This will simplify how we share monitoring duty during the long-running scrape job.
Feed Advanced Search
Today
Today
awight moved T357611: Re-run the scraper on a limited set of wikis from Doing to Watching / Epic / Stalled on the WMDE-TechWish-Sprint-2024-04-12 board.
awight updated the task description for T357611: Re-run the scraper on a limited set of wikis.
awight moved T357611: Re-run the scraper on a limited set of wikis from Sprint Backlog to Doing on the WMDE-TechWish-Sprint-2024-04-12 board.
Yesterday
Yesterday
awight placed T362904: Scraper: track with production Prometheus up for grabs.
awight moved T357611: Re-run the scraper on a limited set of wikis from Demo to Sprint Backlog on the WMDE-TechWish-Sprint-2024-04-12 board.
awight added a parent task for T362904: Scraper: track with production Prometheus: T357611: Re-run the scraper on a limited set of wikis.
awight added projects to T362904: Scraper: track with production Prometheus: WMDE-TechWish-Sprint-2024-04-12, Unplanned-Sprint-Work.
awight changed the status of T362358: Log events for copy and paste action around references in VE from Open to Stalled.
Stalled waiting for WMF legal review.
awight changed the status of T362358: Log events for copy and paste action around references in VE, a subtask of T357613: Measure the reference use and re-use in VE, from Open to Stalled.
awight placed T362900: Investigate scraper performance drop-off up for grabs.
Well, it could be simple after all. Articles at the end are on average twice as long (by HTML length).
awight added a comment to T362900: Investigate scraper performance drop-off.
In this example, the segment on the left is processing the tail articles starting at the 2.6M'th row, and on the right we're processing the first articles in the dump.
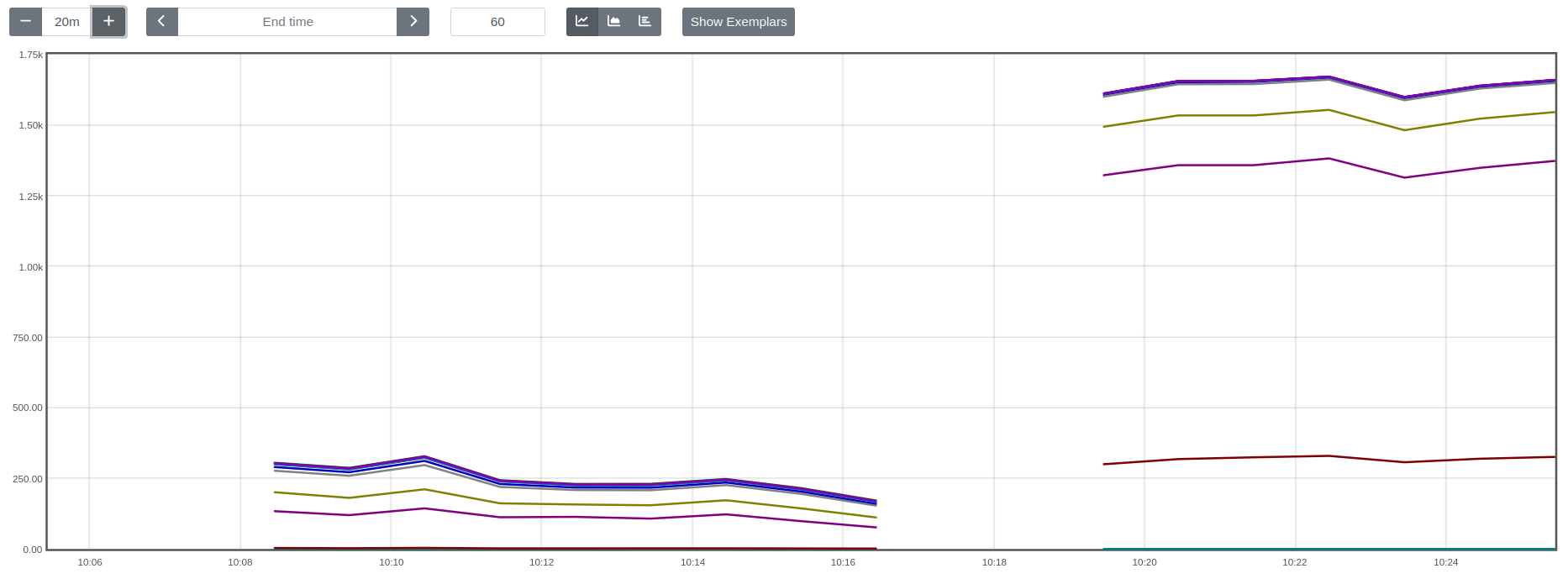
awight added a comment to T362900: Investigate scraper performance drop-off.
Very surprisingly to me, Hypothesis 4 seems to be the only validated theory. I haven't yet identified what makes the last articles harder to process, but the performance characteristics are almost perfectly repeatable when going back and forth between sets of articles at the beginning vs. the end of the dump. Initial articles can be processed at ~1.5k articles/s, and final articles at ~250 articles/s.
awight updated the task description for T362900: Investigate scraper performance drop-off.
awight updated the task description for T362900: Investigate scraper performance drop-off.
awight updated the task description for T362900: Investigate scraper performance drop-off.
awight updated the task description for T362900: Investigate scraper performance drop-off.
awight updated the task description for T362900: Investigate scraper performance drop-off.
awight moved T362900: Investigate scraper performance drop-off from Sprint Backlog to Doing on the WMDE-TechWish-Sprint-2024-04-12 board.
Fri, Apr 19
Fri, Apr 19
awight added a comment to T362900: Investigate scraper performance drop-off.
WIP on the low-level-concurrency branch will let us experiment with per-page timeouts and debugging.
awight updated the task description for T362900: Investigate scraper performance drop-off.
Thu, Apr 18
Thu, Apr 18
awight added a comment to T354018: Duplicate articles in snapshot dump.
This may be related to T362894: Data quality: HTML dumps contain unexplainably outdated revisions of some pages. The duplicates seem to have various revision ids, here's a set showing that the article is included three times with the same title and page id, but at different versions:
tar xzf dewiki-NS0-20240201-ENTERPRISE-HTML.json.tar.gz -O | jq 'select(.name == "10.000 B.C.") | .identifier,.version.identifier'
awight updated the task description for T362894: Data quality: HTML dumps contain unexplainably outdated revisions of some pages.
awight closed T362678: Package request: install elixir and erlang-otp to the analytics clients as Resolved.
@BTullis Thanks for highlighting this possibility! I tried the Conda environment as you suggested and it works perfectly for our needs. Even at high concurrency, the performance seems to be the same as in the bare metal environment I had cobbled together previously.
Wed, Apr 17
Wed, Apr 17
awight updated the task description for T357611: Re-run the scraper on a limited set of wikis.
awight added a comment to T357611: Re-run the scraper on a limited set of wikis.
Still seeing extreme swings in performance, following the same shape as before. Now with additional metrics:
awight placed T350300: Scraper: emit additional diagnostics up for grabs.
awight moved T350300: Scraper: emit additional diagnostics from Doing to Done on the WMDE-TechWish-Sprint-2024-04-12 board.
Tue, Apr 16
Tue, Apr 16
awight added a comment to T350300: Scraper: emit additional diagnostics.
awight moved T350300: Scraper: emit additional diagnostics from Sprint Backlog to Doing on the WMDE-TechWish-Sprint-2024-04-12 board.
awight added projects to T350300: Scraper: emit additional diagnostics: WMDE-TechWish-Sprint-2024-04-12, Unplanned-Sprint-Work.
Pulling this in because it would be nice to have, to debug the slowdown we see after the first 20 minutes or so.
awight moved T357611: Re-run the scraper on a limited set of wikis from Watching / Epic / Stalled to Doing on the WMDE-TechWish-Sprint-2024-04-12 board.
awight added a comment to T362678: Package request: install elixir and erlang-otp to the analytics clients.
Some of these packages already appeary in debmonitor:
awight updated the task description for T362678: Package request: install elixir and erlang-otp to the analytics clients.
awight placed T362659: Scraping enterprise dumps: investigate incomplete article lists up for grabs.
Hmm, spot-checking is only turning up articles which were created or moved after the snapshot date.
awight added a comment to T362659: Scraping enterprise dumps: investigate incomplete article lists.
Duplicates: each copy of a page comes with a different revid, and checking the final counts we can see that our deduplication did catch the extra copies during the aggregation step:
awight placed T357611: Re-run the scraper on a limited set of wikis up for grabs.
awight moved T357611: Re-run the scraper on a limited set of wikis from Doing to Watching / Epic / Stalled on the WMDE-TechWish-Sprint-2024-04-12 board.
awight moved T362659: Scraping enterprise dumps: investigate incomplete article lists from Sprint Backlog to Doing on the WMDE-TechWish-Sprint-2024-04-12 board.
awight added a project to T362659: Scraping enterprise dumps: investigate incomplete article lists: WMDE-TechWish-Sprint-2024-04-12.
Bringing this task into our sprint because it has data quality implications and probably blocks scraping for the moment.
awight renamed T362659: Scraping enterprise dumps: investigate incomplete article lists from Enterprise dumps: investigate incomplete article lists to Scraping enterprise dumps: investigate incomplete article lists.
awight added a comment to T362659: Scraping enterprise dumps: investigate incomplete article lists.
Oookay there are all kinds of things happening. Diffing the two lists, we can see that the scraper is still producing duplicates:
+1._Buch_Samuel +1._Buch_Samuel +1._Buch_Samuel +1._Buch_Samuel +1._Buch_Samuel
awight added a comment to T362659: Scraping enterprise dumps: investigate incomplete article lists.
analytics-mysql dewiki -B -e 'select page_title from page where page_namespace=0 and page_is_redirect=0' > dewiki_all_pages_db.txt
awight added a comment to T362659: Scraping enterprise dumps: investigate incomplete article lists.
Deleted articles shouldn't show up in either list, so Hypothesis #2 is also looking unlikely.
awight added a comment to T362659: Scraping enterprise dumps: investigate incomplete article lists.
ApiQueryAllPages uses the page title to carry continuation state, which is very reasonable! This would only be fooled by page renames happening during the dump interval, which is possible but not likely to add up to 1%. Hypothesis #1 is looking unlikely.
awight updated the task description for T357611: Re-run the scraper on a limited set of wikis.
awight added a comment to T357611: Re-run the scraper on a limited set of wikis.
There's still a small (<1%) gap in page count. Splitting a small investigation out as T362659.
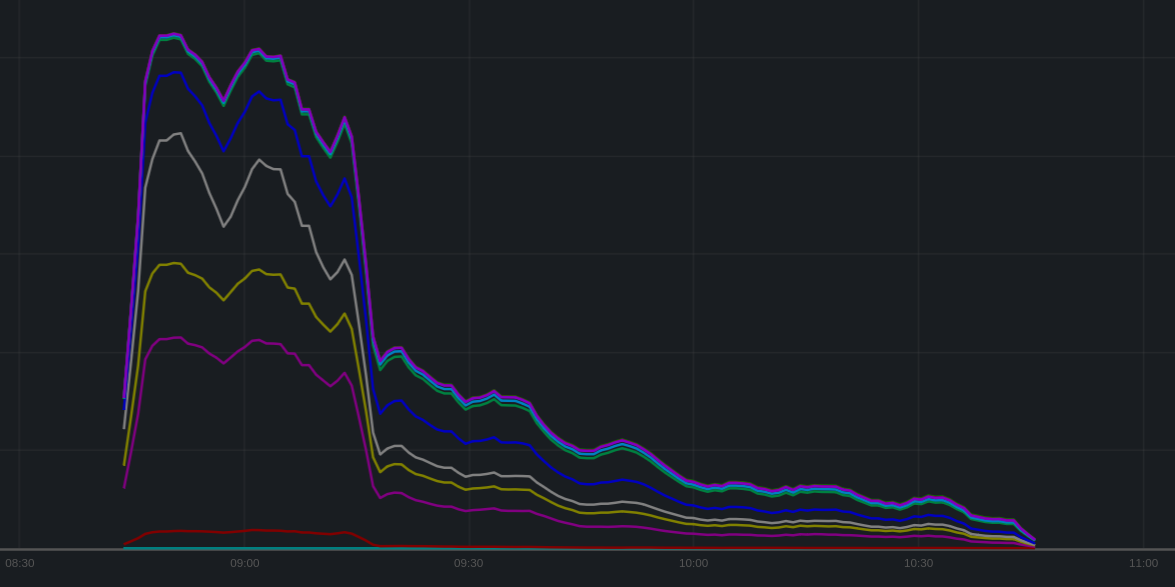
awight added a comment to T357611: Re-run the scraper on a limited set of wikis.
Performance graph (articles per second, peak is ~1k) shows very odd artifacts, these could be real or the wiki could be ordered so that longer articles come later:
awight moved T357611: Re-run the scraper on a limited set of wikis from Sprint Backlog to Doing on the WMDE-TechWish-Sprint-2024-04-12 board.
awight renamed T362159: [Hackathon session] Browser testing with Cypress from [Wikimania session] Browser testing with Cypress to [Hackathon session] Browser testing with Cypress.
awight renamed T362159: [Hackathon session] Browser testing with Cypress from [Session] Browser testing with Cypress to [Wikimania session] Browser testing with Cypress.
Mon, Apr 15
Mon, Apr 15
awight placed T362358: Log events for copy and paste action around references in VE up for grabs.
awight updated the task description for T362358: Log events for copy and paste action around references in VE.
awight updated the task description for T362358: Log events for copy and paste action around references in VE.
awight added a comment to T333168: Increase VisualEditorFeatureUse sampling rate to 100%.
WMDE Technical Wishes is relying on the 100% sampling rate for an upcoming experiment. Please let us know ahead of time if there are more plans to sample again in 2024.
awight moved T362358: Log events for copy and paste action around references in VE from Sprint Backlog to Doing on the WMDE-TechWish-Sprint-2024-04-12 board.
Looks like we can use VisualEditorFeatureUse for our needs.
awight closed T362345: Create a schema for the interaction with references in VE, a subtask of T357613: Measure the reference use and re-use in VE, as Declined.
awight placed T360816: Scraper: update changelog up for grabs.
awight updated the task description for T360816: Scraper: update changelog.
awight claimed T360816: Scraper: update changelog.
awight moved T360816: Scraper: update changelog from UX/PM Review to Doing on the WMDE-TechWish-Sprint-2024-04-12 board.
awight moved T360816: Scraper: update changelog from Sprint Backlog to UX/PM Review on the WMDE-TechWish-Sprint-2024-04-12 board.
awight moved T362332: Remove reference previews support from Popups extension from Sprint Backlog to Tech Review on the WMDE-TechWish-Sprint-2024-04-12 board.
Looks like the usages have successfully been switched over already, so let's just try to drop the Popups duplicate module and see what happens.
Fri, Apr 12
Fri, Apr 12
awight moved T361097: Re-run scripts to collect ReferenceTooltips gadget usage from Doing to Demo on the WMDE-TechWish-Sprint-2024-04-12 board.
awight placed T361097: Re-run scripts to collect ReferenceTooltips gadget usage up for grabs.
awight updated the task description for T357611: Re-run the scraper on a limited set of wikis.
awight updated the task description for T357611: Re-run the scraper on a limited set of wikis.
awight moved T359794: Add Cypress instructions to docker-dev from Sprint Backlog to Tech Review on the WMDE-TechWish-Sprint-2024-04-12 board.
Fri, Apr 12, 9:27 AM · WMDE-TechWish-Sprint-2024-04-12, WMDE-TechWish-Sprint-2024-03-27, MW-1.42-notes (1.42.0-wmf.24; 2024-03-26), Epic, WMDE-TechWish-Sprint-2024-03-13, WMDE-TechWish-Sprint-2024-02-28, WMDE-TechWish-Sprint-2024-02-15, WMDE-TechWish-Sprint-2024-01-31, Reference Previews, WMDE-TechWish-Sprint-2024-01-17, Cite, Page-Previews
awight moved T357613: Measure the reference use and re-use in VE from Sprint Backlog to Watching / Epic / Stalled on the WMDE-TechWish-Sprint-2024-04-12 board.
awight moved T355194: Move the reference previews code to Cite extension from Sprint Backlog to Watching / Epic / Stalled on the WMDE-TechWish-Sprint-2024-04-12 board.
Fri, Apr 12, 9:26 AM · WMDE-TechWish-Sprint-2024-04-12, WMDE-TechWish-Sprint-2024-03-27, MW-1.42-notes (1.42.0-wmf.24; 2024-03-26), Epic, WMDE-TechWish-Sprint-2024-03-13, WMDE-TechWish-Sprint-2024-02-28, WMDE-TechWish-Sprint-2024-02-15, WMDE-TechWish-Sprint-2024-01-31, Reference Previews, WMDE-TechWish-Sprint-2024-01-17, Cite, Page-Previews