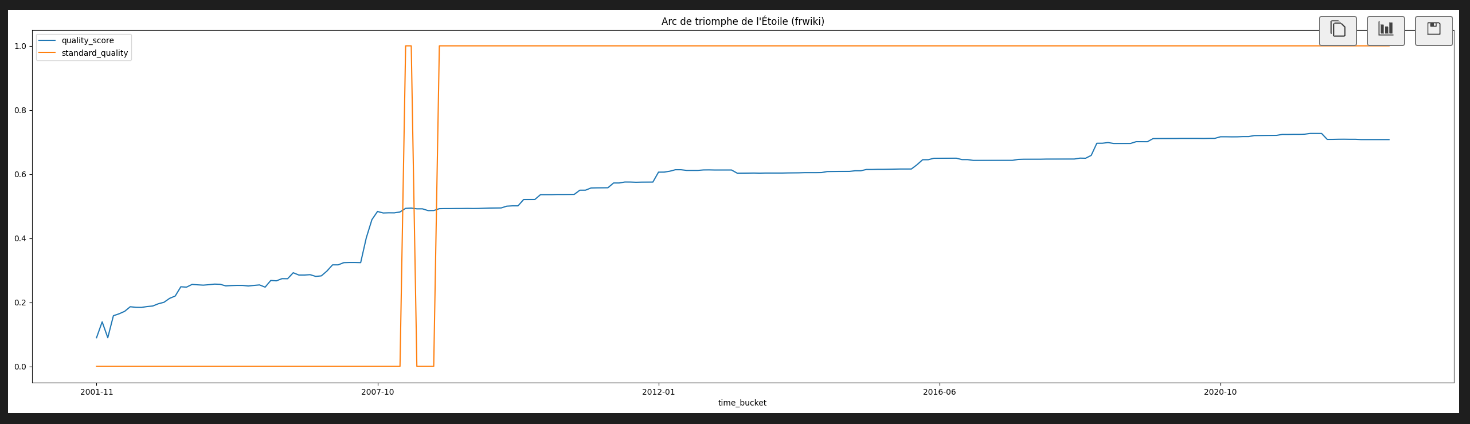
Improve the current quality score metric by:
- Aggregating revision quality per month by just considering the quality of the last revision of the month
- Adding another metric view with the % of articles in a group that are above a certain threshold:
> 0.36 (Stub+); > 0.54 (C+) > 0.65 (B+) > 0.78 (GA+) > 0.88 (FA)
Thresholds obtained as follows: the upper limit of each quality class is the median predicted quality score of revisions corresponding to such class as labeled by editors.