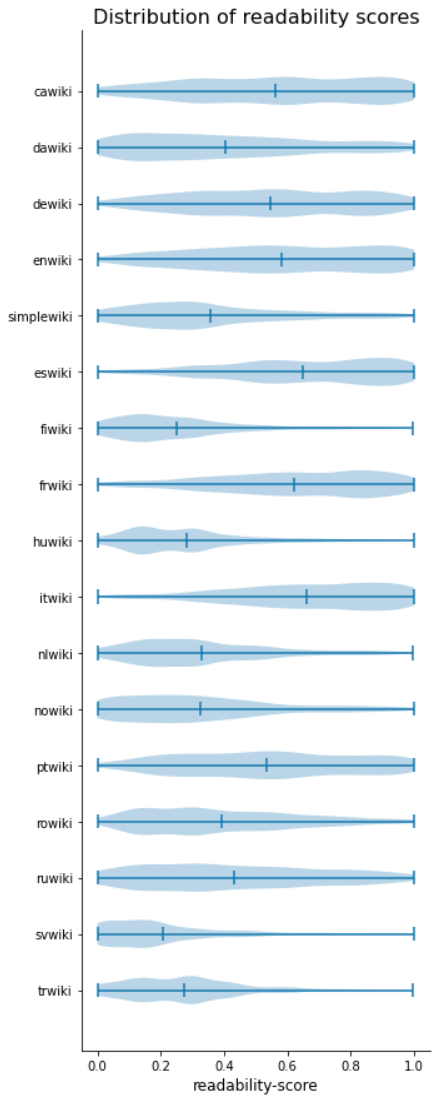
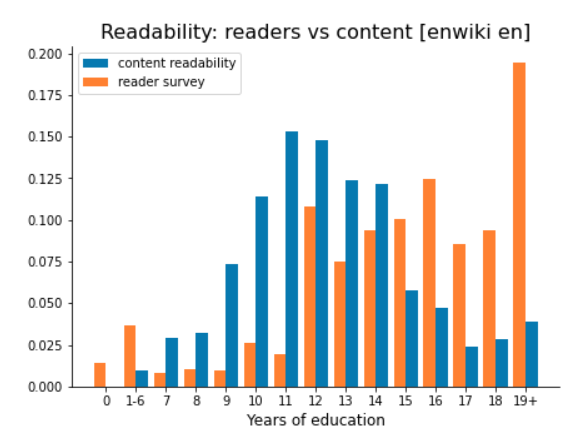
We developed and evaluated a language-agnostic model to assign readability scores to Wikipedia articles in T299091.
Here, we want to run a bulk analysis of readability scores for all articles in the supported Wikipedias. The aim is to understand the variation in readability within and across wikis.