This task will track the racking, setup, and OS installation of kafka-stretch200[12]
Hostname / Racking / Installation Details
Hostnames: kafka-stretch200[12]
Racking Proposal: In different rows please.
Networking Setup:
- # of Connections: 1
- Speed: 10G.
- Vlan: Private
- AAAA records:Y,
- Additional IP records: no
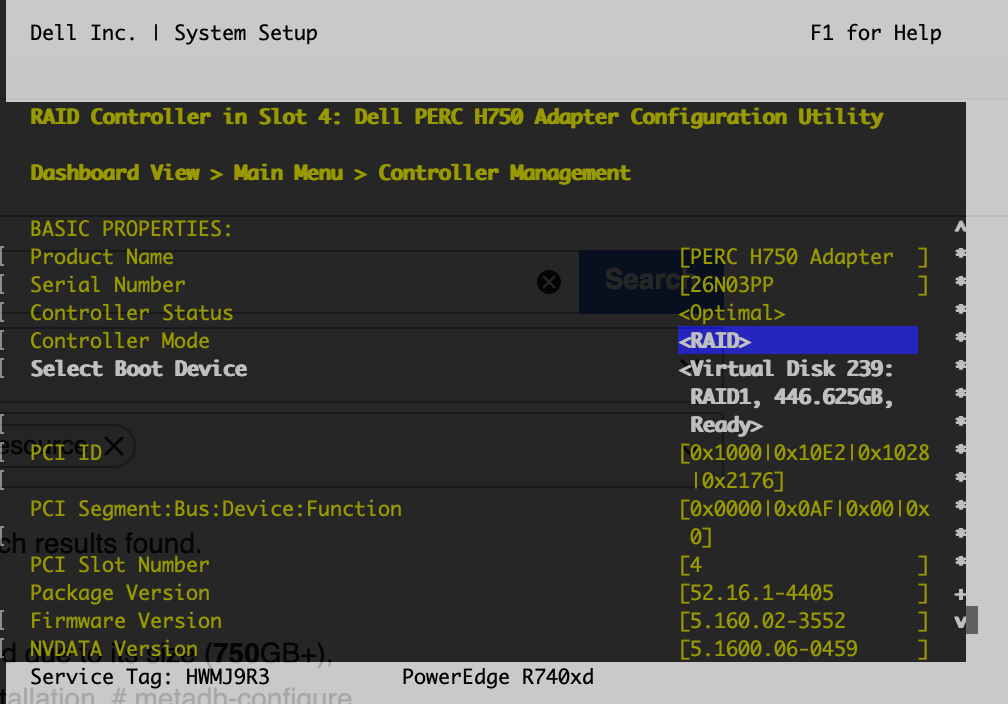
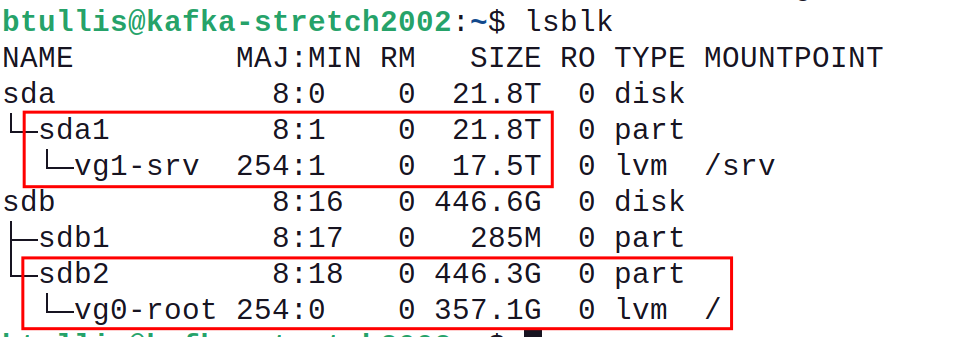
Partitioning/Raid: Same as kafka-jumbo1009
OS Distro: Bullseye
Sub-team Technical Contact: @Ottomata and @BTullis
Per host setup checklist
Each host should have its own setup checklist copied and pasted into the list below.
kafka-stretch2001:
- - receive in system on procurement task T311864 & in coupa
- - rack system with proposed racking plan (see above) & update netbox (include all system info plus location, state of planned)
- - add mgmt dns (asset tag and hostname) and production dns entries in netbox, run cookbook sre.dns.netbox.
- - network port setup via netbox, run homer from an active cumin host to commit
- - bios/drac/serial setup/testing, see Lifecycle Steps & Automatic BIOS setup details
- - firmware update (idrac, bios, network, raid controller)
- - operations/puppet update - this should include updates to netboot.pp, and site.pp role(insetup) or cp systems use role(insetup::nofirm).
- - OS installation & initital puppet run via sre.hosts.reimage cookbook.
kafka-stretch2002:
- - receive in system on procurement task T311864 & in coupa
- - rack system with proposed racking plan (see above) & update netbox (include all system info plus location, state of planned)
- - add mgmt dns (asset tag and hostname) and production dns entries in netbox, run cookbook sre.dns.netbox.
- - network port setup via netbox, run homer from an active cumin host to commit
- - bios/drac/serial setup/testing, see Lifecycle Steps & Automatic BIOS setup details
- - firmware update (idrac, bios, network, raid controller)
- - operations/puppet update - this should include updates to netboot.pp, and site.pp role(insetup) or cp systems use role(insetup::nofirm).
- - OS installation & initital puppet run via sre.hosts.reimage cookbook.