernel-monitor Memory cgroup out of memory: Killed process 542296 (apache2) total-vm:462364kB, anon-rss:146204kB, file-rss:13684kB, shmem-rss:42372kB, UID:33 pgtables:528kB oom_score_adj:937 Warning OOMKilling 10m kernel-monitor Memory cgroup out of memory: Killed process 557837 (apache2) total-vm:460160kB, anon-rss:142572kB, file-rss:15704kB, shmem-rss:43632kB, UID:33 pgtables:560kB oom_score_adj:937