User Details
- User Since
- Apr 10 2021, 8:11 AM (158 w, 3 d)
- Availability
- Available
- LDAP User
- Aitolkyn
- MediaWiki User
- Unknown
Fri, Apr 19
15/04 - 21/04:
Ref.need experiments with different models (refer to slide#10 for results)
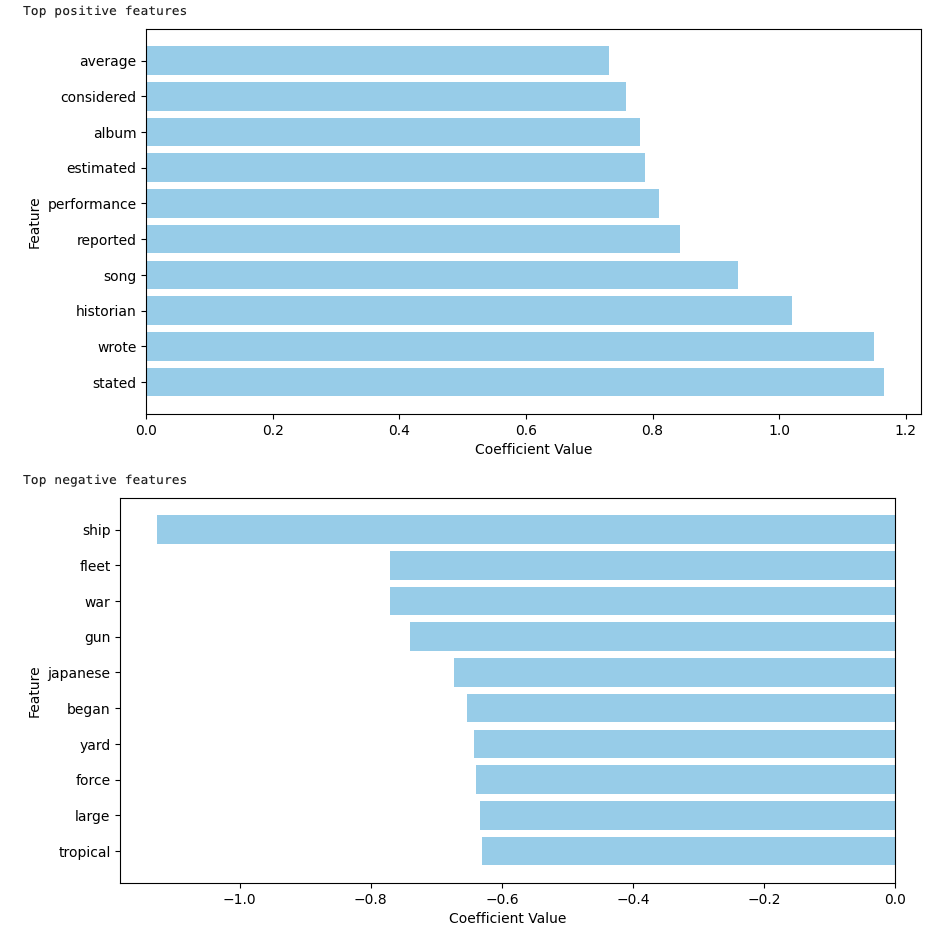
Ref.need feature exploration, e.g., num_words, section_name (refer to slide#8), below plots for Logistic Regression feature importance for positive/negative labels
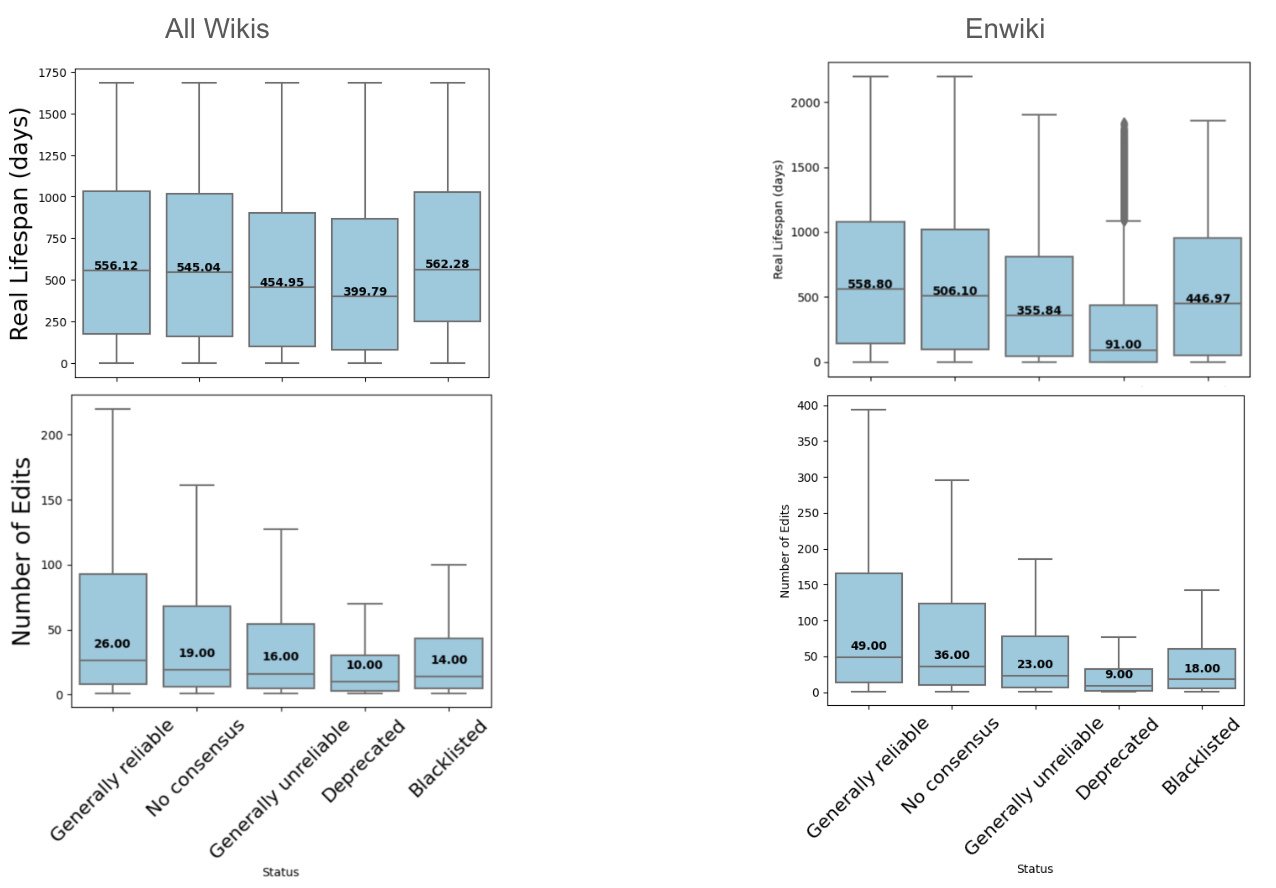
Ref.risk analysis of URL permanence to reliability label, example below:
Tue, Apr 16
Mon, Apr 15
@ssingh Thank you for checking! I get the following error when trying to access my tables:
08/04 - 14/04:
- ref.need experiments with BERT are continued with additional data cleaning, facing overfitting issues, experimenting on a sample of data following prev. work approach
- ref.risk extending data with URL permanence in terms of (lifespan of a URL on a page and number of edits)
- ref.risk analysis of ground-truth labels from enwiki perennial sources list
Fri, Apr 5
01/04 - 07/04:
- ref.need using the dataset we prepared, started experimenting with BERT for sentence classification into cited/uncited in enwiki
Sat, Mar 30
25/03 - 31/03:
- ref.need running baseline models for classification using 1) tf-idf, 2) sentence metadata, + logistic regression
- planning to run with LLMs next, studying hugging face NLP tutorials
Mar 22 2024
18/03-22/03:
ref.need
- found and fixed an issue with tokenized sentences -> updated the dataset
- Data: ~16M featured articles and ~4.4M extracted sentence (47% accompanied by a citation)
- brainstorming and planning for the classifier model
Mar 15 2024
11/03-15/03:
ref.need
- extend dataset with sentences from FAs of dewiki, frwiki, ruwiki, ptwiki, eswiki
- proportion of cited sentences among all ranges from 40-49% for enwiki, ruwiki, ptwiki, frwiki, is lower for eswiki (~35%) and lowest for dewiki (~20%)
- notebook available here: https://gitlab.wikimedia.org/repos/research/reference-quality/-/blob/research-notebooks/RN/extract-FAs.ipynb?ref_type=heads
Mar 8 2024
04/03 - 08/03:
- ref.need - add featured articles from dewiki, frwiki, ruwiki, ptwiki, eswiki (choice is based on the number of currently existing FAs)
- ref.need - [for enwiki] prepare dataset for the model with the following columns:
page_id, revision_id, section_name, sentence, paragraph, citation_label
where citation_label = 0, if sentence does not include a reference,
citation_label = 1, if sentence includes a reference
Mar 1 2024
26/02 - 01/03:
- onboarding
- ref. need - prepare featured articles data
- ref. risk - literature review (e.g., reverted revs examples, controversiality score) for our dataset specification
Aug 5 2023
The paper has been accepted to CIKM (short paper track).
Mar 10 2023
- We uploaded our work to arxiv: https://arxiv.org/abs/2303.05227
Jun 25 2022
20/06 ~ 24/06:
- extract user lifespan & analyze the lifespan of users vs. collaboration with experts
- manually check pages containing sources from external fake websites lists
- get dominant sources on wiki from the external lists
- finish collecting citation quality scores for the top dataset
Jun 17 2022
13/06 ~ 17/06:
- classify users into exposed and non-exposed in the new random & top datasets
- psm on collaboration between experts and non-experts on the new random and top datasets
- topic coverage of unreliable source lists (including perennials)
- finish collecting citation quality scores for the random dataset
Jun 10 2022
- add one more external source list (3. Snopes)
- visualize the intersection of the 3 lists and coverage of #3
- citation quality scores start collecting for top2021 dataset
Jun 4 2022
- search for external lists of unreliable sources ( e.g. Melissa Zimdars' fake news websites list )
- compute the coverage of wiki by external lists (1. zimdars and 2. daily dots) and compare with perennial source list
- setting up the environment for the citation quality scores collection
May 27 2022
23/05 ~ 27/05
- transfer collection of reference need scores to the server (API was too long)
- active user contributors to add perennial sources analysis
- complete the evolution of references in the perennial source list (the future trend is more positive compared to previous data)
May 20 2022
16/05 ~ 20/05
May 15 2022
It looks very useful, thank you very much!! I'll check this out
May 13 2022
09/05 ~ 13/05
- collect reference risk scores for the 2 datasets: random and top2021
- start collecting all the missing reference need scores
- pageviews for 'bad' sources before and after they are classified as 'bad'
- analyze the data collected so far (significance tests, distributions, plots)
May 6 2022
02/05 ~ 06/05:
- re-check the pageviews data for pages in multiple namespaces (namespace_id was added to pageviews_hourly in 2017)
- analysis of the reference quality of the most viewed pages' revisions
- get pages and collect revision data for two datasets: random and top-viewed
Apr 29 2022
25/04 ~ 29/04
- extract monthly top-viewed pages and get the pages' revisions at that time
- collect reference quality scores for the revisions of top-viewed pages
- aggregate pageviews for the references from perennial source list
- prepare presentation
Apr 22 2022
18/04 ~22/04:
- extract and analyze data from the pageviews table
- check the extracted results with the PageviewsAPI
- check PageviewsAPI
Apr 15 2022
11/04 ~ 15/04:
- perennial source list references lifespan and pageviews
- continued exploring PySpark