
User Details
- User Since
- Mar 7 2023, 7:35 AM (59 w, 2 d)
- Availability
- Available
- LDAP User
- Unknown
- MediaWiki User
- Abhishek02bhardwaj [ Global Accounts ]
Sep 6 2023
Aug 30 2023
Jun 30 2023
May 28 2023
May 15 2023
@awight and @Simulo Hi, I hope you are doing great. Firstly thank you for showing trust in me, I will give my best. So as @awight already have seen my proposal for review, I wanted to ask how should I refine it and the scope of discussing a more specific timeline for the internship. Of the tasks that I mentioned in my pre-contribution period, I am a bit slower than I expected I would be in reviewing the papers since I am having my semester end exams but I'll cover as many papers as I can before the beginning. Also it would be a great help if you could help me connect with Kavitha A the other mentor for the project.
Apr 15 2023
Apr 7 2023
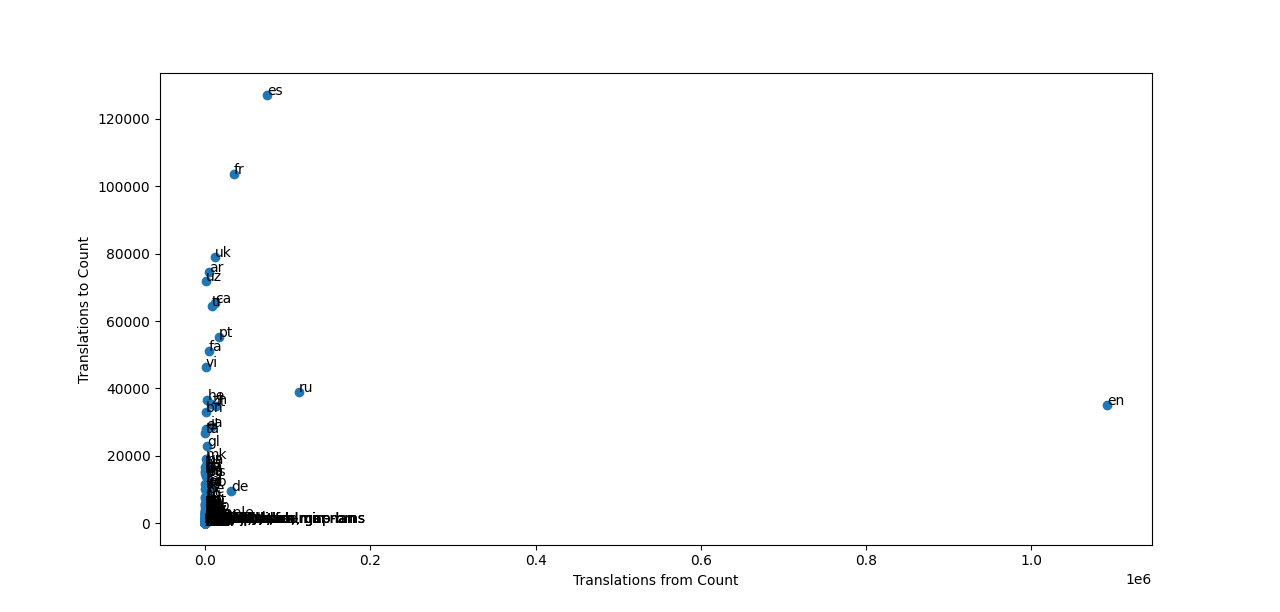
@awight I plotted another scatter plot but this time it is from the public content translation data source. For this scatter plot also I first prepared a csv with the total count of translated_from and translated_to for each of the 326 languages. From this csv we can see that there are 183 languages that have 15 or less than 15 articles translated from them (more than 56%). Also the most number of articles are translated from English and the most number of articles are translated to Es.
Oh! I forgot to add the figure and repository link in the previous comment. Here they are:
Repository Link
Apr 6 2023
Hi, @awight! Another update of the flow diagrams I am working on. Actually I made a really silly mistake in my previous work. So firstly I would like to mention what I am trying to do because I feel I am trying to explore a little different aspect of this task. So in this task we were supposed to use the data that was already there as the content translation data source in my previous sankey diagrams i used this data to achieve the task and it showed promising results but soon I was intrigued by the what if instead of using the data about number of articles already translated I try to use the configuration data and find out the available possible options for translations. I will try to elaborate what I am trying to do to the best of my ability here. So we know that the current system of translations does not provide the availability of translation service from every language to every language. I am trying to find more about the languages in which the translation availability is not that much (actually very less). The above scatter plot shows us the same thing.
What I did not think about in the previous part? So earlier in order to find out about the availability of translation option to and from a language I was using the configuration scrapper data. In that data I was counting that how many times a unique language (In either the source or target language) appears in the target language or the source language column. This got me values higher than 159 (which is the number of unique languages in the configuration scrapper output). So even though the scatter plot I was getting was dividing the languages in groups but the numbers were not correct.
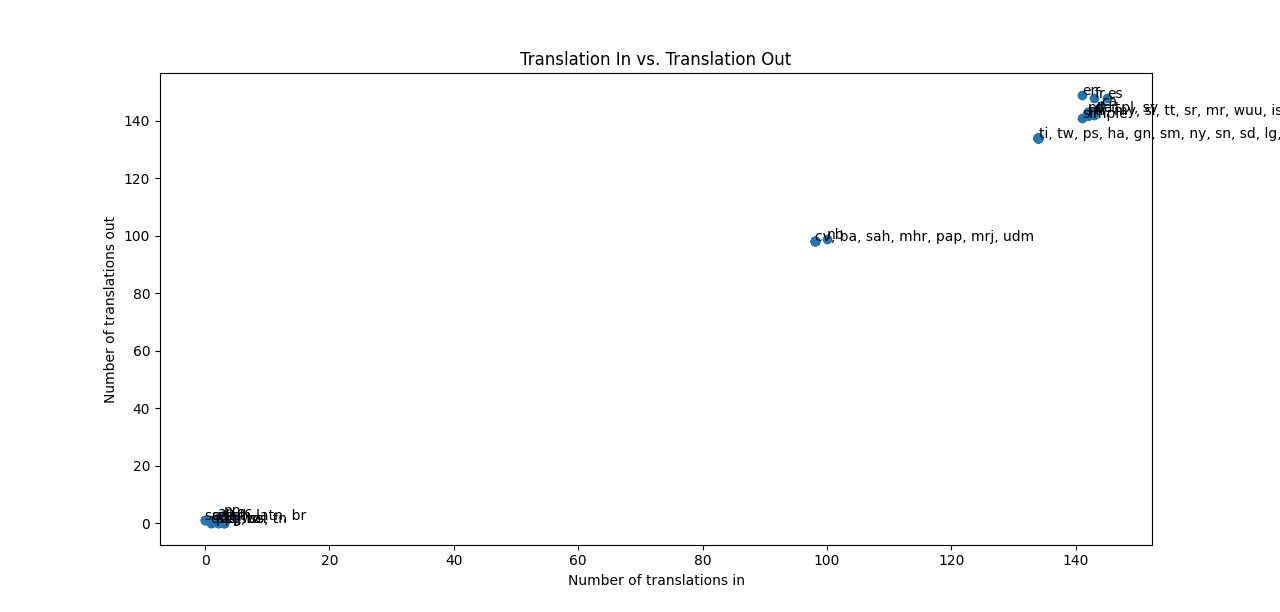
What I have done now? Now to make sure that all the unique languages are there in the list I first created a csv and got all the unique languages in it then from those languages I counted that how many times uniquely each language appears in the target language column given that the language is the source language and saved this number as translation out (representing outwards flow of translation from that language) and for the translation in I counted how many times uniquely each language appears in the source language column given that the language is the target language and saved this number as translation in (representing inwards flow of translation from that language).
From this I got a csv which can give the translation feasibility of each language. I think while trying to research into the imbalances in translation specifically in machine translation the most basic thing we need to know is that if there are tools available to translate that language. For instance 15 languages have less than or equal to 5 options for target language. 22 languages have less than 100 options for target languages. 73 languages have 134 or less options for target language. When the total languages that are explored in machine translation are 159. And the language with maximum number of available options in target language is es with 145 language which means it can't be translated to 14 languages. And so on.
Apr 4 2023
Also I made a scatter plot of wikis and their article counts. Again it looks incomprehensible in the image but if you run the script you can zoom and have a better look.
the script that generates this scatter plot is "Scatter_plot_wiki_wiki_vs_Article_count"
Apr 3 2023
Apr 2 2023
Apr 1 2023
Mar 31 2023
Mar 30 2023
Mar 27 2023
Mar 26 2023
Hello, @awight , @srishakatux and @Simulo. I have drafted a proposal for the project Research into translation imbalances. I wanted to ask for a feedback or review if possible. Please have a look and let me know about any changes you would like to suggest.
Mar 24 2023
Hello @awight and @Simulo, here is my updated submission for this task. I have also uploaded the updated output file in the repository (Thanks to GitHub LFS). I am looking forward to your views and reviews. Thanks in advance.
GitHub Repository.
Mar 23 2023
Hello @awight and @Simulo, here is my submission for this task. I would be very happy to have your views over it.
GitHub Repository.
Here is the link for my file. It was too big to be uploaded on github, so I am uploading it to Google drive and sharing the link as I figure out how to use GitHub Large File Storage.
Google Drive Link
@awight So I did the integration of the two programs and I gave it a test run. The output file is giving the timestamps of each commit. The only thing is that the output file I am getting is a bit too big (727MB) which is not unexpected I think since the original CSV file had 28k lines and there have been quite a few commits on the repository since 2017 (starting from 16-01-2017). I wanted to ask that how should I upload it because there is a size limit for upload files on both GitHub and Phabrikator. Can you please suggest me something for that.
Hello, @awight. I am having a little bit of problem accessing the cxserver repository. On visiting the link it is showing me "Not Found". I think due to the same reason I am getting an error on executing my python code which gives me an error saying "fatal: path 'config/' exists on disk, but not in '43da799d1b35c4ace5704869e4031784c195c4ed'". Is there something wrong with the link or is it on my local system only.
Hello, @awight Thank you very much for your valuable feedback.
This is relevant to our project, and has the same sign as the effect we're seeing. My understanding of the article is also that people in the so-called periphery are committing to English- and French-language Wikipedias proportionally more than to regional language wikis—but this effect if extrapolated to translation would have the opposite sign: this would suggest that translators might tend to translate into former colonial languages.
I got a very similar result to this while doing the task #T331204 where we had to produce flow diagrams illustrating translation imbalances. One important noteworthy thing that I observed while producing those diagrams was that when I removed all the rows with English as source language, the largest number of lines were still pointing to English. Which I believe means that English is also the most popular target language among the other languages. And when I removed English from both the target language and source language, ru (which I think is the short for Russian) was the most popular language along with fr and es, which again gives a strong back to our hypothesis.
Mar 22 2023
Hello @awight and @Simulo, Here is my code repo for this task. As @Ahn-nath mentioned in her analysis/ comparison, the output CSV file I was getting was not 100% accurate. In some target and source language pairs where either the target or the source language was "no" the value was taken as False. I have corrected the miscellaneous error and the CSV file now I am getting is giving an accuracy of 100%.
Here is my github repository that includes the code as well as the final output.
Github Repository.
Mar 21 2023
Mar 20 2023
Hello @awight and @Simulo Thank you for your guidance. As you mentioned in your earlier comment, I have included tests in my repository for my program. I would be really thankful if you could take out some time to review them. I am attaching the Github repository link for your kind reference.
Github Repository Link
There is one more help I wanted to ask for. I wanted to discuss the prospective Outreachy internship project timeline with the mentors but I don't know how should I do it. So I thought maybe I could make a private Github repository and add our mentors there as contributors so that they can review it and give their valuable suggestions and guidance if that is okay. Also is there any specific format or examples that the mentors would like us to follow, I am fairly new to writing proposals and prospective timelines and hence would really appreciate if the mentors could guide me over how should I start.
Also are there any community specific questions that the mentors would like us to answer.
Thank you in advance.
Mar 18 2023
@awight It took me while but I was finally able to use the functionality of mt-defaults.wikipedia.yaml in the parser. Now the value of "is preferred engine?" is not all false by default and I have one less file to ignore. Please have a look at the repository and share your views. Thanks in advance.
Github Repository Link
Updated CSV File -
Mar 17 2023
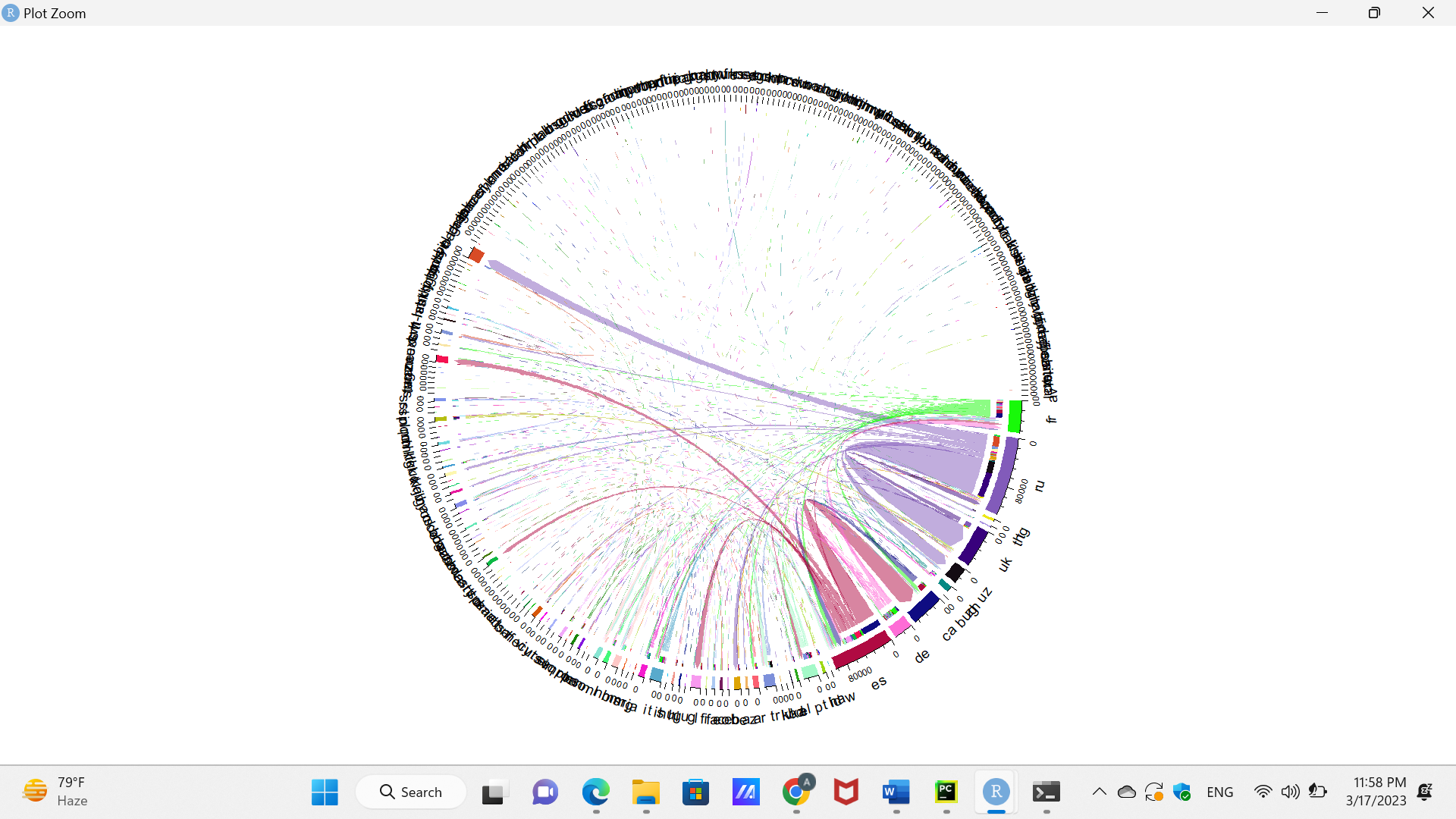
@awight @Simulo Here is my submission for this task. Actually I am not taking this as completed because there are still a lot more things that can be tried with the data but i wanted to register my findings that I have come across up till now. So to accomplish the task what I did was first I converted the data from Here into a CSV file and loaded into R as it was mentioned in the example. Then I tried to make out diagrams from that data with the best of my understanding to find new observations. Like for my first sankey diagram I used all of the languages present in the data which gave me a result similar to the one in the example. Then I removed english from both source and target language to see which were the other languages with maximum number of translation. Observing that diagram I got three such more languages (fr, ru, es). Removing them from the target and source language I observed that their was less imbalance than previous two cases but still the translation data was highly imbalanced.
I have recorded all of my codes and the outcome diagrams in a github repository. I would be very thankful to have your views and suggestions over it.
Github Repository Link
Diagrams I got as result.
Mar 16 2023
Mar 14 2023
@awight and @Simulo I re-read my code and realised that there were certain structural glitches. The time stamps that were appended in the CSV file were not the ones when the commit took instead they were some else. So i wrote the code again from scratch and used a little different approach.
I am leaving a small summary of my work - This code is designed to track changes to a CSV file over time using Git. It includes three functions: parse_csv(), run_git_command(), and get_commits(). The parse_csv() function reads in a CSV file, converts it to a dictionary, and returns it. The run_git_command() function runs a given Git command and returns the output. The get_commits() function retrieves a list of all Git commits and for each commit, retrieves the timestamp, CSV data, and appends them to a list of dictionaries. Finally, the export_csv() function writes the accumulated data for each commit into a new CSV file that includes an additional column for the commit timestamp.
The main program calls these functions and exports the data history to a CSV file named 'data_history.csv'. The data is arranged in a flat structure, with each row representing a single commit, and includes the city, temperature, and timestamp for that commit.
Link to the Github Repository - https://github.com/Abhishek02bhardwaj/Evolution-Tracker
The Updated CSV file -
I will be very grateful if you could take out some time to review my submission. I have also updated the read-me file. Since I am new to writing open-source code I do not have that much of expertise in code documentation, therefore if you could give me any suggestions to improve my read-me, I would be very thankful.
Mar 13 2023
@awight Since "notAsTarget" hasn't been used in the files, Is it okay ignore it for now.
I wanted to ask one more thing. Is it okay now if I record my submission of this task on the Add a Contribution page of Outreachy and should I mark it accepted/merged or not.
Mar 12 2023
@Anshika_bhatt_20 Hey Anshika, do you mind taking a look at the repository and and the CSV file and sharing your views. I'll be really thankful.
@awight I have updated the github repository with the updates in code and the CSV file. To address the last issue left I have used a slightly different approach. Instead of parsing the "transform.js" file from the config folder and then using it to generate the target and source language pairs, what I have done is that i have used the logic of "transform.js" directly in my code. This gives us two benefits:
- It reduces the compile and execution time (though very slightly) since I didn't have to import another library to use the Javascript file.
- It keeps the code simple to understand (or at least i hope so).
I would be really grateful if you could take a look at the repository and share your reviews. Thank you.
Github Repository Link - https://github.com/Abhishek02bhardwaj/Extract-cxserver-configuration-and-export-to-CSV
Updated CSV File -
@Anshika_bhatt_20
Ohkay thank you for the advice. I'll definitely try it. Right now I have converted the transform.js handler into a python file(that i wrote myself), I think it should work.
Mar 11 2023
@awight @srishakatux @Simulo The first of the two issues I listed in my previous comment has been addressed in my most recent commit to the repository. Now all the language pairs of the respective engines are there in the CSV file. Just to make it more accessible I am adding the CSV file here and also the github repository link. Now the only issue left to address in this task is how to use the handler.js file to access the source and target languages. I am still trying to figure that out and would really appreciate any kind of help.
Github Repository Link - https://github.com/Abhishek02bhardwaj/Extract-cxserver-configuration-and-export-to-CSV
Updated CSV File -
Mar 10 2023
@awight I have updated the github repo and made some changes in the parser to accommodate the changes that you suggested. The following changes can be seen in the CSV file:
- The engine name is now the name of the file just how it was supposed to be.
- I have removed the unwanted handlers that I added in while testing.
- I have excluded the files that were supposed to be ignored.
The following are the issues that I am yet to address:
- The parser takes into consideration only the first source language of the file (since i hardcoded that while testing). We needed all the source languages and their respective target languages. To accomplish the same I will include the code snippet that was accessing the target languages for the source language in a while loop and use a try and except to handle the error that might arise at the end of the list. I am aware that this explanation might not be sufficient to explain what I am trying to do but I just wanted to keep it here since it might help someone else too.
- I am yet to understand how to use the transform.js handler. @awight I needed a bit of help regarding that. I am not really sure about how I can use the handler.js file to get the source and target language pairs from Google.yaml and Yandex.yaml. I would really appreciate if you could guide me over that.
link of the repo (just to make it easier to access) - https://github.com/Abhishek02bhardwaj/Extract-cxserver-configuration-and-export-to-CSV
The Updated CSV file -
@awight I am not sure if JsonDict.yaml should also be ignored because it looks fine to me.
@awight Regarding the mt-defaults.wikimedia.yaml file, it sets the default translation engines to be used for each language pair if no other engine is specified in the configuration files. This file does not define the language pairs themselves, so it does not affect the supported translation pairs. I wanted to use it in the parser but again I felt that first I should address the engine name issue.
@awight Thanks for taking out some time to review my contribution. I have made the repository public so now it will be easier to access by anyone and help others too to improve the quality of work.
Mar 9 2023
@awight @Simulo @srishakatux I have tried to write some code in python to make a parser for these files and create a single flat, in-memory structure with all of the supported pairs and export this data as a CSV of all pairs, with at least the required columns. I am attaching the CSV file that I am getting as the result and also a link of the github repository in which I have added the python code (keeping it private to preserve the code privacy if that is fine).
Link to the github repository - https://github.com/Abhishek02bhardwaj/Extract-cxserver-configuration-and-export-to-CSV
The CSV file that I got as result -
Mar 8 2023
@Simulo @awight
Here is the link to my survey for this task. I have tried to keep it short as I think a survey which is too big to fill gets inconvenient for the user to fill. Please have a look and let me know about any improvement and changes you would suggest. Thank you.
Link - https://etherpad.wikimedia.org/p/xGzVywcafj65F66Gea2n
Mar 7 2023
@awight @Simulo @Aklapper @srishakatux anything I missed or any suggestions especially for the hypotheses.
Hypotheses about the patterns expected in a dataset of translation between different Wikipedias
Now based on the above paper, there are certain patterns that we can expect in a dataset of translation between different Wikipediaes. I would be stating these patterns in the form of hypothesis as follows:
• Broadband connectivity will predict the curve of translations between different Wikipediaes up to and extent: In the paper itself it is mentioned that - countries with very small and high numbers of broadband Internet connections commit more edits to Wikipediaes than one would expect assuming a linear trend. On average, countries with medium numbers of broadband Internet connections commit fewer edits than expected.
The same trend is expected when we think of translations the reason being that the languages which are being spoken in countries and regions having better broadband connectivity have more people interested in consuming information. So, the information in languages spoken in areas having better broadband connectivity will be in more demand than in the languages spoken in areas having lesser broadband internet connections.
Summary of the Paper titled "Digital Division of labor and informational magnetism: Mapping participation in Wikipedia"
The paper “Digital Division of Labor and Informational Magnetism” discusses the struggles over the ways people and organizations try to control information produced, reproduced, and used. The paper focuses on Wikipedia, which is the world’s largest and most used repository of user-generated content. The paper argues that digital mediations of spatial knowledge have compounded the subordination of local voices, erasing the positionality of the user and social contents under which knowledge is produced. The paper takes this situation as a starting point to investigate whether the Internet, with its mass participation, affords a potentially disruptive role in breaking the digital divisions of labor. The authors describe the data used in a study of Wikipedia’s geographies, which sought to explore the geographic distribution of Wikipedia content and contributors. Three types of data were used here: data about the location of Wikipedia articles, data about the origins of edits, and data about the geographic focus of those edits. Further in the paper it is explained that how the data were processed, and any limitations of the data. It also discusses the challenges of analyzing anonymous edits and the edits by registered editors and the methods used to geolocate those edits. After that the paper discusses the geographic distribution of edits committed to all Wikipediaes from different countries as measured by Wikimedia. The study found that countries in North America, Europe, and Asia had the highest number of edits, while Sub-Sharan Africa had the lowest number. The article also analyzed the propensity of people in any country to commit edits and found that North America, Europe, and much of Oceania stood out strongly compared with regions having medium participation levels and regions with very low levels found mostly in Sub-Saharan Africa. It further explores the factors that covary with the geography of participation in Wikipedia and offers insight into the geographies of participation and voice on the English-language version of Wikipedia. The article demonstrates that the availability of broadband connectivity is a central predictor of the spatial unevenness of participation. The authors use geocoded articles and origin locations of anonymous and registered edits to analyze the source locations, target location, and respective editing volumes. They investigate the geographies of local voice by looking at the volume of autochthonous content by region, analyzing the within- region-edits, and looking at trajectories or networks of editing over space. The authors conclude that large amounts of geospatial content show no sign of deterring people from further contributions and editing, and that North America and Europe commit more than they receive into their territories.
Hello everyone,
My name is Abhishek Bhardwaj and I am a sophomore at the University of Delhi. I am really excited to contribute to Wikimedia, especially this project. I hope this is the right place to communicate.