An additional source of complication is that if we end up using RWS (T345589), we'd probably want to register loginwiki as a service domain, and one requirement for RWS service domains is that the top-level URL (ie. https://login.wikimedia.org/) must redirect away to a different domain.
Feed Advanced Search
Tue, Apr 16
Tue, Apr 16
Tgr added a parent task for T362715: Move credentials change to central login wiki: T348388: Use central login wiki for login (SUL3).
Tgr added a parent task for T362706: Display the login / signup page in a popup: T348388: Use central login wiki for login (SUL3).
Tgr added a comment to T354482: Clean up login.wikimedia.org ahead of SUL3 login.
Tgr renamed T345589: Investigate the First-Party Sets / Related Website Sets browser API from Investigate the First-Party Sets browser API to Investigate the First-Party Sets / Related Website Sets browser API.
Tgr updated the task description for T345589: Investigate the First-Party Sets / Related Website Sets browser API.
Tgr added a comment to T356614: Do not do central login after security reauthentication.
Tgr added a comment to T354701: Migrate WebAuthn credentials to loginwiki.
Tgr added a comment to T354701: Migrate WebAuthn credentials to loginwiki.
I think the way to go here is to keep the current login system and the SUL3 login system working in parallel for a while and ask the WebAuthn users to migrate. They won't be able to use SUL3 initially, since their passkeys won't work on loginwiki, but they can log in with the old process, disable the passkey, go to loginwiki, set up a new passkey, and use that with SUL3. Not the most straightforward but WebAuthn users are very likely technically proficient so I think it's fine.
Tgr added a comment to T354701: Migrate WebAuthn credentials to loginwiki.
Actually it is less than that because people can have more than one passkey.
wikiadmin2023@10.64.0.47(centralauth)> SELECT oat_name, count(*) FROM oathauth_devices JOIN oathauth_types ON oad_type = oat_id GROUP BY oat_name; +----------+----------+ | oat_name | count(*) | +----------+----------+ | totp | 2367 | | webauthn | 185 | +----------+----------+
Mon, Apr 15
Mon, Apr 15
Tgr updated the task description for T359926: Test cross-domain cookie access with the Storage Access API and Related Website Sets.
Tgr renamed T359926: Test cross-domain cookie access with the Storage Access API and Related Website Sets from Test cross-domain cookie access with Related Website Sets to Test cross-domain cookie access with the Storage Access API and Related Website Sets.
Tgr added a comment to T359948: Test cross-domain cookie access with Storage Access API.
This is similar to T359926: Test cross-domain cookie access with the Storage Access API and Related Website Sets except the Storage Access API (without RWS) requires user interaction by design
Tgr added a comment to T116129: Give us some errors or something when the LESS parsing fails.
Tgr added a comment to T362216: Unable to set JavaScript breakpoints in gadget code when using ?debug=1.
The other thing to maybe check is whether it is related to mw.loader.store. IIRC in the past it was possible to set breakpoints in modules loaded from localStorage but they didn't really work (since the browser didn't see those modules as persistent). But it was a long time since I last tried.
Tgr placed T296334: Make linkrecommendation service logging more useful up for grabs.
Tgr added a comment to T359926: Test cross-domain cookie access with the Storage Access API and Related Website Sets.
The code is in https://gitlab.wikimedia.org/tgr/sul3-rws, the test site is at https://sul3-rws-test.toolforge.org/ (and the other one at https://sul3-rws-login.toolforge.org/ but that doesn't need to be visited directly). It's not quite working as expected yet, I'm still figuring out the various Storage Access API related behaviors.
Tgr added a comment to T362331: SessionBackend: remove dependency on Kask/Cassandra.
T352481: Remove 'db-replicated' and ReplicatedBagOStuff was planning to drop the ReplicatedBagOStuff class, should that be reversed then?
Tgr added a comment to T362480: Introduces the notion of modules into the REST API framework.
Sun, Apr 14
Sun, Apr 14
Tgr added a comment to T353589: Opt out of Chrome topic calculation on Wikimedia sites & Cloud Services.
This results in a slightly annoying (although probably harmless) Error with Permissions-Policy header: Origin trial controlled feature not enabled: 'browsing-topics'. console error, at least when using the Beta channel release of Chrome.
Not sure what's happening - there doesn't seem to be any ongoing origin trial for topics, it shows up (and is enabled) in my settings. But the chrome://flags/#privacy-sandbox-ads-apis feature flag seems to be disabled by default.
Tgr added a comment to T362480: Introduces the notion of modules into the REST API framework.
"Modules" is a somewhat unfortunate name IMO, given that the action API calls single endpoints "modules".
Sat, Apr 13
Sat, Apr 13
Tgr added a comment to T316303: Check global rights during autocreation.
The problem is that User::isRegistered() tries to load the user, and User::isItemLoaded( 'name' ) is always true if we tried to load the user, even if it's an anonymous user.
Fri, Apr 12
Fri, Apr 12
Tgr added a comment to T362331: SessionBackend: remove dependency on Kask/Cassandra.
The benefit of a proper migration is that the new store can shadow the old one for a while and we can test whether it works correctly, performance characteristics etc. without affecting user experience at all.
Tgr added a comment to T163492: With $wgReadOnly set and when $wgSessionCacheType = CACHE_DB, ApiQueryTokens will return invalid tokens.
Could be a setup issue if you have a multiwiki setup, where the DB where objectcache is stored is not the one that was set to readonly. Other than that, it would be pretty surprising if writes went through in readonly mode - it uses the same DB abstraction layer as everything else.
Thu, Apr 11
Thu, Apr 11
Tgr added a comment to T362331: SessionBackend: remove dependency on Kask/Cassandra.
for the first week use MultiWriteBagOStuff and write session data both to Kask and Memcache
Tgr added a comment to T362331: SessionBackend: remove dependency on Kask/Cassandra.
will help to librarify BagOStuff
Tgr added a comment to T362335: Decide on MediaWiki session store at WMF (2024).
What would that mean on the MediaWiki level? Building a new cache service? None of the options under https://www.mediawiki.org/wiki/Object_cache#Services have cross-DC replication, right? (Other than the main stash, but that's SQL-based and too slow.)
Tgr added a comment to T352913: session_write_close failure in PHPSessionHandlerTest under php8.3.
I meant session.save_path should never be touched since PHPSessionHandler doesn't use it. But probably this is just a poorly phrased PHP error message that and the actual error has nothing to do with that path.
Mon, Apr 8
Mon, Apr 8
Tgr added a comment to T356004: Help password managers to detect TOTP login input.
IMO we should separate the TOTP and scratch token fields (or use the same field but use JS to switch validation rules).
Tgr updated the task description for T355377: Update MediaWiki Platform team owned products for IP masking.
Sun, Apr 7
Sun, Apr 7
Sat, Apr 6
Sat, Apr 6
Tgr added a comment to T361407: Add short-to-type aliases for <syntaxhighlight> and <syntaxhighlight inline>.
Tgr added a comment to T361407: Add short-to-type aliases for <syntaxhighlight> and <syntaxhighlight inline>.
Readability trumps writability, IMO. If you find it annoying to type <syntaxhighlight inline> or <code><nowiki> (me too), some ideas:
- Better editor support (a keyboard shortcut, or opening up a syntaxhilight dialog when you type ```).
- Introduce <syntax> or <highlight>, which isn't all that shorter, but easy to understand and doesn't conflict with HTML.
- Introduce a pseudo-namespace, like <mw:code>.
- Probably not feasible to do retroactively, but I wonder whether making <syntaxhighlight>text</syntaxhighlight> automatically inline iff text doesn't contain any newline would have made sense.
- We could create a parser tag for <code> or <source>, but have it just output the HTML tag unless some distinctive property is used. lang is also a HTML property though, so not the best candidate for that. Maybe something like format or type?
- Maybe the pre-save transform could convert <sh> and <shi> into <syntaxhighlight> / <syntaxhighlight inline>? That feels very hacky... also, not easy to do I think.
Tgr reopened T360562: CSS sanitizer should support using CSS variables (not setting/creating them) for use in color values in TemplateStyles as "Open".
Not really done, it's only supported for color-related properties.
Tgr added a comment to T163492: With $wgReadOnly set and when $wgSessionCacheType = CACHE_DB, ApiQueryTokens will return invalid tokens.
At the very least, it will swallow the details of the error (there's the StorageAwareness::ERR_* constant but they are not very specific) so I don't think it's possible to return a readonly error code, short of adding some mechanism to BagOStuff to preserve the actual exception. We'd also have to propagate error details through CachedBagOStuff. And then SessionBackend::save() could log an error. Maybe eventually throw, although I don't know if session saves are guaranteed to happen before the response is sent.
Fri, Apr 5
Fri, Apr 5
Done. Didn't see any clue in the logs for what might have gone wrong.
Tgr edited projects for T309772: npm audit reports several security issues with Service runner, added: MediaWiki-Engineering; removed MediaWiki-Platform-Team.
Tgr added a comment to T345245: Mitigate phase-out of third-party cookies across MediaWiki in production.
With T345249: Mitigate phase-out of third-party cookies in CentralAuth deployed, third-party cookie blocking is now disabled in Chrome (and maybe other Chrome-like browsers but I found no information about that) until the end of the calendar year. If you want to investigate whether something will be affected by cookie blocking, set chrome://flags/#top-level-third-party-cookie-deprecation-trial to Disabled first.
Tue, Apr 2
Tue, Apr 2
Tgr closed T357935: Show temp user status on Special:CentralAuth/<username>, a subtask of T326937: Prepare CentralAuth extension for IP Masking, as Resolved.
Tgr closed T357935: Show temp user status on Special:CentralAuth/<username>, a subtask of T358030: denote whether temporary accounts is expired, as Resolved.
Tgr added a comment to T361520: "The cypress npm package is installed, but the Cypress binary is missing" error prevents merging changes.
Quibble sets XDG_CACHE_HOME=/cache. I guess that directory then gets cleared between running npm and running the tests?
This was done (to some extent) in rMWe2bad0508926: debug: Add `MW` class as helper for eval.php and shell.php.
Tgr added a comment to T163492: With $wgReadOnly set and when $wgSessionCacheType = CACHE_DB, ApiQueryTokens will return invalid tokens.
I guess the issue here is BagOStuff having cache semantics (where write failures get silently ignored under the assumption that they will, at worst, cause some performance degradation - see SqlBagOStuff::handleDBError()) but being used for some things with not-quite-cache-semantics such as session data.
Mon, Apr 1
Mon, Apr 1
Tgr closed T359957: Enroll in Chrome third-party cookies deprecation trial, a subtask of T345249: Mitigate phase-out of third-party cookies in CentralAuth, as Resolved.
Tgr added a comment to T45646: "MediaWiki:Copyright" message allows raw HTML.
Tgr updated the task description for T265362: OAuth extension - update\add logic of userCanSeeSecret() method of Backend\ConsumerAcceptance class..
Tgr updated the task description for T265362: OAuth extension - update\add logic of userCanSeeSecret() method of Backend\ConsumerAcceptance class..
Tgr added a subtask for T360596: Figure out a plan to move forward with regarding Redis License changes: T361510: Replace Redis in MediaWiki-Vagrant.
Mon, Apr 1, 6:30 PM · GitLab (Infrastructure), Patch-For-Review, User-aborrero, serviceops, MediaWiki-Platform-Team (Radar), collaboration-services, Release-Engineering-Team (Radar), Quarry, Toolforge, Software-Licensing, Infrastructure-Foundations, netbox, Platform Team Initiatives (API Gateway), ChangeProp, MediaWiki-File-management, SRE
Tgr updated the task description for T360596: Figure out a plan to move forward with regarding Redis License changes.
Mon, Apr 1, 6:14 PM · GitLab (Infrastructure), Patch-For-Review, User-aborrero, serviceops, MediaWiki-Platform-Team (Radar), collaboration-services, Release-Engineering-Team (Radar), Quarry, Toolforge, Software-Licensing, Infrastructure-Foundations, netbox, Platform Team Initiatives (API Gateway), ChangeProp, MediaWiki-File-management, SRE
Tgr added a comment to T359957: Enroll in Chrome third-party cookies deprecation trial.
FWIW, this is how the new Chrome UI looks:
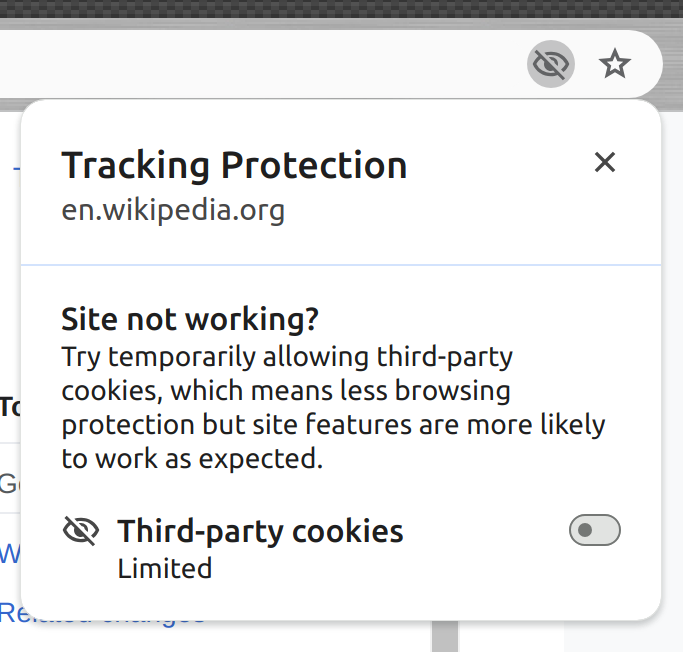 | 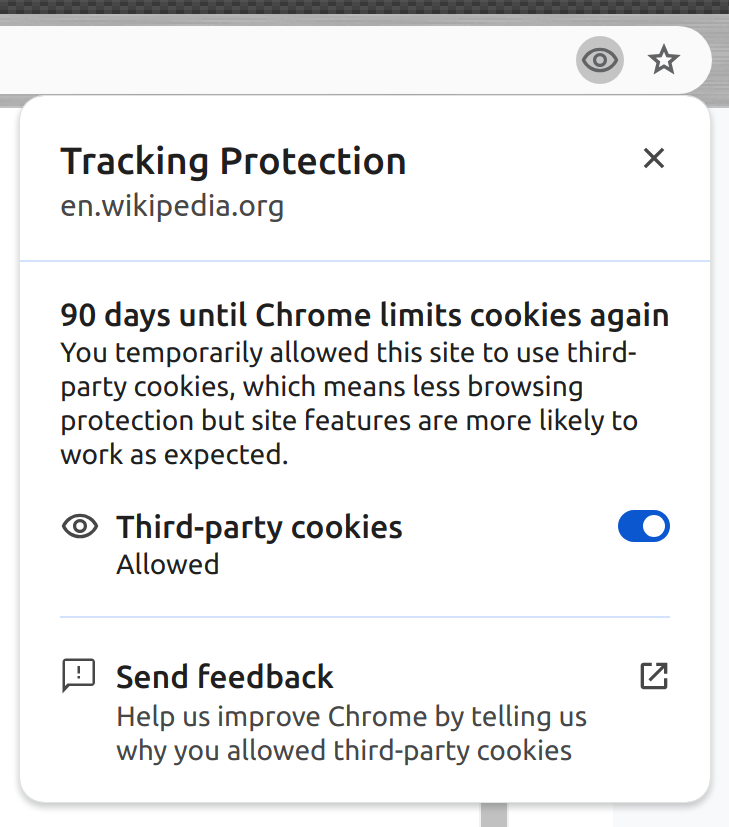 | 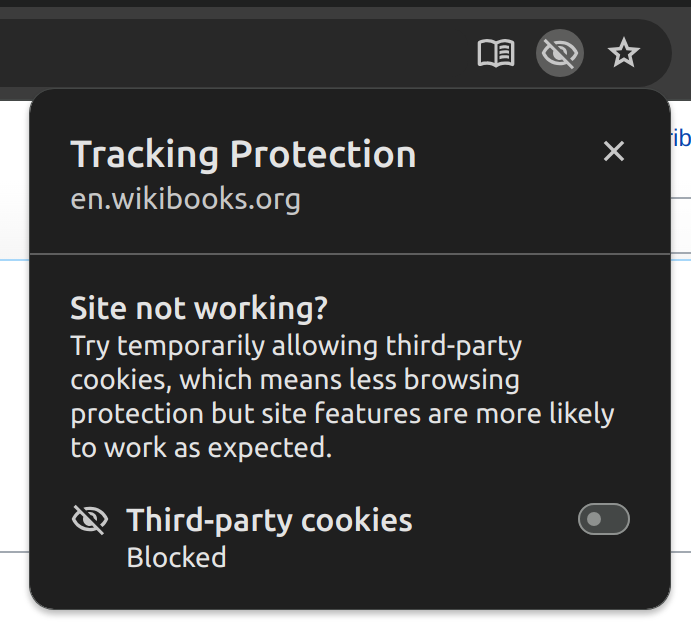 | 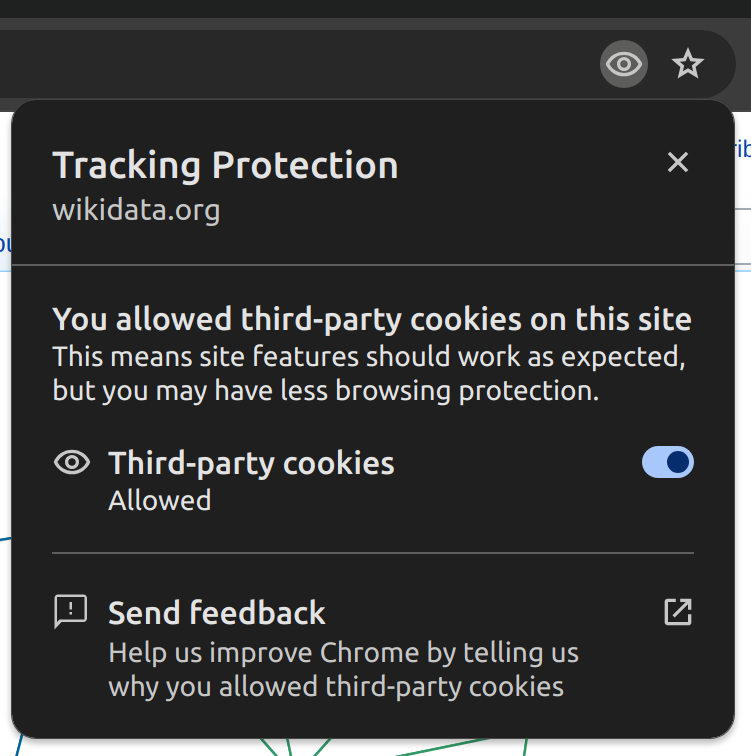 | 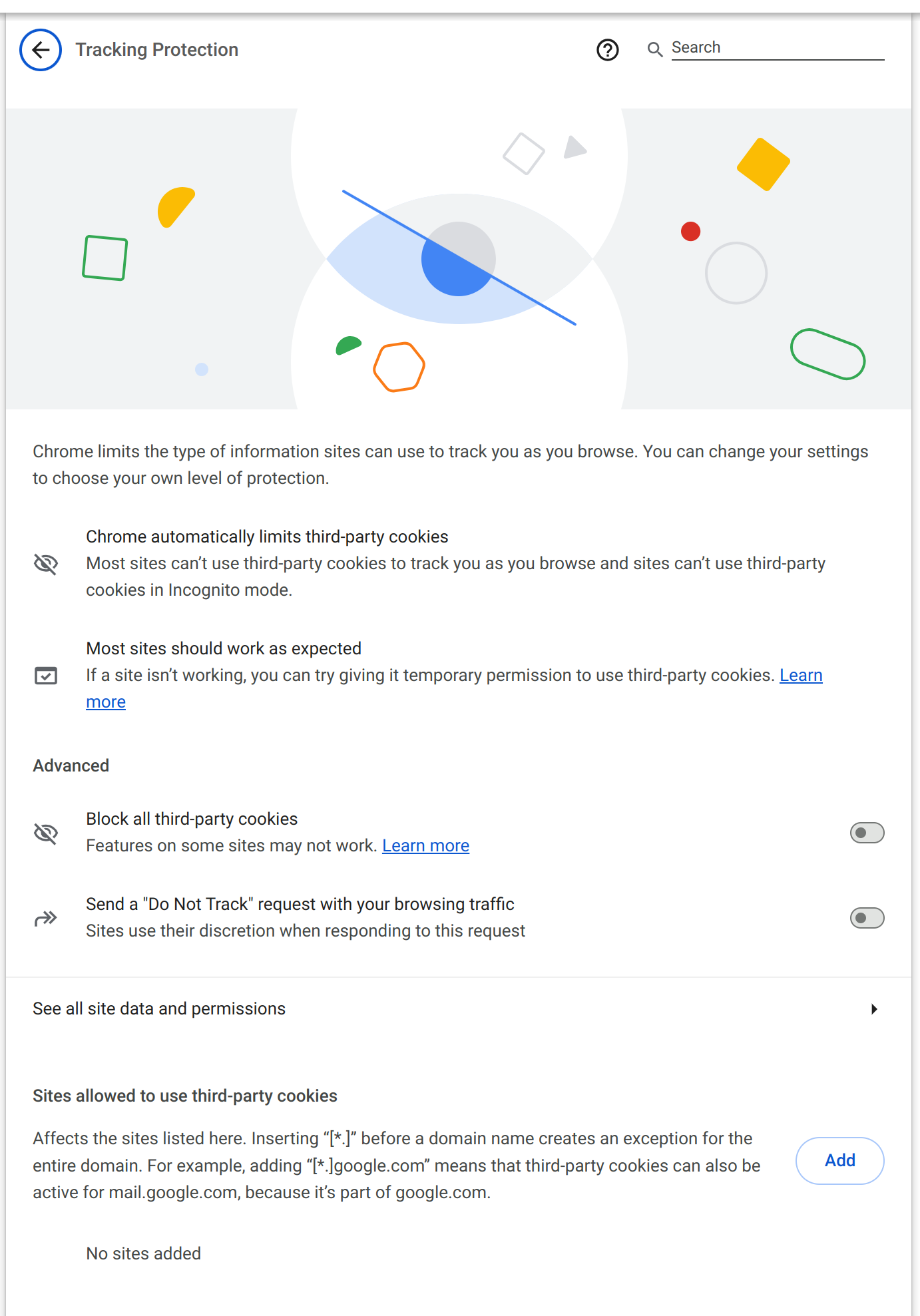 |
| tracking dialog, default state | tracking dialog after clicking the toggle | incognito tracking dialog, default state | incognito tracking dialog after clicking the toggle | Tracking Protection subpage in settings |
Tgr added a comment to T359957: Enroll in Chrome third-party cookies deprecation trial.
I have set
- chrome://flags/#tracking-protection-3pcd -> enabled
- chrome://flags/#tpcd-heuristics-grants -> disabled
- chrome://flags/#tpcd-metadata-grants -> disabled
- chrome://flags/#top-level-third-party-cookie-deprecation-trial -> enabled / disabled
Sun, Mar 31
Sun, Mar 31
Tgr moved T337161: Make PHPUnit dataProvider static in OAuth tests from Inbox, needs triage to Current Sprint on the MediaWiki-Platform-Team board.
Tgr added a comment to T355957: Switching to mobile view on wikis without a mobile domain no longer works.
I think it was caused by rEMFRf202ed928d02: No need to set target anymore removing a MobileContext call whose side effect the rest of MobileContext depended on. I made a minimal fix but preferably the code flow of that class should be improved - if a class uses a state flag then either it should have a mechanism that always sets the flag on demand, or throw when the flag is unexpectedly unset.
Fri, Mar 29
Fri, Mar 29
Tgr added a comment to T345249: Mitigate phase-out of third-party cookies in CentralAuth.
With third-party cookie blocking enabled, after a central login, Chrome's Issues tab says this:
Chrome may soon delete state for intermediate websites in a recent navigation chain
In a recent navigation chain, one or more websites accessed some form of local storage without prior user interaction. If these websites don't get such an interaction soon, Chrome will delete their state.
1 potentially tracking website: wikimedia.org
Learn more: Bounce tracking mitigations
which suggests central login and top-level autologin wouldn't survive the rollout of cookie blocking, either. I haven't reviewed the linked spec in full, but I think the relevant part is #bounce-tracking-mitigations-timers which basically says if a domain has not received user interaction in the last 45 days and it does not receive user interaction within 1 hour of the bounce tracking (ie. doing the central login redirect chain), all cookies, cache and other stored data for login.wikimedia.org will get scrubbed. This is much more aggressive than e.g. the bounce tracking mitigations used by Firefox and would render central login (in its current form) entirely useless.
Thu, Mar 28
Thu, Mar 28
Tgr added a comment to T361244: Wikimedia\Assert\PreconditionException: Precondition failed: This Title instance does not represent a proper page, but merely a link target..
It's been still happening after the train rollback, but just barely. Job queue delay I guess?
Tgr closed T361177: APCU cache mixup across wikis (Incorrect namespace displayed as title on a zh.wikivoyage page) as Resolved.
Seems fixed.
Tgr closed T361177: APCU cache mixup across wikis (Incorrect namespace displayed as title on a zh.wikivoyage page), a subtask of T360156: 1.42.0-wmf.24 deployment blockers, as Resolved.
Tgr updated the task description for T361177: APCU cache mixup across wikis (Incorrect namespace displayed as title on a zh.wikivoyage page).
Tgr updated the task description for T359957: Enroll in Chrome third-party cookies deprecation trial.
Tgr added a comment to T355376: Replace $wgSharedDb with virtual domains.
Tgr added a comment to T359775: LoadBalancer::resolveDomainId should support virtual domains.
From an end user POV the LB/LBF differentation is pretty much never useful, if you need an LB you'll just do $lbf->getMainLB( $domain ). But the LB/LBF interfaces have all kinds of things that are not present on ICP but sometimes needed. Those could be moved to ICP but there is also benefit in keeping ICP simple and limited to functionality that's often used.
Wed, Mar 27
Wed, Mar 27
Tgr added a comment to T345245: Mitigate phase-out of third-party cookies across MediaWiki in production.
Google apparently built a DevTools plugin (the Privacy Sandbox Analysis Tool) for detecting issues caused by cookie blocking, so that might be a good way of looking for potential breakage.
Tgr added a comment to T359957: Enroll in Chrome third-party cookies deprecation trial.
The more public-facing Google posts are a bit confusing about whether there are usage limits for the trial, but the origin trials developer guide is pretty clear that they don't apply to deprecation trials, so we won't have to worry about that.
Tgr updated the task description for T359957: Enroll in Chrome third-party cookies deprecation trial.
Tgr added a comment to T41662: Allow -webkit-filter CSS.
(FWIW css-sanititer does handle filter already.)
I'll just untag and close as duplicate to reduce confusion. Please file a dedicated task for TemplateStyles / css-sanitizer if you think this functionality is needed there.
Tgr added a comment to T41662: Allow -webkit-filter CSS.
T308160: Uncensor use of "filter" CSS property on wikitext pages is about the wikitext parser. This issue is tagged as TemplateStyles (now, at least; presumably the task author meant the task to be about the parser, since it predates the existence of TemplateStyes). In TemplateStyles, this isn't resolved.
Tgr added a comment to T345566: error.log is not rotated in beta.
Seems properly rotated now:
tgr@deployment-mwlog02:~$ ls -l /srv/mw-log/archive/err* -rw-r--r-- 1 udp2log udp2log 39300 Mar 12 15:45 /srv/mw-log/archive/error.log-20240313.gz -rw-r--r-- 1 udp2log udp2log 2528 Mar 13 09:21 /srv/mw-log/archive/error.log-20240314.gz -rw-r--r-- 1 udp2log udp2log 574 Mar 14 01:20 /srv/mw-log/archive/error.log-20240315.gz -rw-r--r-- 1 udp2log udp2log 2277 Mar 15 22:45 /srv/mw-log/archive/error.log-20240316.gz -rw-r--r-- 1 udp2log udp2log 1371 Mar 16 07:23 /srv/mw-log/archive/error.log-20240317.gz -rw-r--r-- 1 udp2log udp2log 1518 Mar 17 15:32 /srv/mw-log/archive/error.log-20240318.gz -rw-r--r-- 1 udp2log udp2log 2804 Mar 18 16:19 /srv/mw-log/archive/error.log-20240319.gz -rw-r--r-- 1 udp2log udp2log 1205 Mar 19 18:56 /srv/mw-log/archive/error.log-20240320.gz -rw-r--r-- 1 udp2log udp2log 1928 Mar 20 18:32 /srv/mw-log/archive/error.log-20240321.gz -rw-r--r-- 1 udp2log udp2log 2150 Mar 21 21:53 /srv/mw-log/archive/error.log-20240322.gz -rw-r--r-- 1 udp2log udp2log 1400 Mar 22 18:21 /srv/mw-log/archive/error.log-20240323.gz -rw-r--r-- 1 udp2log udp2log 3176 Mar 23 16:15 /srv/mw-log/archive/error.log-20240324.gz -rw-r--r-- 1 udp2log udp2log 575 Mar 24 01:20 /srv/mw-log/archive/error.log-20240325.gz -rw-r--r-- 1 udp2log udp2log 1824 Mar 25 16:46 /srv/mw-log/archive/error.log-20240326.gz -rw-r--r-- 1 udp2log udp2log 52860 Mar 26 21:46 /srv/mw-log/archive/error.log-20240327
Tgr added a comment to T359957: Enroll in Chrome third-party cookies deprecation trial.
The relevant information from the non-public tasks and admin UI:
- "Trial Available: Up to Chrome 132 (ends with the rollout of next Chrome release), no later than Dec 28, 2024"
- "If you’d like to submit additional third-party domains for review for this top level site, please email 3pcd-1p-deprecationtrial@google.com."
- "For all other questions and issues, please visit our blog post. If further support is needed, please file an issue here"