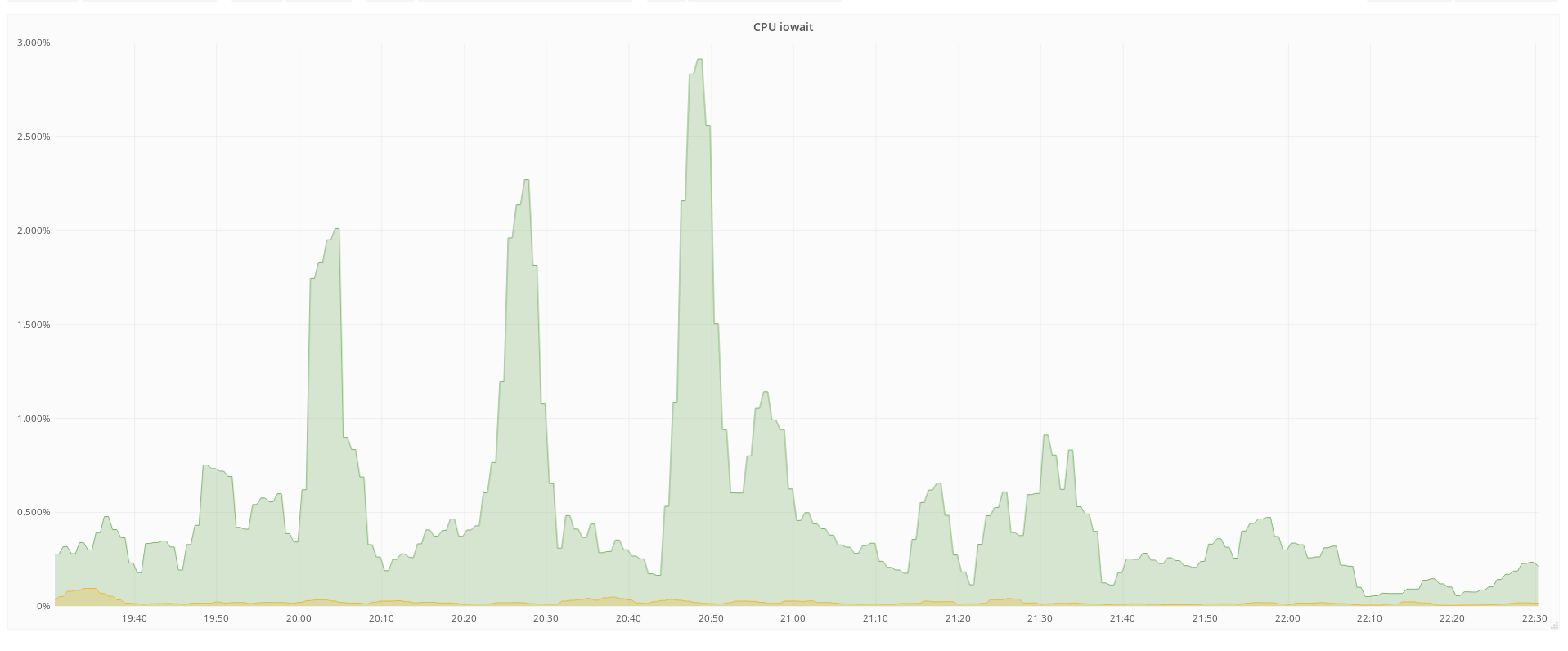
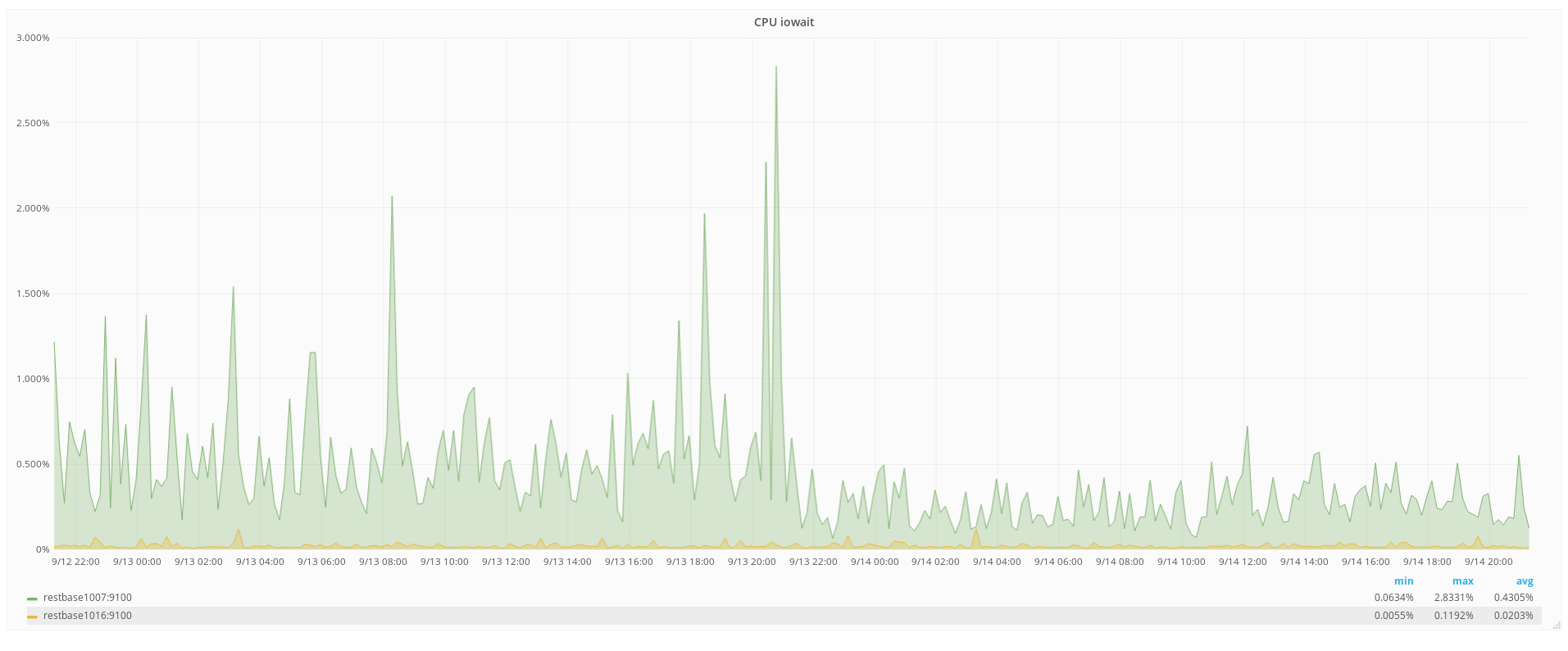
From what I see in puppet & on individual hosts I get the impression that we don't routinely enable the TRIM command for SSDs. TRIM helps to keep SSDs performing for longer by letting the SSD know which logical blocks are no longer needed.
There seem to be two main ways to do this in modern systems:
- discard option in fstab:
/dev/sda1 / ext4 defaults,noatime,discard 0 1
- calling fstrim from cron. http://blog.neutrino.es/2013/howto-properly-activate-trim-for-your-ssd-on-linux-fstrim-lvm-and-dmcrypt/ talks about the pros of this approach.
See also
- SSD issue summary article, part of an in-depth series on SSD performance and internals.