Background/Goal
Build a poll based ingestion that iterates over declared streams in event stream config, looks up the schemas for the streams, and then posts the updates to datahub.
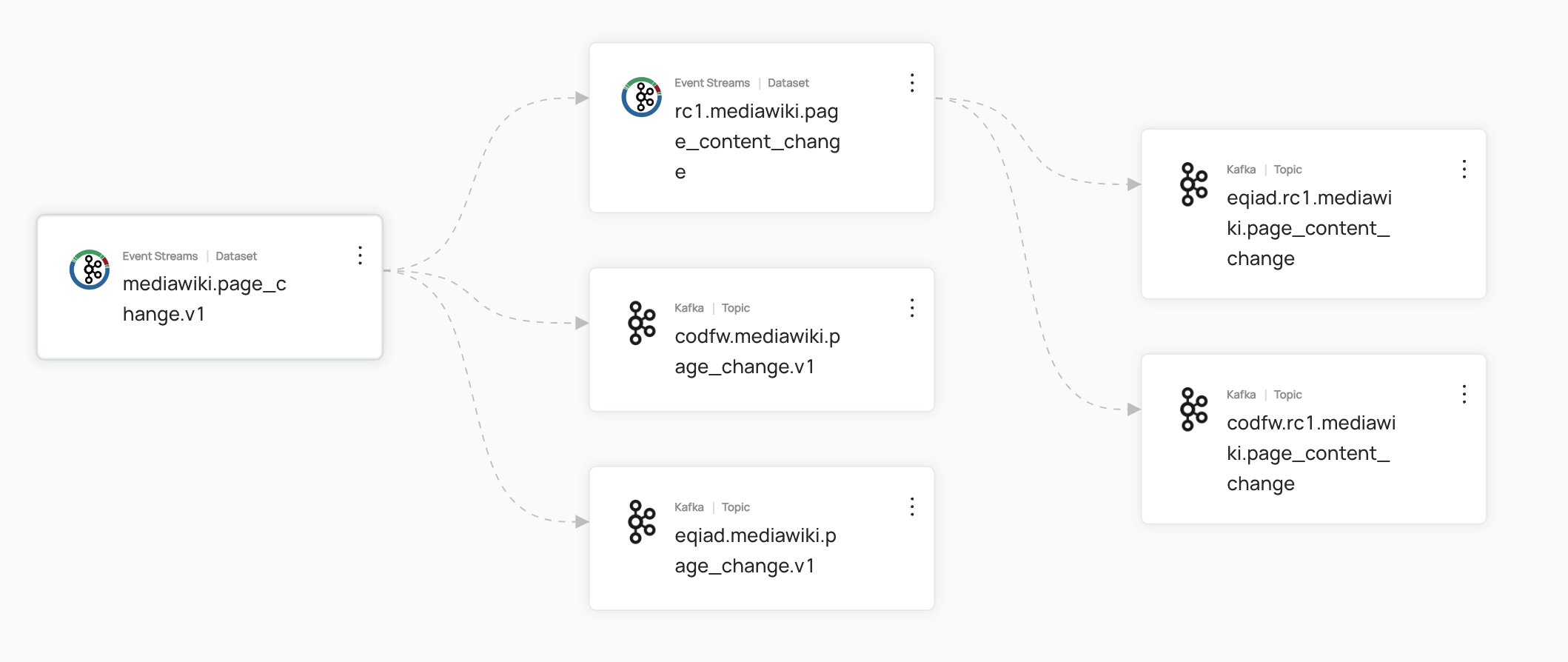
Ideally, datahub would represent these as 'stream' datasets, not just Kafka topics, as a 'stream' is made up of multiple kafka topics. In the interim, we may want to just use Datahub's built in support for Kafka topics and post updates to kafka topic schemas.
We have a Java library that automates interacting with EventStreamConfig and schema repositories to make it easier to iterate through declared streams and look up schemas. We could use this java library to do this, or alternatively write Event Platform utility library code in another language (python?).
There are two types of datahub ingestion, poll based and event based. Thus far, we have not been using event based ingestion. While event based ingestion would be much nicer, implementing metadata events of changes to Event Platform streams and schemas might be difficult. To do this, we'd need to emit events anytime EventStreamConfig is deployed, which would somehow have to be linked to MediaWiki config deployments.
User Story
As an event platform engineer, I need to keep DataHub up to date with new and existing event streams and schemas
Key Tasks/Dependencies
- Add Event Stream custom platform to DataHub
- Deploy the metadata ingestion pipeline for the event stream schemas
- Link the corresponding topics and downstream datasets to the stream (TBD via lineage and/or metadata replication. This falls into the larger consideration on how to propagate metadata between equivalent datasets stored across different platforms and refinements.)
Acceptance Criteria
- A custom platform called Event Streams is listed in DataHub
- The Event Streams data hub lists all the event stream data assets
- All the schema elements are documented
- Top level schema description is imported as the top level dataset documentation