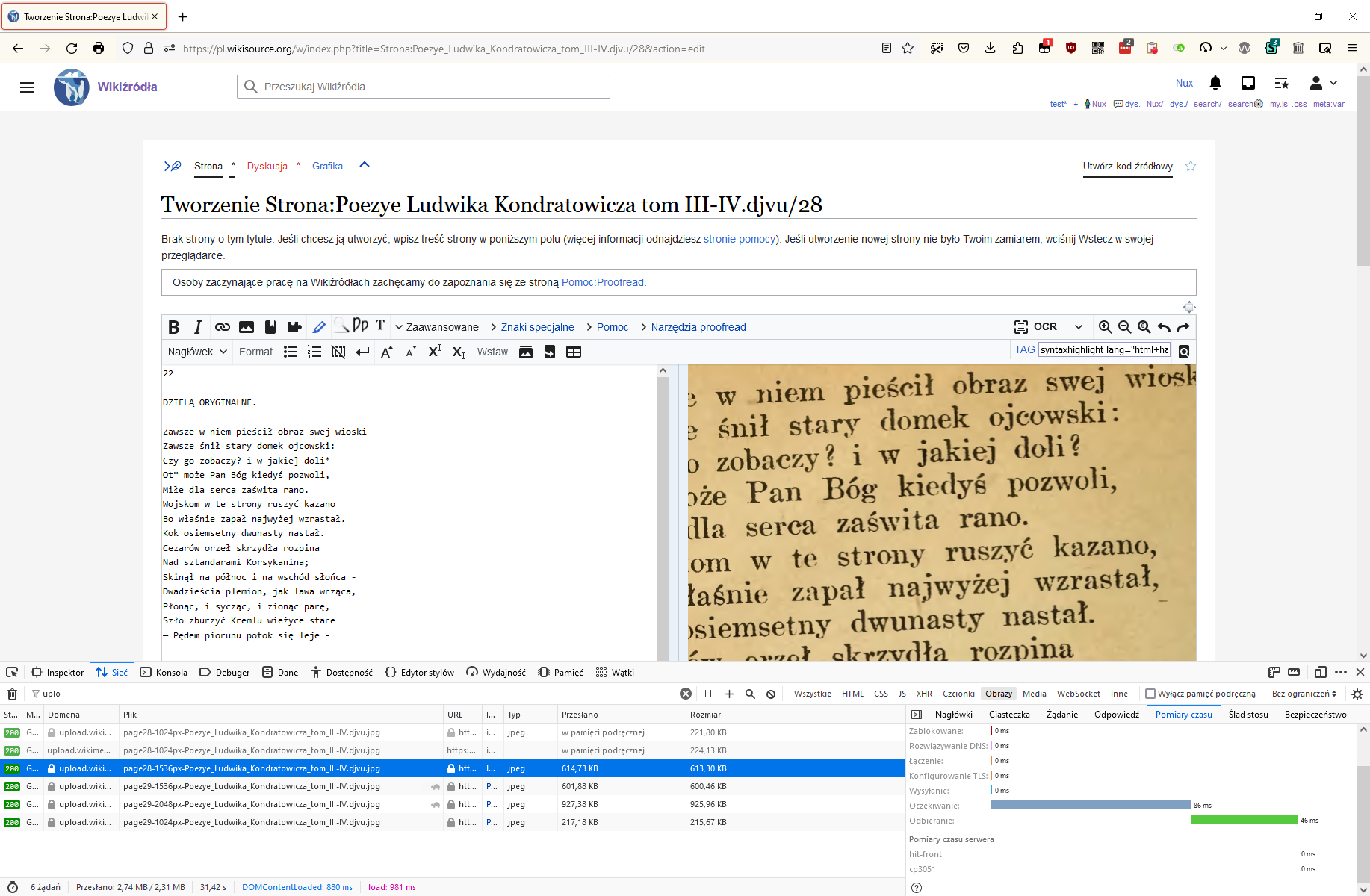
Steps to replicate the issue (include links if applicable):
- Edit this page: https://pl.wikisource.org/w/index.php?title=Strona:Ibanez_-_Czterech_Je%C5%BAd%C5%BAc%C3%B3w_Apokalipsy_01.djvu/072&action=edit
- Note urls for the .prp-page-image img
- Edit this page: https://pl.wikisource.org/w/index.php?title=Strona:Ibanez_-_Czterech_Je%C5%BAd%C5%BAc%C3%B3w_Apokalipsy_01.djvu/074&action=edit
- Note urls for the .prp-page-image img
What happens?:
Images semi-randomly gets different set of images:
[ "page72-871px", "page72-1306px", "page72-1742px" ]
[ "page74-871px", "page74-1307px", "page74-1742px" ]
Note 1px difference in 1.5x image. This is problematic because preload mechanism (T230689) depends on previous images to have same size as previous one.
I think the code responsible for this is here (this generates images):
https://doc.wikimedia.org/mediawiki-core/master/php/Linker_8php_source.html#l00791
But I think it might be resolved by making sure base width is even. So it could resolved here I think: PageDisplayHandler::getImageTransform(). Honestly that is a bit of a shoot in the dark. Would probably need to debug the getImageTransform function (in a real-ish environment).
What should have happened instead?:
I would assume all images in one Index should have same px in each scale.
Software version (skip for WMF-hosted wikis like Wikipedia): -
Other information (browser name/version, screenshots, etc.):
Firefox 105.0.3