We're planning on adding at least 50 new users to Wikibase.cloud, possibly 67, with the ability to create a total of 6 Wiki's per user. We've worked towards implementing several dashboards with metrics to keep an eye on during the onboarding of these users.
To make sure we're ready, we want to park time to double check if the metrics/monitoring/alerts are complete. Some ideas:
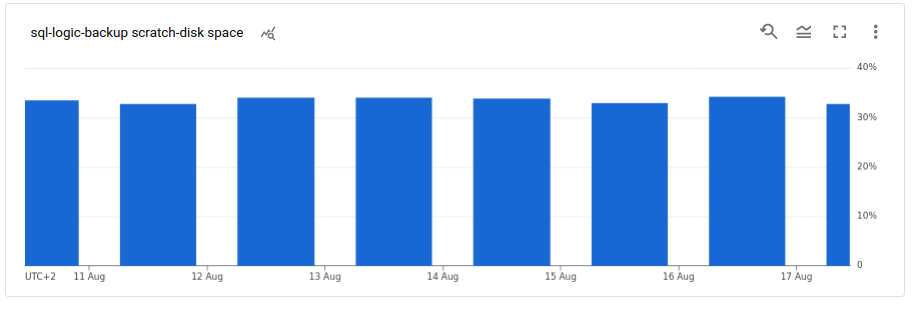
- Potentially add alerting on sql-logic-backup scratch disk space or bumping it up before the new users start signing up
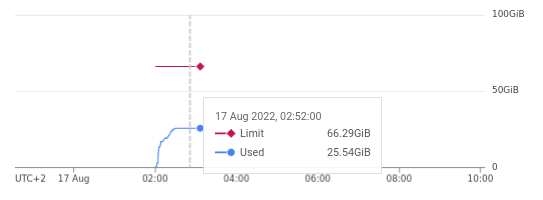
- We only have one replica for mariadb secondary, and are running out of space here, so this might need bumping up
- Do we need metrics that give us a better idea of how the cache is used?
- Review the incident list from the migration and see if this is all covered in monitoring or in a good place to keep an eye on
Link to existing dashboard: https://console.cloud.google.com/monitoring/dashboards/builder/fd1bf4b9-3b5b-4cd0-9529-3f1f75c3bdbd?project=wikibase-cloud&dashboardBuilderState=%257B%2522editModeEnabled%2522:false%257D&timeDomain=6h
AC:
- Everyone has reviewed this ticket and added their thoughts
- Deniz
- Dat
- Rosalie
- Tobias
- Tom
- We can conclude if monitoring and alerting is sufficient for onboarding >50 new users
- We can confidently send out all the invite codes at once