@dancy it would be great if someone could finish this soon. While scap now does have an option to mitigate potential helm hiccups, I think we should add it to the mix nevertheless
Feed Advanced Search
Tue, Apr 16
Tue, Apr 16
jijiki updated the task description for T362323: Move 100% of external traffic to Kubernetes (excluding Votewiki and Commons).
Mon, Apr 15
Mon, Apr 15
jijiki updated the task description for T362518: Deprecate buster-backports.
Thu, Apr 11
Thu, Apr 11
jijiki renamed T273950: Modernise memcached systemd unit / sync, and make it presentable from Modernise memcached systemd unit / sync to current buster setup to Modernise memcached systemd unit / sync, and make it presentable.
jijiki added a comment to T361724: scap should check if it is running within a tmux/screen.
jijiki added a subtask for T290536: Serve production traffic via Kubernetes: T346690: mcrouter daemonset on mw-on-k8s.
jijiki added a parent task for T346690: mcrouter daemonset on mw-on-k8s: T290536: Serve production traffic via Kubernetes.
jijiki edited parent tasks for T277711: Memcached, mcrouter in MediaWiki on Kubernetes, added: T290536: Serve production traffic via Kubernetes; removed: T265327: Create a basic helm chart to test MediaWiki on kubernetes.
jijiki awarded T362323: Move 100% of external traffic to Kubernetes (excluding Votewiki and Commons) a Burninate token.
jijiki updated the task description for T350807: Package latest version of prometheus-memcached-exporter (v0.14.2).
jijiki closed T350807: Package latest version of prometheus-memcached-exporter (v0.14.2) as Resolved.
Built and repackaged
jijiki closed T350807: Package latest version of prometheus-memcached-exporter (v0.14.2), a subtask of T352891: Upgrade memcache and memcached gutter pools to Bookworm, as Resolved.
Built and uploaded
jijiki closed T362160: Repackage memkeys for debian bookworm, a subtask of T352891: Upgrade memcache and memcached gutter pools to Bookworm, as Resolved.
jijiki updated the task description for T362160: Repackage memkeys for debian bookworm.
jijiki renamed T350807: Package latest version of prometheus-memcached-exporter (v0.14.2) from Package latest version of prometheus-memcached-exporter (v0.14.1) to Package latest version of prometheus-memcached-exporter (v0.14.2).
jijiki moved T362160: Repackage memkeys for debian bookworm from Incoming 🐫 to Doing 😎 on the serviceops board.
jijiki updated the task description for T360636: Phase out cergen for ServiceOps services.
jijiki updated the task description for T357750: Phase out cergen.
jijiki removed a subtask for T357750: Phase out cergen: T360778: Move maps/karthoterian to PKI/cfssl.
jijiki edited parent tasks for T360778: Move maps/karthoterian to PKI/cfssl, added: T360636: Phase out cergen for ServiceOps services; removed: T357750: Phase out cergen.
Tue, Apr 9
Tue, Apr 9
jijiki added a comment to T361724: scap should check if it is running within a tmux/screen.
Thu, Apr 4
Thu, Apr 4
jijiki awarded T350507: Update mobileapps k8s deployment chart for Cassandra credentials a Love token.
Wed, Apr 3
Wed, Apr 3
jijiki added a project to T361720: Helm was left in limbo due to interrupted deployment/rollback : serviceops.
jijiki closed T361720: Helm was left in limbo due to interrupted deployment/rollback , a subtask of T361706: 2024-04-03 calico/typha down, as Resolved.
jijiki added a comment to T361720: Helm was left in limbo due to interrupted deployment/rollback .
We depooled mw-web-ro from eqiad, and attempted a rollback
jijiki removed a project from T361720: Helm was left in limbo due to interrupted deployment/rollback : WMF-NDA.
Tue, Apr 2
Tue, Apr 2
jijiki added a parent task for T359154: Update DC switchover cookbooks to handle mw-jobrunners: T349796: Move MediaWiki jobs to mw-on-k8s.
jijiki added a comment to T360596: Figure out a plan to move forward with regarding Redis License changes.
Tue, Apr 2, 11:40 AM · GitLab (Infrastructure), Patch-For-Review, User-aborrero, serviceops, MediaWiki-Platform-Team (Radar), collaboration-services, Release-Engineering-Team (Radar), Quarry, Toolforge, Software-Licensing, Infrastructure-Foundations, netbox, Platform Team Initiatives (API Gateway), ChangeProp, MediaWiki-File-management, SRE
Thu, Mar 28
Thu, Mar 28
jijiki updated the task description for T346690: mcrouter daemonset on mw-on-k8s.
Wed, Mar 27
Wed, Mar 27
Switchover is done, it is Day 8, and we are back to Multi-DC. Thank you serviceops and @akosiaris for being good teammates and keeping an eye on things.
jijiki closed T358286: SRE comms for Northward Datacentre Switchover (March 2024), a subtask of T357547: ☂️ Northward Datacentre Switchover (March 2024) , as Resolved.
Tue, Mar 26
Tue, Mar 26
jijiki updated the task description for T357547: ☂️ Northward Datacentre Switchover (March 2024) .
Thu, Mar 21
Thu, Mar 21
jijiki updated the task description for T357547: ☂️ Northward Datacentre Switchover (March 2024) .
jijiki updated the task description for T357547: ☂️ Northward Datacentre Switchover (March 2024) .
Mar 20 2024
Mar 20 2024
jijiki updated the task description for T357547: ☂️ Northward Datacentre Switchover (March 2024) .
jijiki updated the task description for T357547: ☂️ Northward Datacentre Switchover (March 2024) .
jijiki updated the task description for T357547: ☂️ Northward Datacentre Switchover (March 2024) .
Mar 19 2024
Mar 19 2024
jijiki closed T359154: Update DC switchover cookbooks to handle mw-jobrunners, a subtask of T357547: ☂️ Northward Datacentre Switchover (March 2024) , as Resolved.
This is done, weill reopen if something goes south
Mar 6 2024
Mar 6 2024
Mar 5 2024
Mar 5 2024
jijiki updated the task description for T359154: Update DC switchover cookbooks to handle mw-jobrunners.
jijiki added a comment to T346690: mcrouter daemonset on mw-on-k8s.
mw-mcrouter ds has been deployed on staging mw-mcrouter staging
Mar 4 2024
Mar 4 2024
jijiki added a comment to T358233: MoveComms support for Northward Datacentre Switchover (March 2024).
Looks alright!
jijiki added a comment to T358233: MoveComms support for Northward Datacentre Switchover (March 2024).
@Trizek-WMF as per our off-phabricator discussion, the major change is that this is not a procedure we test anymore, but it has become standard practice. Please edit the message as you see fit to reflect that.
Feb 29 2024
Feb 29 2024
jijiki changed the status of T346690: mcrouter daemonset on mw-on-k8s, a subtask of T277711: Memcached, mcrouter in MediaWiki on Kubernetes, from Stalled to In Progress.
Feb 27 2024
Feb 27 2024
jijiki updated subscribers of T358597: urldownloader1003's network is unresponsive.
Looking into the issue, we found that around 26th Feb @ ~21:45 UTC, the urldownloader1003 (ganeti VM running on ganeti1027 ie cluster master) lost network connectivity
jijiki added a comment to T358595: Google and Yandex Translate are not available from cxserver.
This was most likely related to T358597
jijiki added a comment to T358597: urldownloader1003's network is unresponsive.
After issuing a restart, the VM came back to life normally.
Feb 23 2024
Feb 23 2024
jijiki updated the task description for T358286: SRE comms for Northward Datacentre Switchover (March 2024).
Feb 22 2024
Feb 22 2024
jijiki updated the task description for T358286: SRE comms for Northward Datacentre Switchover (March 2024).
jijiki updated the task description for T357547: ☂️ Northward Datacentre Switchover (March 2024) .
jijiki renamed T357547: ☂️ Northward Datacentre Switchover (March 2024) from Northward Datacentre Switchover (March 2024) to ☂️ Northward Datacentre Switchover (March 2024) .
Feb 21 2024
Feb 21 2024
bd808 awarded T345868: Rename the shellbox service to shellbox-score a Like token.
Feb 14 2024
Feb 14 2024
jijiki updated the task description for T357547: ☂️ Northward Datacentre Switchover (March 2024) .
jijiki closed T356766: Determine cause of HTTP 503 errors for ~8% of MediaWiki requests to ipoid service as Resolved.
Things are progressing well after the last change, please reopen if this resurfaces. Shoutout to @akosiaris for lending a hand
jijiki updated the task description for T356766: Determine cause of HTTP 503 errors for ~8% of MediaWiki requests to ipoid service.
jijiki added a comment to T356766: Determine cause of HTTP 503 errors for ~8% of MediaWiki requests to ipoid service.
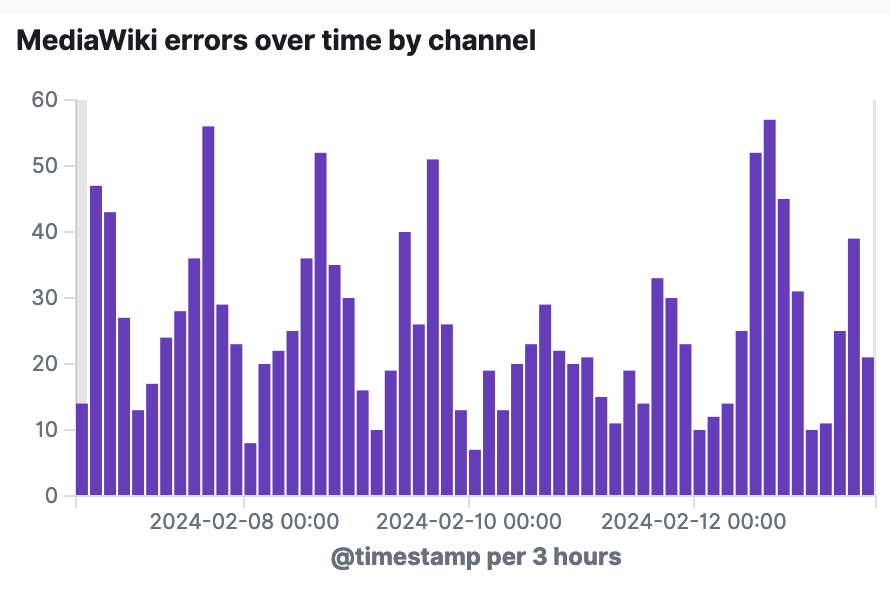
Feb 13 2024
Feb 13 2024
jijiki updated the task description for T356766: Determine cause of HTTP 503 errors for ~8% of MediaWiki requests to ipoid service.
jijiki added a comment to T356766: Determine cause of HTTP 503 errors for ~8% of MediaWiki requests to ipoid service.
- tcpdump shows that upstream sends an RST, but nothing else useful
jijiki added a comment to T356766: Determine cause of HTTP 503 errors for ~8% of MediaWiki requests to ipoid service.
Feb 12 2024
Feb 12 2024
jijiki updated the task description for T356766: Determine cause of HTTP 503 errors for ~8% of MediaWiki requests to ipoid service.
jijiki updated the task description for T356766: Determine cause of HTTP 503 errors for ~8% of MediaWiki requests to ipoid service.
jijiki added a comment to T356766: Determine cause of HTTP 503 errors for ~8% of MediaWiki requests to ipoid service.
so far:
Feb 8 2024
Feb 8 2024
jijiki added a comment to T355333: Possible firmware issues reimaging mw2282.
I set the host as inactive since I noticed a bit of log spam on lvs2013