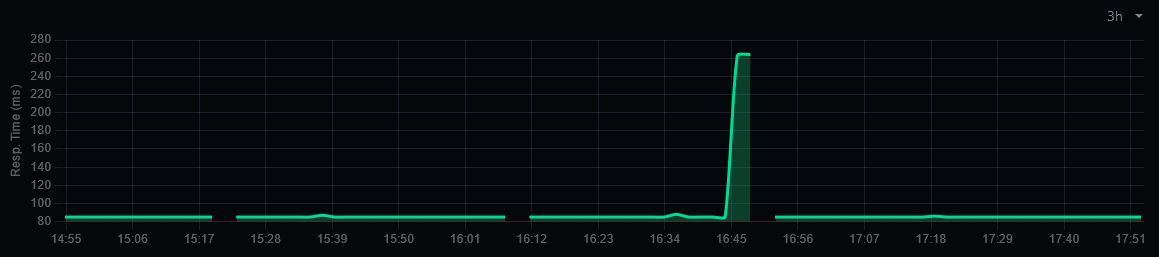
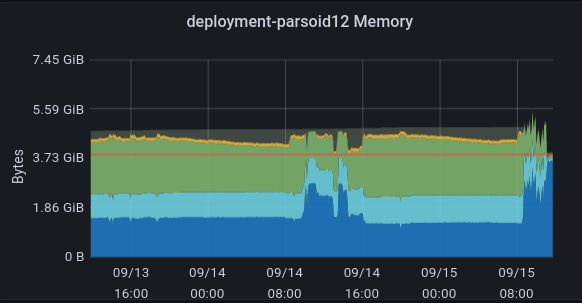
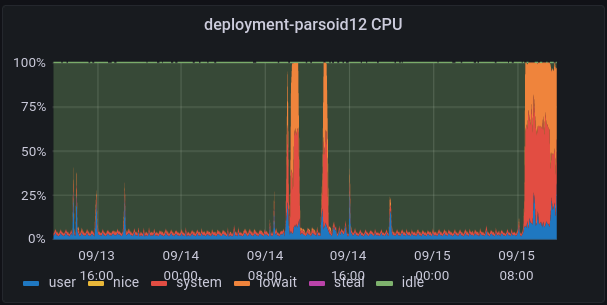
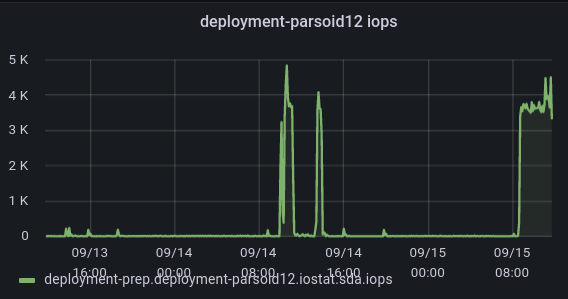
https://integration.wikimedia.org/ci/view/Beta/job/beta-scap-sync-world/68528/console
['/usr/bin/scap', 'pull', '--no-php-restart', '--no-update-l10n', '--exclude-wikiversions.php', 'deployment-deploy03.deployment-prep.eqiad1.wikimedia.cloud'] (ran as mwdeploy@deployment-parsoid12.deployment-prep.eqiad1.wikimedia.cloud) returned [255]: Connection to 172.16.4.125 port 22 timed out