In Special:NewLexemeAlpha's example, I find it confusing that the language code (en) and the language (English) are on different lines. 'cat' (L7) is a quite complete Lexeme about a nice entity, but also a very short word that looks like a language code, which doesn't help solve the confusion.
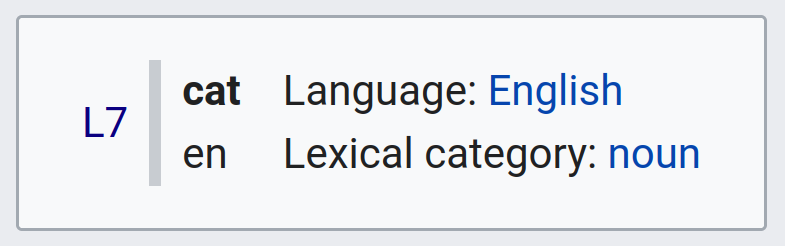
Something similar happens when applying uselang=fr (or other language codes):
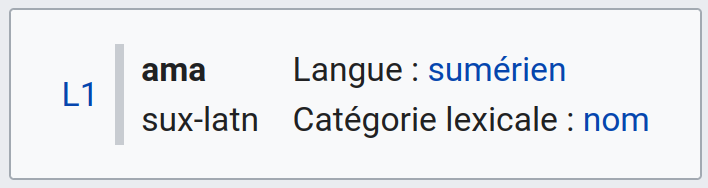
Suggestions: swap "Language" and "Lexical category"; rethink the layout; use a Lexeme on a word widely recognized as such but with more characters