User Details
- User Since
- Mar 10 2020, 3:22 PM (214 w, 2 d)
- Availability
- Available
- LDAP User
- Unknown
- MediaWiki User
- Dibyaaaaax [ Global Accounts ]
Aug 6 2020
I tested out some of the above-mentioned models using a testing dataset (with ~150k items) that is completely different from the data the model was trained on. It was observed that all those models performed more or less the same on the new dataset. Since none of these models had a significantly better performance compared to others, and all other models in drafttopic are trained on a balanced dataset using GBC, we have decided to stick to the same for Wikidata too.
Aug 4 2020
| Classifier | GradientBoosting |
| Parameters | n_estimators=150 max_depth=5 max_features="log2" learning_rate=0.1 |
| Number of Samples | 63961, imbalanced samples |
| Vocab Size | 50000 |
| Embeddings dimension | 50 |
| Classifier | Fasttext |
| Parameters | loss=ova epoch=25 dim=50 lr=0.1 pretrainedVectors=word2vec/wikidata-20200501-learned_vectors.50_cell.50k.vec minCount=1000000 |
| Number of Samples | 63961, imbalanced samples |
| Pretrained vectors- vocab size | 50000 |
| Pretrained vectors- Embeddings dimension | 50 |
| Classifier | Fasttext |
| Parameters | loss=ova epoch=25 dim=50 lr=0.1 pretrainedVectors=word2vec/wikidata-20200501-learned_vectors.50_cell.vec minCount=1000000 |
| Number of Samples | 63961, imbalanced samples |
| Pretrained vectors- vocab size | 10000 |
| Pretrained vectors- Embeddings dimension | 50 |
Jul 30 2020
| Classifier | Fasttext |
| Parameters | loss=ova epoch=25 dim=50 lr=0.1 pretrainedVectors=word2vec/wikidata-20200501-learned_vectors.50_cell.50k.vec minCount=1000000 |
| Number of Samples | 255785, balanced samples (atleast 4000 per label) |
| Pretrained vectors- vocab size | 50000 |
| Pretrained vectors- Embeddings dimension | 50 |
| Classifier | Fasttext |
| Parameters | loss=ova epoch=25 dim=50 lr=0.1 pretrainedVectors=word2vec/wikidata-20200501-learned_vectors.50_cell.vec |
| Number of Samples | 63944, balanced samples |
| Pretrained vectors- vocab size | 10000 |
| Pretrained vectors- Embeddings dimension | 50 |
Jul 29 2020
| Classifier | GradientBoosting |
| Parameters | n_estimators=150 max_depth=5 max_features="log2" learning_rate=0.1 |
| Number of Samples | 63944, balanced samples |
| Vocab Size | 50000 |
| Embeddings dimension | 50 |
Jul 28 2020
Subsequent comments will have the performance reports for different Wikidata models. This is to get an idea about the changes in their performance while varying different factors like classifier (Fasttext vs GradientBoosting), vocab size, training data size, etc.
Sort order of Wikidata statements
We decided to order the Wikidata statements instead of randomizing them, for the reasons @Isaac mentioned above. For that, the order of properties is collected from here (SortedProperties) using the API. We then sort the statements based on their properties using the list of SortedProperties as reference.
There were some statements with properties that do not appear in the SortedProperties list. Those statements are simply sent to the end of the list, making them appear after all other statements that are on their correct position.
Jul 13 2020
There are some Wikidata items that represent Wikipedia pages that aren't articles. Eg. Q8207058 sitelinks to Portal:Earth Sciences in English Wikipedia (same case for other languages).
Mar 12 2020
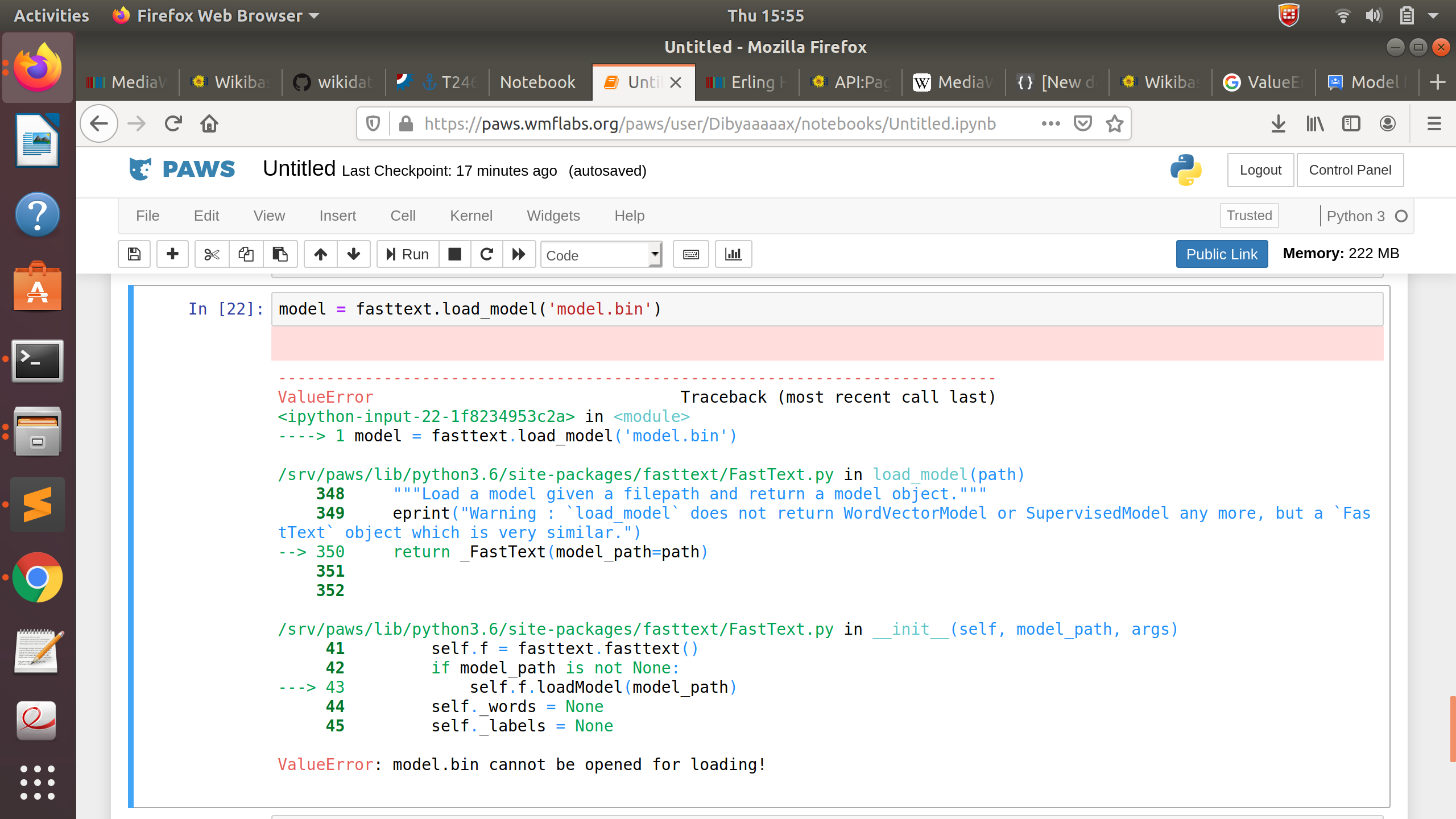
Could someone help me with this error?