
User Details
- User Since
- Mar 6 2023, 4:48 PM (58 w, 3 d)
- Availability
- Available
- LDAP User
- Unknown
- MediaWiki User
- Anshika bhatt 20 [ Global Accounts ]
Apr 15 2023
Apr 3 2023
Mar 26 2023
Thank you for the correction. The authors present a case study of the translation of the featured article "Glacier National Park" from English to Japanese. They highlight the role of multilingual discussion in identifying and resolving translation issues, such as cultural and linguistic differences. For instance, the authors note that certain terms like "neuroscience" do not have exact equivalents in Japanese and that the Japanese language has multiple words for "brain" depending on the context.
Mar 23 2023
Hello, @awight and @Simulo Here is my submission for this task Github repository. I have checked the accuracy of all the other CSV files mentioned in task #T331201 As @Abhishek02bhardwaj and @Ahn-nath mentioned that my CSV file was not getting 100% accuracy, so I went back and fixed the code. Here are my observations for the following CSV files:
CSV file compared: supported_pairs.csv
Accuracy percentage: 100%
CSV file compared: cx_server_parsed.csv
Accuracy percentage: 100%
CSV file compared: supported_language_pairs.csv
Accuracy percentage: 0.85%
Reason: Upon analyzing the results, it seems that there is a disparity in the accuracy due to the handler files not being
handled by @JaisAkansha 's code. This is resulting in mismatched results for files using Google.yaml and Yandex.yaml,
even for the ones where the source language is incorrect. I think it's important to address this issue in order to achieve consistent accuracy across all files.
CSV file compared: supported_language_pairs.csv.
Accuracy percentage: 0.85%
Reason: After reviewing the code, I observed that it doesn't seem to consider the preferred engines or the mt-
defaults.wikipedia.yaml file. Additionally, it appears that non-standard YAML files, like Google and Yandex, are being
ignored. This could be the reason for the significant difference in total lines between the scraper output and the handler
files.
CSV file compared: supported_pairs.csv
Accuracy percentage: 100%
CSV file compared: langs.csv
Accuracy percentage: 100%
Mar 22 2023
Mar 21 2023
Hello, @awight I'm working on the task to compare data from two sources in our project, but I've encountered a couple of issues that I'm not sure how to handle.
Mar 19 2023
@awight Thank you so much for your time and guidance. I wanted to let you know that I made the changes you suggested in the code. I have also added the necessary tests to ensure that the code is working as expected. Could you please take a look and let me know if there are any further changes I should make? Thank you for your feedback, it was very helpful.
Mar 18 2023
Thank you @Simulo for giving us this valuable feedback. Based on your input, I made some changes to the survey questions, which I believe have improved the clarity and relevance of the survey.
Mar 17 2023
Hello, @awight and @Simulo This is my submission for this task https://github.com/anshikabhatt/Extract-cxserver-configuration-and-export-to-CSV. Please have a look and give me your valuable feedback on this. Thanks in advance.
Mar 16 2023
Mar 13 2023
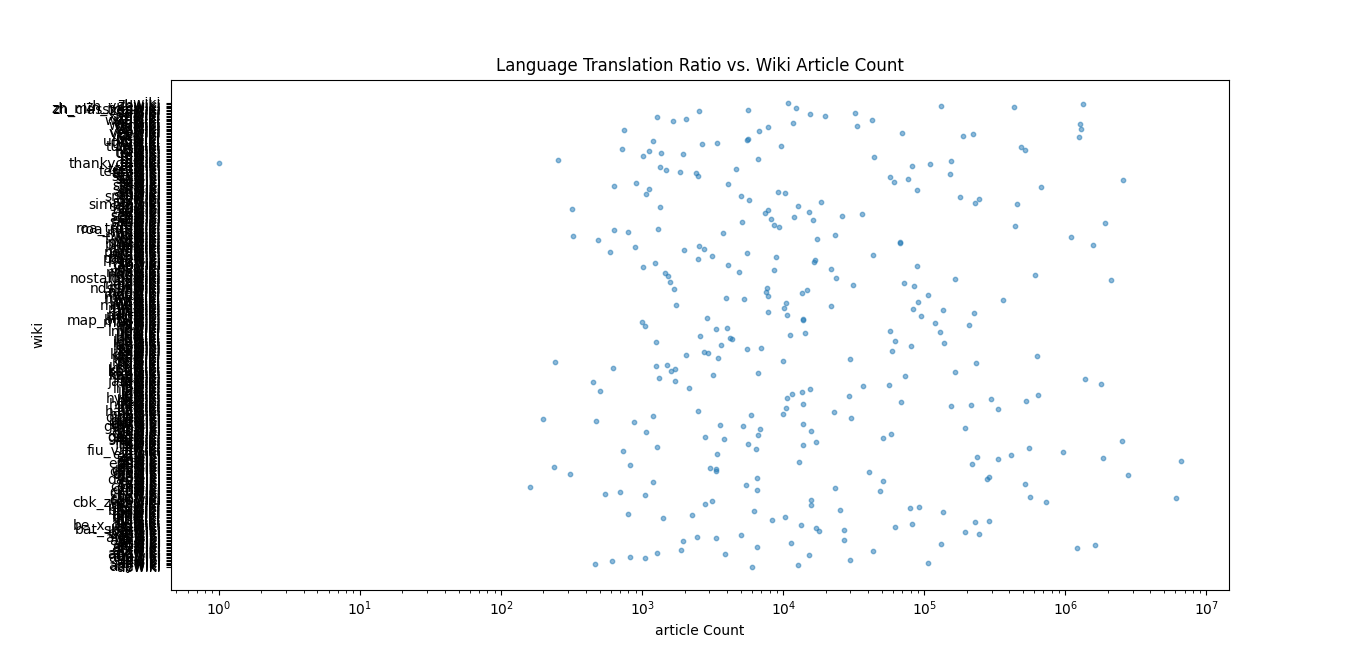
@awight @Simulo For this task, I have tried to create a tool to track the evolution of language support for machine translations (and other software features) over time. To do this, I created a new Git repository containing a CSV file with a simple data structure (city and temperature). I made several Git commits with changes to this data, including adding and removing rows.
Mar 12 2023
Hello, @Simulo @awight I am trying to write code in python to create a scatterplot diagram of languages and I think there may be an issue with the API response format. I am having an error that the translations list might contain strings instead of dictionaries. Please provide guidance on how to resolve the issue. Thank you in advance.
@Abhishek02bhardwaj I think to use the handler.js file to access the source and target languages, you would need to modify the code in the supported_pairs.py file to include the logic to parse the handler.js files. Please correct me if I am wrong.
hey, @Abhishek02bhardwaj can you tell me about the issue in detail? where exactly you are facing issue?
Mar 11 2023
Hello, I'm in the process of recording my work in progress contribution, but I'm not sure which URL to include in the submission form. I was wondering if anyone knows which link to use? I want to make sure that I'm providing the most relevant and useful URL. @awight @Simulo @srishakatux
Mar 10 2023
Hello, @awight I have been working on this project and wanted to clarify some details.
Mar 9 2023
Mar 8 2023
Mar 7 2023
I wanted to reach out to you to ask if you would willing to provide me with some feedback and review on the task I worked on and give me your valuable suggestions. I am open to any suggestions you may have, and I am committed to using your feedback to make improvements. @awight @Simulo @srishakatux @Aklapper
Digital Division of labor and informational magnetism: Mapping participation in Wikipedia.
In their 2015 paper “Digital Divisions of labor and informational magnetism: mapping participation in Wikipedia,” Graham, Straumann, and hogan explore the ways in which participation in Wikipedia is shaped and highly influenced by digital divisions of labor and the informational magnetism of certain topics.
A digital division of labor refers to the unequal distribution of labor and skills required for digital work, particularly in the online environment. It can result in unequal access to and control over digital resources. Similarly “Informational magnetism” refers to the phenomenon where certain individuals or groups have a disproportionate amount of influence or power in online communities, such as Wikipedia. As it is referring to the ability of certain articles or topics to gain more attention and contribution than others leading to unequal distribution of labor and contributions in the online community.
Also, they use a combination of quantitative and qualitative methods to analyze the distribution of editors across language versions of Wikipedia.
The authors find that participation in Wikipedia is highly uneven, with a small group of highly active editors responsible for a disproportionate amount of content creation. This editor tends to concentrate their editing activity around certain topics. They also find that there is a significant degree of information magnetism, with certain articles attracting a great deal of attention and activity while others are largely neglected.
Based on the paper “Digital division of labor and informational magnetism: mapping participation in Wikipedia,”. We can expect to see certain patterns in a dataset of translations between different Wikipedias. There are several potential implications for translators.
• Hypothesis 1
Unequal distribution of contribution: As the study found in the paper that a small number of editors were responsible for the majority of articles and topics on Wikipedia, we might expect to see that certain language communities have a higher chance of participation in Wikipedia and are therefore more likely to contribute translations. This suggests that there is maybe a similar concentration of translation work among a small group of translators.
Informed guess: as we all know translation requires a good level of proficiency and understanding of both the source and targeted languages, it is highly possible that only a small group of individuals who are bilingual will be able to contribute to the translation of Wikipedia content, similarly to the small group of highly active editors based on what we know from the paper. We can guess translation requires proficiency in two languages, only a small group of people who know more than one language will be able to translate.
• Hypothesis 2
Informational magnetism: The distribution of contribution may be influenced by “Informational magnetism”. As the author said, “a small number of contributors to Wikipedia have a large impact on its content". The presence of informational magnetism may impact the accuracy and quality of translations. Because of that the result may be biased or inaccurate in articles. Translators will need to be aware of these issues and make changes in their translations. The contributions of high–profile editors were more likely to be adopted by other editors. It also means high–profile translators may have a disproportionate impact on the translation community, and their work may be more likely to be recognized and adopted by others. The article that has already been translated extensively between different Wikipedias are more likely to attract further translation activity.
Informed guess: if an article has already been translated extensively, it is likely more possible that it has received a lot of attention and is, therefore, more likely to be of high quality making it more attractive for potential translators.
@Simulo hello, can you please clarify where should i submit the summary for this task? any specific formate or method of submission.
@awight hello, can you please clarify where should I send the review? any specific formate or method of submission.
hello, please clarify where to write the summary .
Hello everyone, My name is anshika and I am excited to be joining this Wikipedia project. I am eager to contribute to help further develop this project. I am looking forward to contributing to this project.