I thought the new instances were going crazy, but I couldn't find any process using a lot of memory.
Turns out it takes a couple reboots before the matrics are reliable.
For comparison:
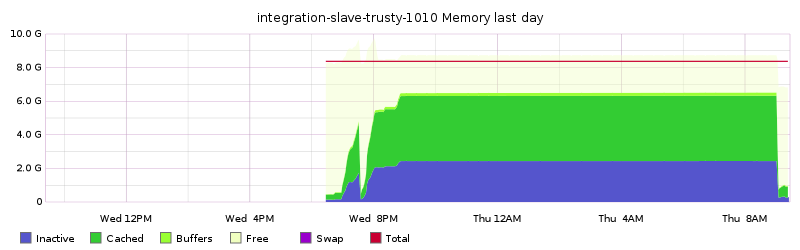
integration-slave1401, 1402, and 1404 were rebooted once last week (for unrelated reasons):
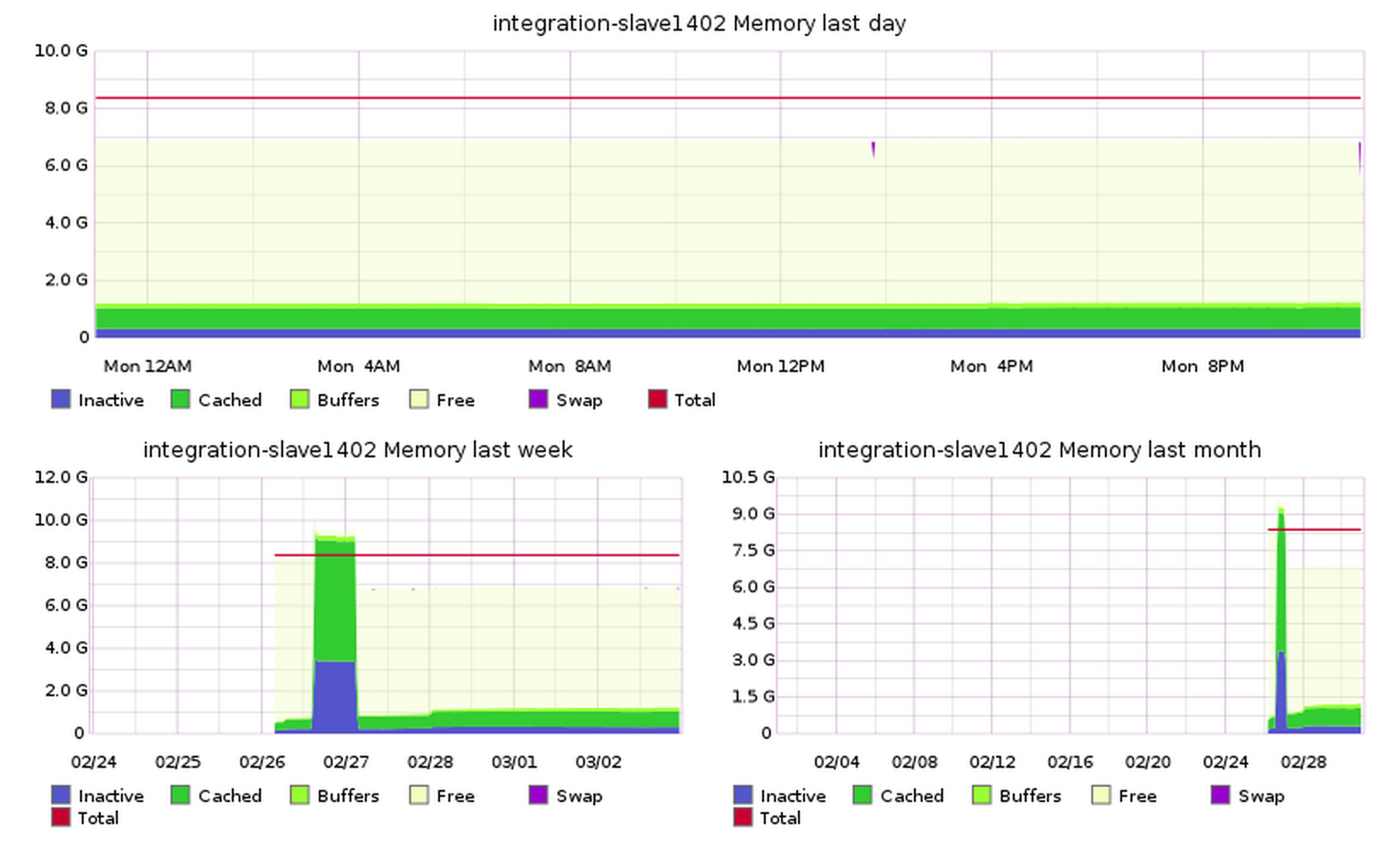
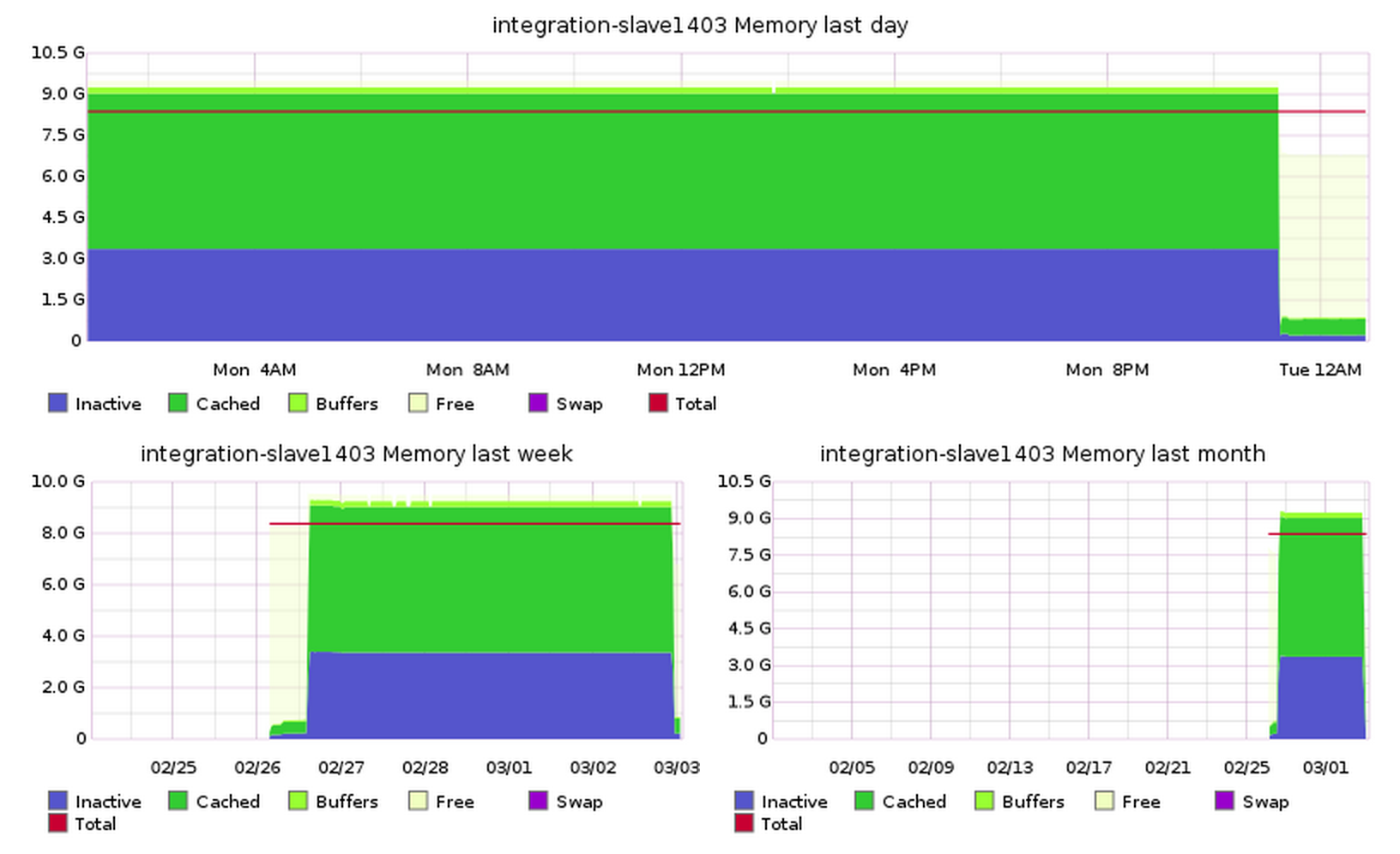
integration-slave1403 and slave1405, however, were already working fine and their free and top output are nearly identical to that of slave1402. Yet, their alleged memory usage was huge in graphite. I checked that the graph wasn't stuck or flat, it was still reacting lively to processes. It's reporting is just off by 8.5GB.
The total didn't even add up. It was reporting 9.5GB memory usage on an instance with only 8GB of total memory.