The secondary DB falls over every 3-4days; it also generally seem to do this around midnight UTC which is annoyingly around the time our backups run. Users probably see this as a bit of downtime; for us it's annoying because we see failed backup jobs.
Determined as an outcome of T328923 / T333669
Evidence of this happening:
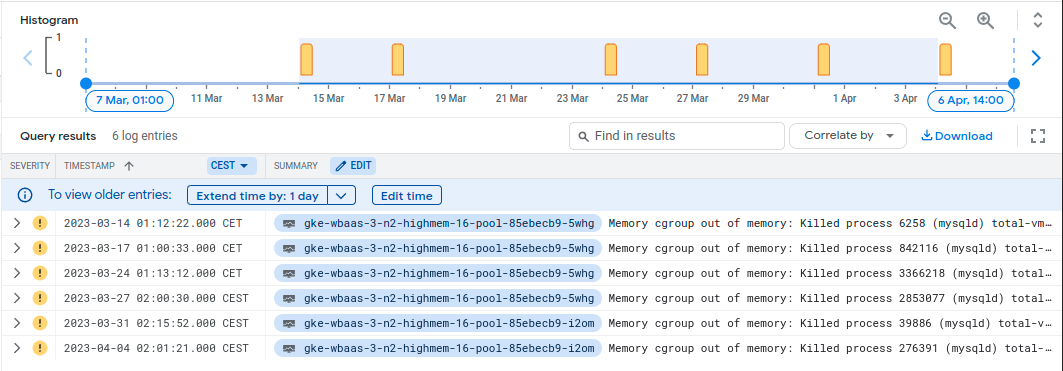
{
"insertId": "1m02krng1vag3u7",
"jsonPayload": {
"source": {
"component": "kernel-monitor",
"host": "gke-wbaas-3-n2-highmem-16-pool-85ebecb9-i2om"
},
"reason": "OOMKilling",
"type": "Warning",
"message": "Memory cgroup out of memory: Killed process 276391 (mysqld) total-vm:11713196kB, anon-rss:4304992kB, file-rss:22508kB, shmem-rss:0kB, UID:1001 pgtables:9204kB oom_score_adj:969",
"kind": "Event",
"lastTimestamp": "2023-04-04T00:01:21Z",
"reportingComponent": "",
"eventTime": null,
"apiVersion": "v1",
"reportingInstance": "",
"involvedObject": {
"kind": "Node",
"name": "gke-wbaas-3-n2-highmem-16-pool-85ebecb9-i2om",
"uid": "gke-wbaas-3-n2-highmem-16-pool-85ebecb9-i2om"
},
"metadata": {
"resourceVersion": "3730507",
"creationTimestamp": "2023-04-04T00:01:22Z",
"namespace": "default",
"managedFields": [
{
"manager": "node-problem-detector",
"fieldsV1": {
"f:firstTimestamp": {},
"f:message": {},
"f:lastTimestamp": {},
"f:involvedObject": {},
"f:type": {},
"f:reason": {},
"f:count": {},
"f:source": {
"f:component": {},
"f:host": {}
}
},
"operation": "Update",
"apiVersion": "v1",
"time": "2023-04-04T00:01:22Z",
"fieldsType": "FieldsV1"
}
],
"uid": "30ebf589-f148-48b2-a1f5-ce94cf37df09",
"name": "gke-wbaas-3-n2-highmem-16-pool-85ebecb9-i2om.1752924fb2d6c4ee"
}
},
"resource": {
"type": "k8s_node",
"labels": {
"node_name": "gke-wbaas-3-n2-highmem-16-pool-85ebecb9-i2om",
"location": "europe-west3-a",
"cluster_name": "wbaas-3",
"project_id": "wikibase-cloud"
}
},
"timestamp": "2023-04-04T00:01:21Z",
"severity": "WARNING",
"logName": "projects/wikibase-cloud/logs/events",
"receiveTimestamp": "2023-04-04T00:01:27.048651171Z"
}A nice graph of the memory increasing and then plummeting:
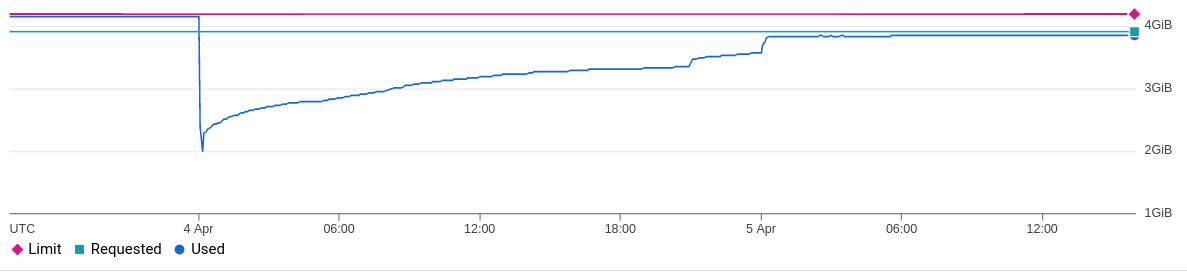
This can be seen happening every few days by using a query similar to:
logName="projects/wikibase-cloud/logs/events" jsonPayload.message:"Memory cgroup out of memory" jsonPayload.message:"mysqld"
A/C:
- Increase the RAM (double it)
- After this investigate if there is a reason for this ram problem that is fixable
- This could involve finding out if MariaDB is poorly configured
- If still time left: investigate what would be "the right amount" of RAM to allocate for our purposes