Great! I believe that it is working. Here is the output from radeontop.
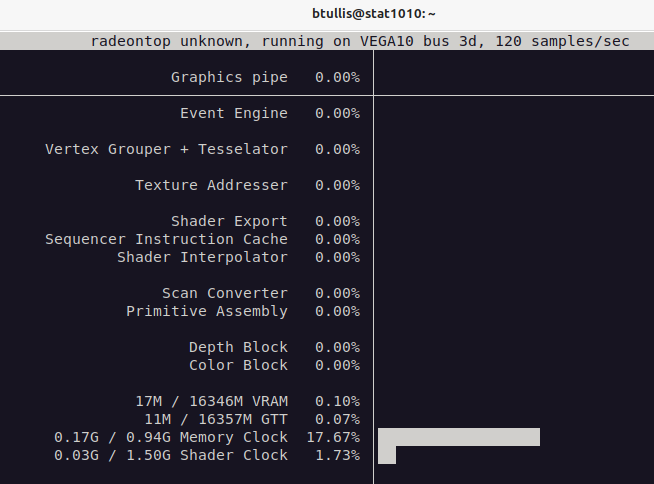
Great! I believe that it is working. Here is the output from radeontop.
Hmm. This isn't working correctly yet, I get the following results from radeontop.
btullis@stat1010:~$ sudo radeontop -l 10 -d - Failed to open DRM node, no VRAM support. Dumping to -, line limit 10. 1713976775.777684: bus 3d, gpu 100.00%, ee 100.00%, vgt 100.00%, ta 100.00%, sx 100.00%, sh 100.00%, spi 100.00%, sc 100.00%, pa 100.00%, db 100.00%, cb 100.00% 1713976776.777859: bus 3d, gpu 100.00%, ee 100.00%, vgt 100.00%, ta 100.00%, sx 100.00%, sh 100.00%, spi 100.00%, sc 100.00%, pa 100.00%, db 100.00%, cb 100.00% 1713976777.778032: bus 3d, gpu 100.00%, ee 100.00%, vgt 100.00%, ta 100.00%, sx 100.00%, sh 100.00%, spi 100.00%, sc 100.00%, pa 100.00%, db 100.00%, cb 100.00% 1713976778.778199: bus 3d, gpu 100.00%, ee 100.00%, vgt 100.00%, ta 100.00%, sx 100.00%, sh 100.00%, spi 100.00%, sc 100.00%, pa 100.00%, db 100.00%, cb 100.00%
There is nobody logged onto the server yet, so I can give it a reboot and try again.
The GPU is now correctly detected.
btullis@stat1010:~$ sudo lshw -class display
*-display
description: VGA compatible controller
product: Integrated Matrox G200eW3 Graphics Controller
vendor: Matrox Electronics Systems Ltd.
physical id: 0
bus info: pci@0000:03:00.0
version: 04
width: 32 bits
clock: 66MHz
capabilities: pm vga_controller bus_master cap_list rom
configuration: driver=mgag200 latency=0 maxlatency=32 mingnt=16
resources: irq:16 memory:91000000-91ffffff memory:92808000-9280bfff memory:92000000-927fffff memory:c0000-dffff
*-display UNCLAIMED
description: VGA compatible controller
product: Vega 10 XT [Radeon PRO WX 9100]
vendor: Advanced Micro Devices, Inc. [AMD/ATI]
physical id: 0
bus info: pci@0000:3d:00.0
version: 00
width: 64 bits
clock: 33MHz
capabilities: pm pciexpress msi vga_controller cap_list
configuration: latency=0
resources: iomemory:38bf0-38bef iomemory:38bf0-38bef memory:38bfe0000000-38bfefffffff memory:38bff0000000-38bff01fffff ioport:6000(size=256) memory:ab000000-ab07ffff memory:ab0a0000-ab0bffffI will make a patch to add the necessary packages.
I have upgraded all of the mons successfully.
btullis@cephosd1001:~$ sudo ceph tell mon.* version
mon.cephosd1001: {
"version": "17.2.7",
"release": "quincy",
"release_type": "stable"
}
mon.cephosd1002: {
"version": "17.2.7",
"release": "quincy",
"release_type": "stable"
}
mon.cephosd1003: {
"version": "17.2.7",
"release": "quincy",
"release_type": "stable"
}
mon.cephosd1004: {
"version": "17.2.7",
"release": "quincy",
"release_type": "stable"
}
mon.cephosd1005: {
"version": "17.2.7",
"release": "quincy",
"release_type": "stable"
}Also all of the crash services.
The active monitor has been upgraded.
btullis@cephosd1001:~$ sudo ceph tell mgr version
{
"version": "17.2.7",
"release": "quincy",
"release_type": "stable"
}Proceeding to restart the mon services in sequence.
First standby mgr upgrade is fine.
btullis@cephosd1001:~$ sudo systemctl status ceph-mgr.target
● ceph-mgr.target - ceph target allowing to start/stop all ceph-mgr@.service instances at once
Loaded: loaded (/lib/systemd/system/ceph-mgr.target; enabled; vendor preset: enabled)
Active: active since Wed 2024-04-24 11:48:13 UTC; 8s agoOur Ceph cluster isn't managed by cephadm (yet) so we do not have ready access to the ceph orch upgrade command, which would make the upgrade simpler.
I'm using a debdeploy spec to roll out the new packages to cephosd1001 first. I want to check if services are restarted as part of the upgrade.
btullis@cumin1002:~$ sudo debdeploy deploy -u 2024-04-24-ceph.yaml -Q cephosd1001.eqiad.wmnet Rolling out ceph: Library update, several services might need to be restarted
I have pulled in the latest quincy packages for bullseye with:
btullis@apt1002:~$ sudo -i reprepro --component thirdparty/ceph-quincy --noskipold update bullseye-wikimedia Calculating packages to get... Getting packages... Installing (and possibly deleting) packages... Exporting indices... Deleting files no longer referenced...
We now have the cable, so we are planning to carry out the work at 13:30 UTC tomorrow. I will send out the comms for that today.
I have a whitespace-only change in the nginx configuration for tlsproxy here: https://gerrit.wikimedia.org/r/1023440
It looks safe to me, but since it touches all the maps servers and every elasticsearch::cirrus server, I think that I had better get a review from @hnowlan and either @bking or @RKemper.
I am starting by looking at the relforge cluster. I see that the certificates are served by nginx and they are still using the puppet CA based certificates.
btullis@relforge1003:/etc/nginx$ openssl x509 -in /etc/ssl/localcerts/relforge.svc.eqiad.wmnet.chained.crt -noout -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 7899 (0x1edb)
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN = Puppet CA: palladium.eqiad.wmnet
Validity
Not Before: Mar 18 02:55:32 2021 GMT
Not After : Mar 18 02:55:32 2026 GMT
Subject: CN = relforge.svc.eqiad.wmnetI'll check to see if there is any code ready to deploy cfssl based certificates for nginx.
I did a successful deploy after having merged the patch to remove vestiges of git-fat intgreation, so I believe that we can close this ticket now.
btullis@deploy1002:/srv/deployment/analytics/hdfs-tools/deploy$ scap deploy 10:22:34 Started deploy [analytics/hdfs-tools/deploy@3618aab] 10:22:34 Deploying Rev: HEAD = 3618aab73c835f56a71f692c59b09dc1f973d094 10:22:34 Started deploy [analytics/hdfs-tools/deploy@3618aab]: (no justification provided) 10:22:34 == DEFAULT == :* an-test-coord1001.eqiad.wmnet :* an-launcher1002.eqiad.wmnet :* stat1004.eqiad.wmnet :* stat1006.eqiad.wmnet :* stat1011.eqiad.wmnet :* an-web1001.eqiad.wmnet :* stat1007.eqiad.wmnet :* an-coord1003.eqiad.wmnet :* an-coord1004.eqiad.wmnet :* clouddumps1001.wikimedia.org :* stat1005.eqiad.wmnet :* an-test-client1002.eqiad.wmnet :* stat1009.eqiad.wmnet :* stat1010.eqiad.wmnet :* stat1008.eqiad.wmnet 10:22:42 analytics/hdfs-tools/deploy: fetch stage(s): 100% (in-flight: 0; ok: 15; fail: 0; left: 0) | 10:22:43 analytics/hdfs-tools/deploy: config_deploy stage(s): 100% (in-flight: 0; ok: 15; fail: 0; left: 0) | 10:22:44 analytics/hdfs-tools/deploy: promote stage(s): 100% (in-flight: 0; ok: 15; fail: 0; left: 0) | 10:22:44 default deploy successful 10:22:44 == DEFAULT == :* an-test-coord1001.eqiad.wmnet :* an-launcher1002.eqiad.wmnet :* stat1004.eqiad.wmnet :* stat1006.eqiad.wmnet :* stat1011.eqiad.wmnet :* an-web1001.eqiad.wmnet :* stat1007.eqiad.wmnet :* an-coord1003.eqiad.wmnet :* an-coord1004.eqiad.wmnet :* clouddumps1001.wikimedia.org :* stat1005.eqiad.wmnet :* an-test-client1002.eqiad.wmnet :* stat1009.eqiad.wmnet :* stat1010.eqiad.wmnet :* stat1008.eqiad.wmnet 10:22:45 analytics/hdfs-tools/deploy: finalize stage(s): 100% (in-flight: 0; ok: 15; fail: 0; left: 0) | 10:22:45 default deploy successful 10:22:45 Finished deploy [analytics/hdfs-tools/deploy@3618aab]: (no justification provided) (duration: 00m 11s) 10:22:45 Finished deploy [analytics/hdfs-tools/deploy@3618aab] (duration: 00m 10s)
Upon investigation it was discovered that hdfs-tools no longer has any requirement for large file support, so we have merged this patch, which removes the git-fat configuration from the repository.
For reference, the latest point release for Quincy is 17.2.5 and we could sync these packages to our apt server at any time.
btullis@apt1002:~$ sudo -i reprepro --component thirdparty/ceph-quincy checkupdate bullseye-wikimedia Calculating packages to get... Updates needed for 'bullseye-wikimedia|thirdparty/ceph-quincy|amd64': 'ceph': '17.2.5-1~bpo11+1' will be upgraded to '17.2.7-1~bpo11+1' (from 'thirdparty/ceph-quincy'): <snip snip>
The reef packages, which have been added recently by @MatthewVernon as part of T279621: Set up Misc Object Storage Service (moss) are at version 18.2.2, which is the latest point release.
btullis@apt1002:~$ sudo -i reprepro -C thirdparty/ceph-reef list bookworm-wikimedia ceph bookworm-wikimedia|thirdparty/ceph-reef|amd64: ceph 18.2.2-1~bpo12+1
The dependence on Archiva for git-fat has been almost completely removed now, as far as I am aware. There is one patch relating to blazegraph/wdqs that is still to be merged, then we will have completed that part of it.
I don't have the necessary rights in gerrit to +2 the patch, but I should proabably get them. Until then, perhaps @bking, @RKemper, or another member of the wikidata-deploy group can +2 it.
Ah, we already had a ticket for converting hdfs-tools but it was linked from the parent of this ticket: T328473: hdfs-tools: Stop using git-fat
Interestingly, the files are also out of date on puppetserver1001, which is running version 4 of geoipupdate from bookworm.
btullis@puppetserver1001:~$ ls -lrt /srv/puppet_fileserver/volatile/GeoIP|tail -n 4 -rw-r--r-- 1 root root 109944609 Apr 17 03:30 GeoIP2-City.mmdb -rw-r--r-- 1 root root 11613299 Apr 17 03:30 GeoIP2-Connection-Type.mmdb -rw-r--r-- 1 root root 6426222 Apr 17 03:30 GeoIP2-Country.mmdb -rw-r--r-- 1 root root 14591352 Apr 17 03:30 GeoIP2-ISP.mmdb
btullis@puppetserver1001:~$ apt-cache policy geoipupdate
geoipupdate:
Installed: 4.10.0-1
Candidate: 4.10.0-1
Version table:
*** 4.10.0-1 500
500 http://mirrors.wikimedia.org/debian bookworm/contrib amd64 Packages
100 /var/lib/dpkg/statusThe service that is fired from the daily timer says that it's running correctly, so we're not receiving any errors from systemd.
btullis@puppetserver1001:~$ systemctl status geoip_update_main.service
○ geoip_update_main.service - download geoip databases from MaxMind
Loaded: loaded (/lib/systemd/system/geoip_update_main.service; static)
Active: inactive (dead) since Fri 2024-04-19 03:30:04 UTC; 8h ago
TriggeredBy: ● geoip_update_main.timer
Docs: https://wikitech.wikimedia.org/wiki/Monitoring/systemd_unit_state
Process: 2779247 ExecStart=/usr/bin/geoipupdate -f /etc/GeoIP.conf -d /srv/puppet_fileserver/volatile/GeoIP (code=exited, status=0/SUCCESS)
Main PID: 2779247 (code=exited, status=0/SUCCESS)
CPU: 384msI have updated the configuration on db1208 so that it replicates from matomo1003 instead of matomo1002.
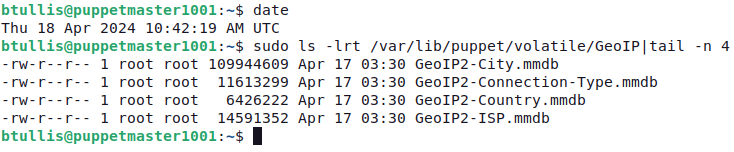
The maxmind databases are still not updated. They still have the date of April 17.
btullis@puppetmaster1001:~$ sudo ls -lrt /var/lib/puppet/volatile/GeoIP|tail -n 4 -rw-r--r-- 1 root root 109944609 Apr 17 03:30 GeoIP2-City.mmdb -rw-r--r-- 1 root root 11613299 Apr 17 03:30 GeoIP2-Connection-Type.mmdb -rw-r--r-- 1 root root 6426222 Apr 17 03:30 GeoIP2-Country.mmdb -rw-r--r-- 1 root root 14591352 Apr 17 03:30 GeoIP2-ISP.mmdb
The marketing campaigns reporting plugin is active and is the latest 4.x version available.

The new version is now live.
btullis@matomo1003:~$ tail -f /var/log/apache2/other_vhosts_access.log
We found that the GMS pod wasn't starting properly on production, so it looks like it's unrelated to BOOTSTRAP_SYSTEM_UPDATE_WAIT_FOR_SYSTEM_UPDATE.
The filesystem on the drive is unmounted and commented out from /etc/fstab, so the disk is out of service and can be hot-swapped at any time.
I've created T362871 to track the hardware replacement. I'll mark this ticket as blocked until the new drive is in place, then I'll use this ticket to track putting the disk back in service.
I tried running the commands manually and downloading to a temporary directory and they seem fine.
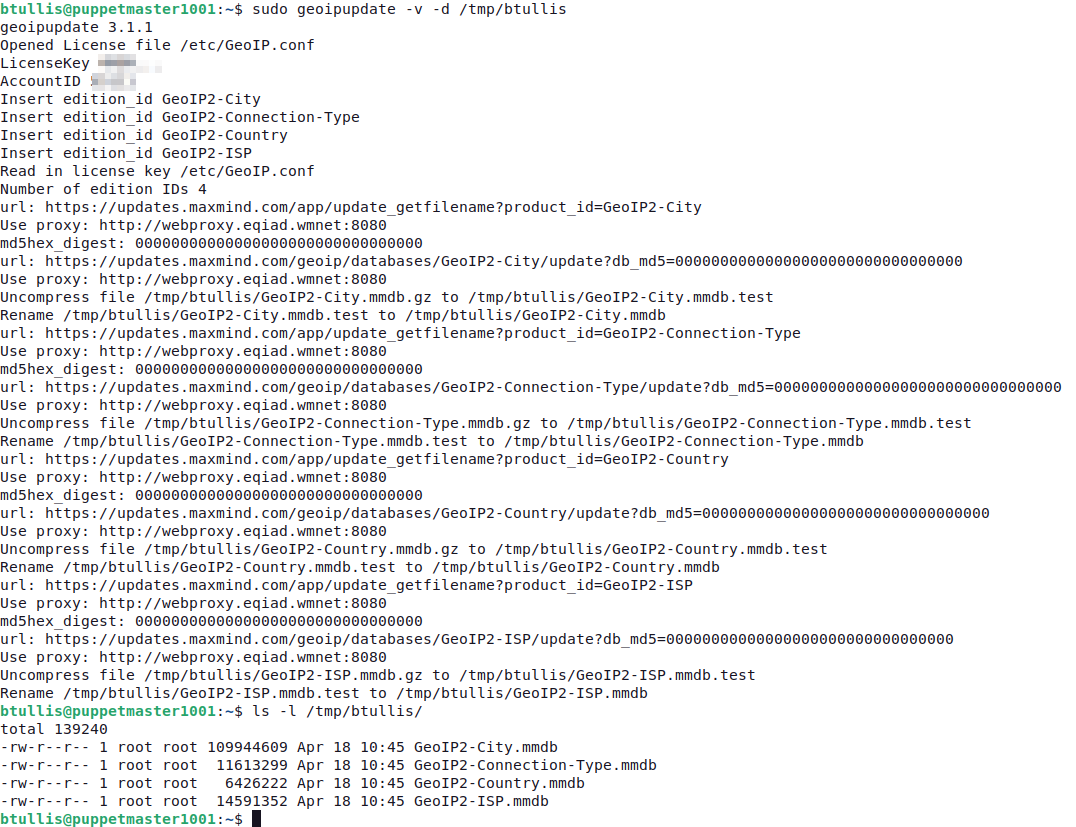
I'm reopening this ticket because the files did not download correctly today.
It's looking increasingly like a hardware issue.
btullis@an-worker1087:~$ sudo fsck /dev/sdh1 fsck from util-linux 2.36.1 e2fsck 1.46.2 (28-Feb-2021) /dev/sdh1 contains a file system with errors, check forced. Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Error reading block 660612973 (Input/output error) while reading directory block. Ignore error<y>?
This from dmesg -T.
[Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#304 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#304 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE cmd_age=0s [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#304 Sense Key : Medium Error [current] [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#304 Add. Sense: No additional sense information [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#304 CDB: Read(16) 88 00 00 00 00 01 3b 01 43 68 00 00 00 08 00 00 [Thu Apr 18 10:10:22 2024] blk_update_request: I/O error, dev sdh, sector 5284905832 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#325 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#326 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#194 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#262 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#262 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#263 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#263 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE cmd_age=0s [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#263 Sense Key : Medium Error [current] [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#263 Add. Sense: No additional sense information [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#263 CDB: Read(16) 88 00 00 00 00 01 3b 01 43 68 00 00 00 08 00 00 [Thu Apr 18 10:10:22 2024] blk_update_request: I/O error, dev sdh, sector 5284905832 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [Thu Apr 18 10:10:22 2024] Buffer I/O error on dev sdh1, logical block 660612973, async page read [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#844 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#262 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#263 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#267 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#327 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#268 BRCM Debug mfi stat 0x2d, data len requested/completed 0x1000/0x0 [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#268 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE cmd_age=0s [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#268 Sense Key : Medium Error [current] [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#268 Add. Sense: No additional sense information [Thu Apr 18 10:10:22 2024] sd 0:2:7:0: [sdh] tag#268 CDB: Read(16) 88 00 00 00 00 01 3b 01 43 68 00 00 00 08 00 00 [Thu Apr 18 10:10:22 2024] blk_update_request: I/O error, dev sdh, sector 5284905832 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [Thu Apr 18 10:10:22 2024] Buffer I/O error on dev sdh1, logical block 660612973, async page read
I will file a hardware troubleshooting ticket for DC Ops.
This is the current output from lsblk
btullis@an-worker1087:~$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 111.3G 0 disk ├─sda1 8:1 0 953M 0 part /boot ├─sda2 8:2 0 1K 0 part └─sda5 8:5 0 110.3G 0 part ├─an--worker1087--vg-swap 254:0 0 9.3G 0 lvm [SWAP] ├─an--worker1087--vg-root 254:1 0 55.9G 0 lvm / └─an--worker1087--vg-journalnode 254:2 0 10G 0 lvm /var/lib/hadoop/journal sdb 8:16 0 3.6T 0 disk └─sdb1 8:17 0 3.6T 0 part /var/lib/hadoop/data/b sdc 8:32 0 3.6T 0 disk └─sdc1 8:33 0 3.6T 0 part /var/lib/hadoop/data/c sdd 8:48 0 3.6T 0 disk └─sdd1 8:49 0 3.6T 0 part /var/lib/hadoop/data/d sde 8:64 0 3.6T 0 disk └─sde1 8:65 0 3.6T 0 part /var/lib/hadoop/data/e sdf 8:80 0 3.6T 0 disk └─sdf1 8:81 0 3.6T 0 part /var/lib/hadoop/data/f sdg 8:96 0 3.6T 0 disk └─sdg1 8:97 0 3.6T 0 part /var/lib/hadoop/data/h sdh 8:112 0 3.6T 0 disk └─sdh1 8:113 0 3.6T 0 part /var/lib/hadoop/data/g sdi 8:128 0 3.6T 0 disk └─sdi1 8:129 0 3.6T 0 part /var/lib/hadoop/data/j sdj 8:144 0 3.6T 0 disk └─sdj1 8:145 0 3.6T 0 part /var/lib/hadoop/data/k sdk 8:160 0 3.6T 0 disk └─sdk1 8:161 0 3.6T 0 part /var/lib/hadoop/data/i sdl 8:176 0 3.6T 0 disk └─sdl1 8:177 0 3.6T 0 part /var/lib/hadoop/data/m sdm 8:192 0 3.6T 0 disk └─sdm1 8:193 0 3.6T 0 part /var/lib/hadoop/data/l
We can see that /dev/sdh1 is currently mounted to /var/lib/hadoop/data/g. On the next boot, the drive letter assignments might be different.
I have found one more small repository that uses git-fat and that is https://gerrit.wikimedia.org/r/admin/repos/analytics/hdfs-tools/deploy,general
I think I'm right in saying that we don't need to complete the archiva migration before switching to git-lfs.
That's right, isn't it @dancy? We migrated analytics/refinery recently and that is still using Archiva, for now.
Hi @awight - I'm happy to try to help here, but as @MoritzMuehlenhoff points out, trying to get packages from the Debian repositories that match your requirements may be quite tricky.
Some of our stat hosts (stat1004-8) are also still running buster, so their versions will be even further behind, although we're currently working to bring them up to date.