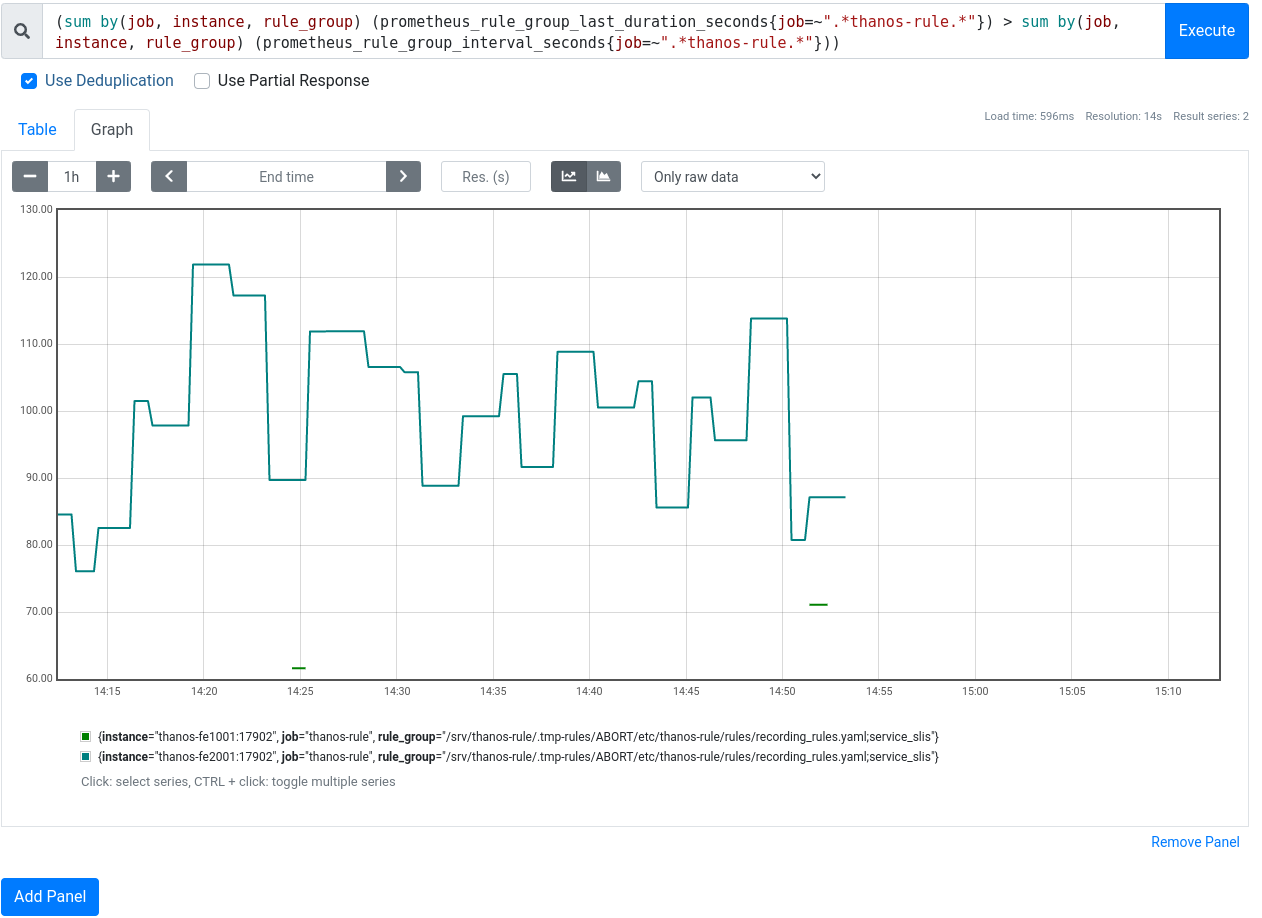
With the sli recording rules added as part of T323064: Create WDQS Uptime SLO dashboard in Grizzly we're pushing the threshold were evaluating a rule (group) takes longer than the evaluation interval (60s) leading to alerts:
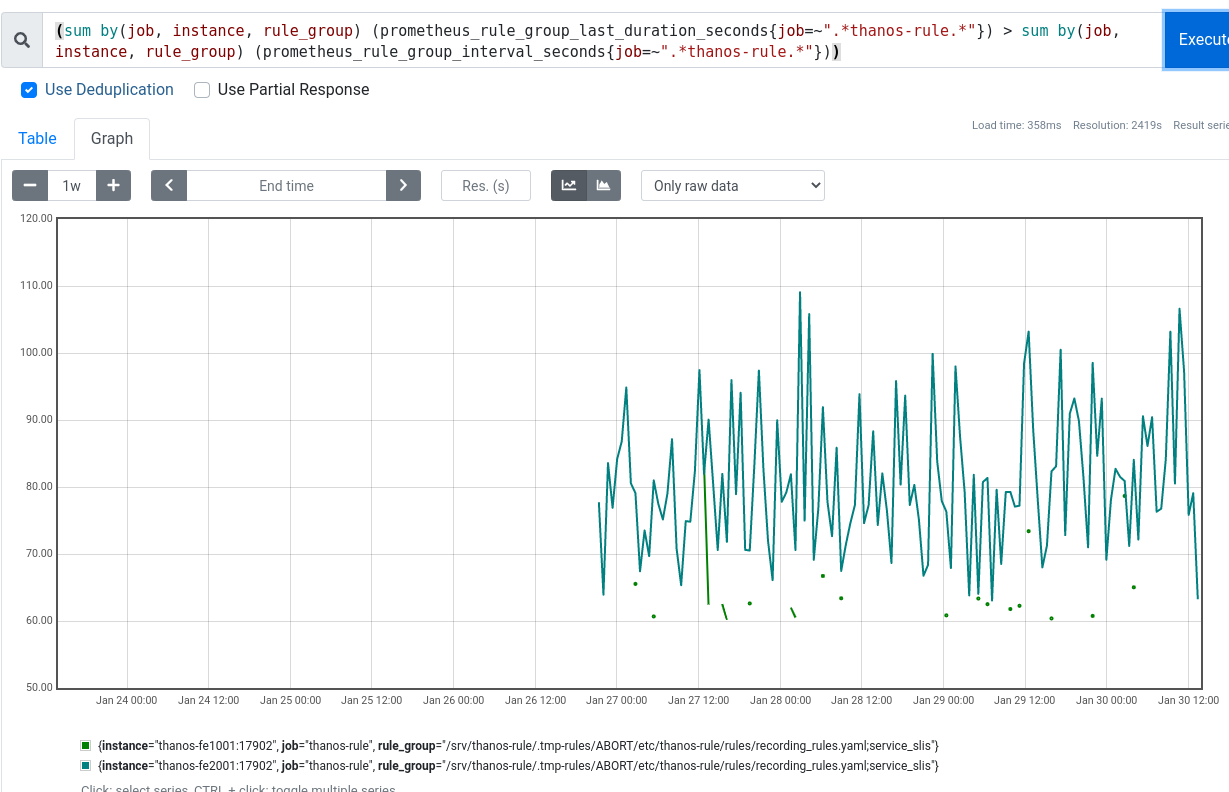
AFAICT this is due to the fact that trafficserver_backend_requests_seconds_count is a "big" metric (broken down by single cache host for example) and thus takes a while to query across the infra, even more so when asking 90/91/92 days of history.
In total rule evaluation for service_slis group jumped from <10s to >60s (i.e. not being able to keep up with evaluation interval)
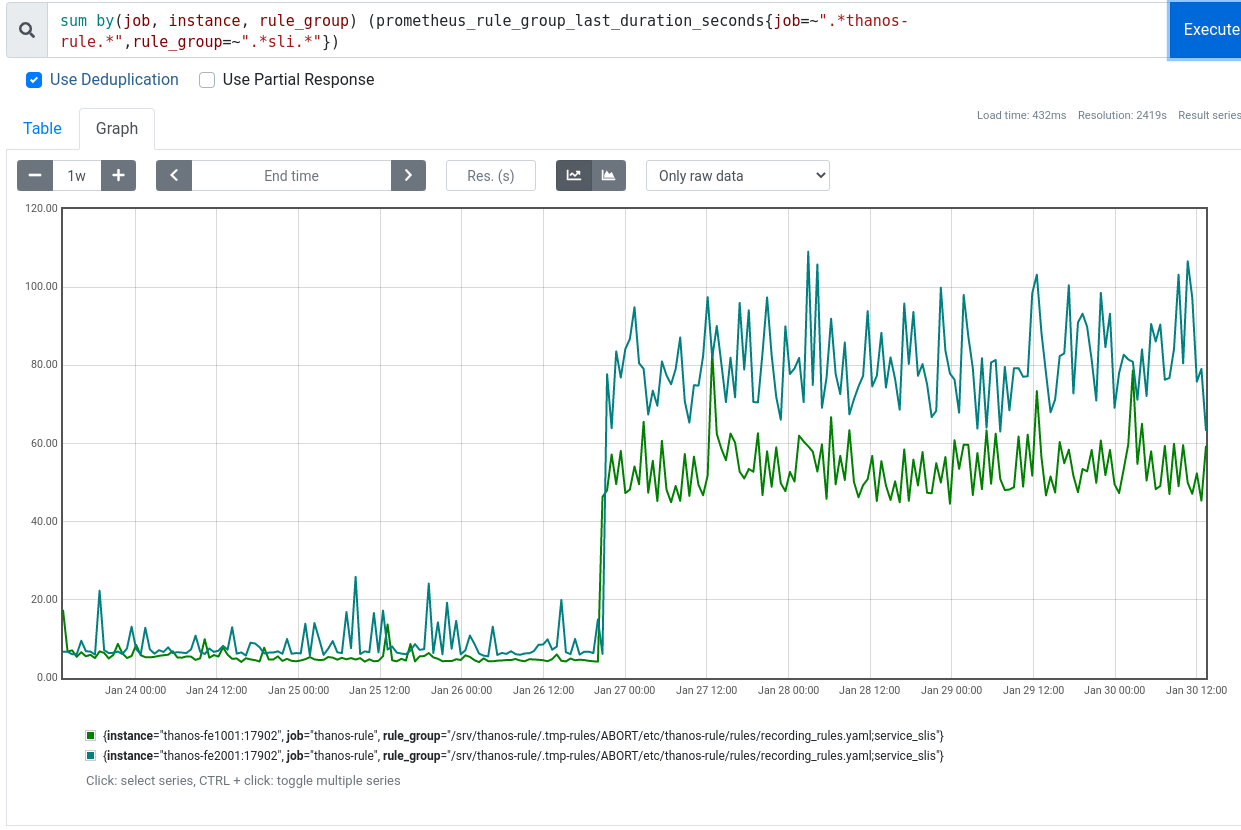
In terms of solutions/mitigations we can:
- in the short term isolate the wdqs sli into their own rule group
- also in the short term increase the evaluation interval of said group to evaluate every 3-4 minutes
- medium term, evaluate (hah!) if we can reformulate these rules in terms of lower-cardinality and pre-aggregated rules for example in modules/profile/files/prometheus/rules_ops.yml for per-backend ATS availability we have:
- record: job_backend:trafficserver_backend_requests:avail5m
expr: sum by(backend, job) (job_method_status_backend_layer:trafficserver_backend_requests_seconds_count:rate5m{status=~"5.."})
/ sum by(backend, job) (job_method_status_backend_layer:trafficserver_backend_requests_seconds_count:rate5m{status=~"[12345].."})