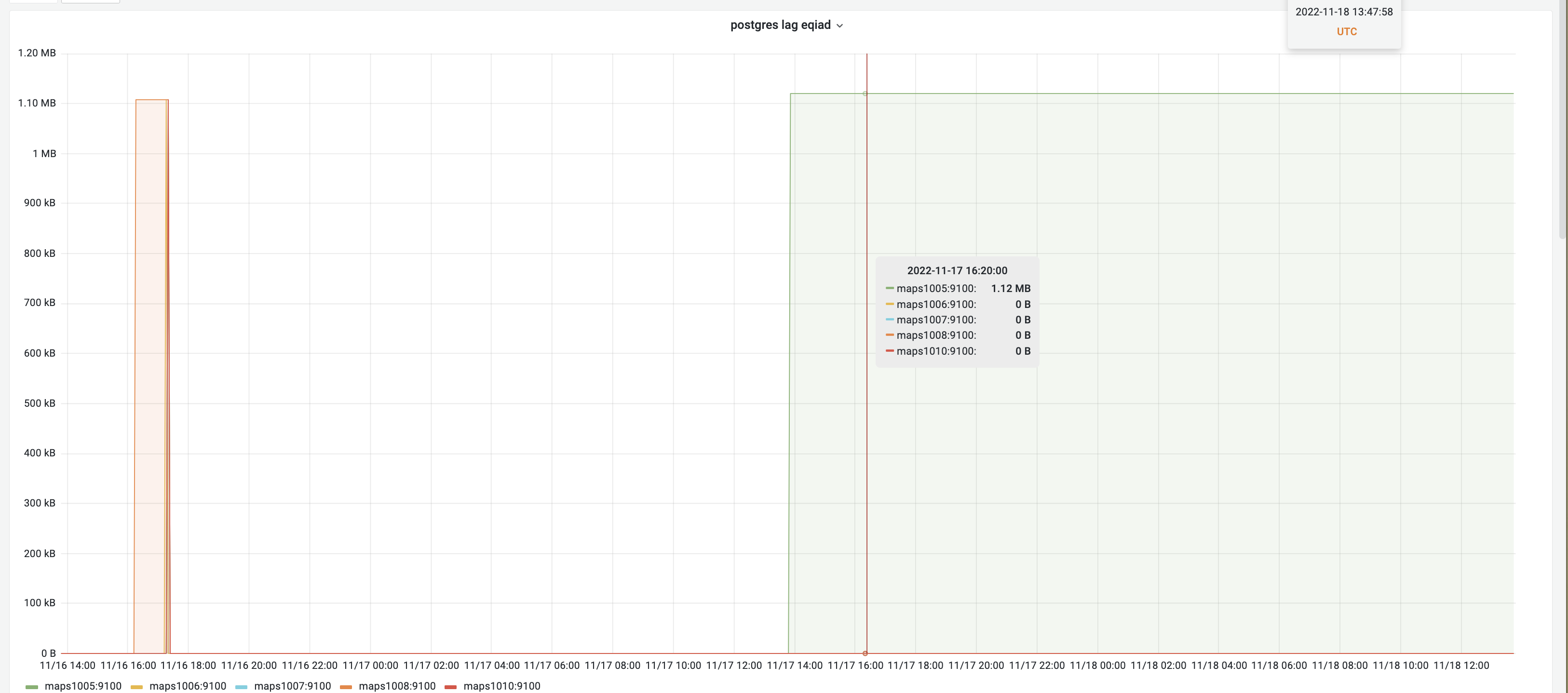
The current theory is that the primary postgres database which is regularly updated with openstreetmap data is failing to replicate down to the secondary postgres servers. The database cluster is using streaming replication to mirror data from the primary to the read-only replicas, and that replication is getting out of sync. This makes it impossible for the replica to receive any subsequent updates, until a manual, full sync is done.
The effect we see is that some postgres replica nodes within a data center will have out-of-date shapes, while other nodes are current. The lag measured in bytes shows that 3 out of 5 nodes in codfw are more than 4TB behind: https://grafana.wikimedia.org/d/000000305/maps-performances?orgId=1&viewPanel=16
- Ensure that we have an up-to-date diagram of database instances for the kartotherian cluster and how they're related (here).
- Try to validate our assumptions.
- Identify what is breaking the sync.
- Try to find ways to make the setup more robust T290149
Background:
https://www.cybertec-postgresql.com/en/streaming-replication-conflicts-in-postgresql/