Prior work:
- T254634: Determine and implement multi-dc strategy for ChronologyProtector
- T279664: Progressive Multi-DC roll out
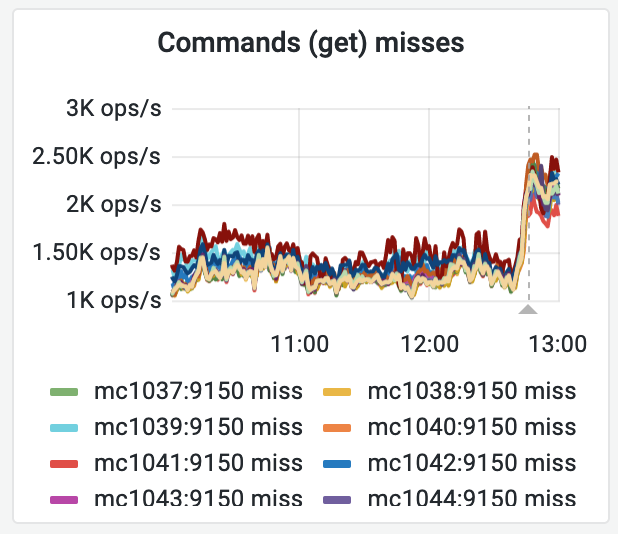
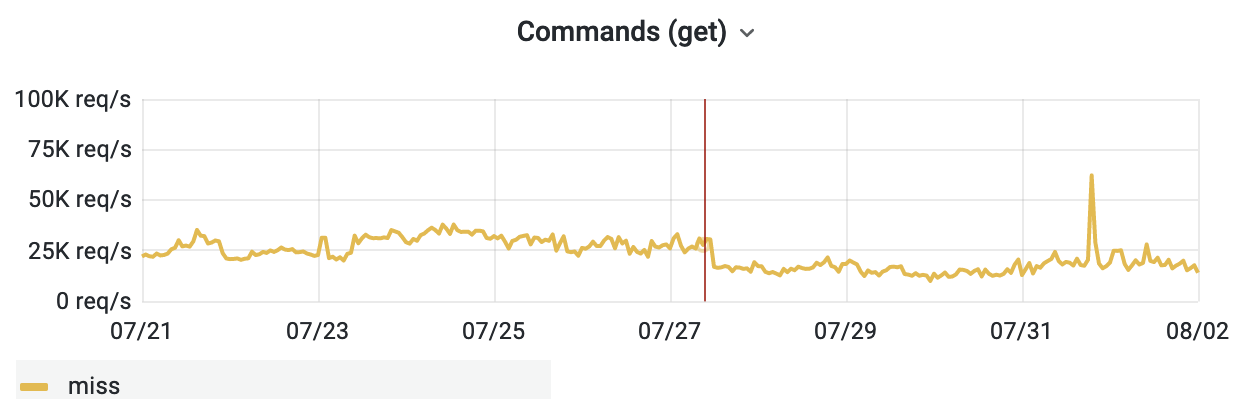
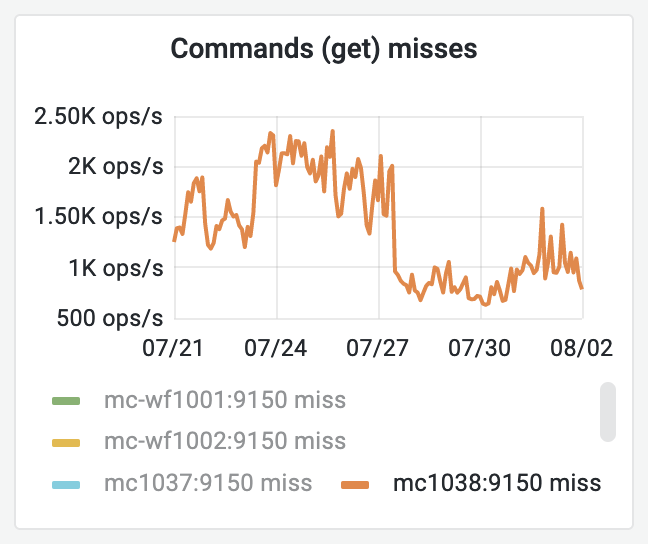
This inefficiency was identified by @tstarling during T279664 to assess why a synthetic page view was slower in Codfw than Eqiad. While CP was not the cause, it did come up as one of the things we do on each page view, and this seems wrong.
Background
As part of my analysis with @aaron at T254634, we arrived on a simplified roll-out plan for Multi-DC. For ChronologyProtector this was mainly that we dropped support for always-on stateless ChronologyProtector. This was effectively done in 2020 already, but summarised below:
Drop support for protecting chronology for cross-domain redirects where we can neither set a cookie nor a query parameter (except login.wikimedia.org, ref T91820).
We were unable to find real-world examples of this scenario. That is, as scenario where a user 1) performs database write in the primary DC but not a POST request with sticky-dc cookie, or with such stickiness but being followed by a cross-domain request and 2) the next secondary DC request happens mechanically or otherwise in really rapid manner and 3) is unable to receive a query parameter and 4) has a hard requirement to see the prior db write in this subsequent request.
Basically, our other measures have obsoleted this:
- sticky-dc cookie after POST requests and other DB writes.
- loginwiki routing, ref T91820.
- token store, ref T278392.
What remains
Much of the related code for this was all removed (including the requirement to replicate the temporary position value across DCs and to first wait-for the position store and then wait-for MySQL replication, and WaitConditionLoop-based BagOStuff callback for OutputPage).
However what we forgot, is that we still generate a clientId when LBFactory instantiates the ChronologyProtector class, and there's nothing in place to prevent it from seeing that as instruction to check the position store and wait for something that doesn't exist.