
User Details
- User Since
- Nov 30 2019, 1:47 PM (228 w, 3 d)
- Availability
- Available
- LDAP User
- Unknown
- MediaWiki User
- HAKSOAT [ Global Accounts ]
Sep 26 2020
Yes. The models have been built and there was supposed to be a trial deployment. I think it was @Pavol86 that did the work of reducing memory footprint though.
Aug 11 2020
In the last week, I have tried understanding how the various APIs for ORES, Wikidata and Link based predictions work. I have also come up with a document containing possible structure the table to be created before analysis.
Jul 13 2020
Discussion can bee found here: https://phabricator.wikimedia.org/T248480
I decided to go with the non-cjk lexicon but with the regex for matching cjk text much higher up this list. This provided a balance in speed, so non-cjk lexicon doesn't run so slow on cjk text.
Jun 12 2020
Pull request: https://github.com/halfak/deltas/pull/14
Update: I ended up creating a lexicon to be used for cjk-dominant text and another to be used for non-cjk dominant text.
May 16 2020
I have been able to work on English idioms and excited to say that the speed has been improved by a large margin. Before now, we were simply piping together a bunch of English Idioms and this was quite inefficient.
May 14 2020
I checked the regex package. While it works great for the unicode scripts, it's reducing performance by about 40%. I checked the implementation of the library in other to see if I could get some inspiration and pull that into ours, but I see a lot of C code that I do not understand. Looks like I'll have to work with specifying the code ranges using the built-in re package instead.
May 11 2020
Thanks for linking to the regex package. I spent some time working with it and it is quite amazing. I think we can make use of it.
May 7 2020
I opened a pull request for improving the regex used by wikitext_split on the deltas package.
May 6 2020
In the last week, I have worked extensively on improving my understanding of regex engines and how to write optimized regular expressions.
Apr 28 2020
Thanks for this. I currently don't know a lot of Java, just Python and PHP. So I'll need as much help as I can get.
Thanks for this @TJones . Yes, a lot of the time spent was due to the overhead calling the API. I don't think combining 100 Alan Turings will help though as that was just to profile performance. In the real use case, we will actually only be tokenizing a single article (or a single document depending on the scenario). Hence, we can't combine at that point.
Apr 24 2020
I am currently reading up different resources on writing efficient regex so I can figure out possible improvements to the regex in use.
I have worked to convert the regex from being Python to Java compatible as seen here.
Apr 6 2020
Great. Overall, not as bad as initially thought.
Apr 2 2020
@Halfak Any update on this? The profiling script.
Mar 5 2020
I think its valuable too. I hope the performance didn't drop either?
Feb 14 2020
Hello @Halfak I think this task requires PRs on the revscoring and articlequality repos.
Feb 11 2020
@Halfak I'll like to assign myself this task. Can I go ahead?
Jan 3 2020
@Halfak Please take a look at my Pull Request: https://github.com/wikimedia/revscoring/pull/466
Thanks for this
Dec 27 2019
Hello @Halfak I hope you are having a good time this festive season. So I'm about to parse the text here: https://en.wiktionary.org/wiki/Category:English_idioms I'd normally use the requests and beautifulsoup combo. But I believe there's a tool that does this already. I tried importing pywikibot, but it looks like it needs some initial user configurations. Is there any other method of doing this? Is there a means to use pywikibot for this purpose that I'm not aware of yet?
Dec 24 2019
Hello @Halfak I'd like to claim this task.
Dec 13 2019
Thanks @AVasanth_WMF The tests now pass
Dec 12 2019
Oh. I think "test" is the wrong word here. I meant "run". So how do I run the code and see my changes in action?
Ubuntu 19.10
The build failed on Travis:
Hello @Samwalton9 I just made a PR:
Dec 11 2019
Great. It's all coming together in my head now. How do I get to test my code changes though, to ensure that they work. I'm about to assign myself this task and commence.
So, I'm considering adding a function to that module that fetches the idioms using mwparserfromhell and returns them probably as a list. What do you think of this approach?
I saw this https://en.wikipedia.org/wiki/Wikipedia:Extended_image_syntax I think it has all of the extended Wiki markups for images.
Thanks for the pointers @Halfak I have joined the channel on IRC. I'll look at the pointers and get back to you.
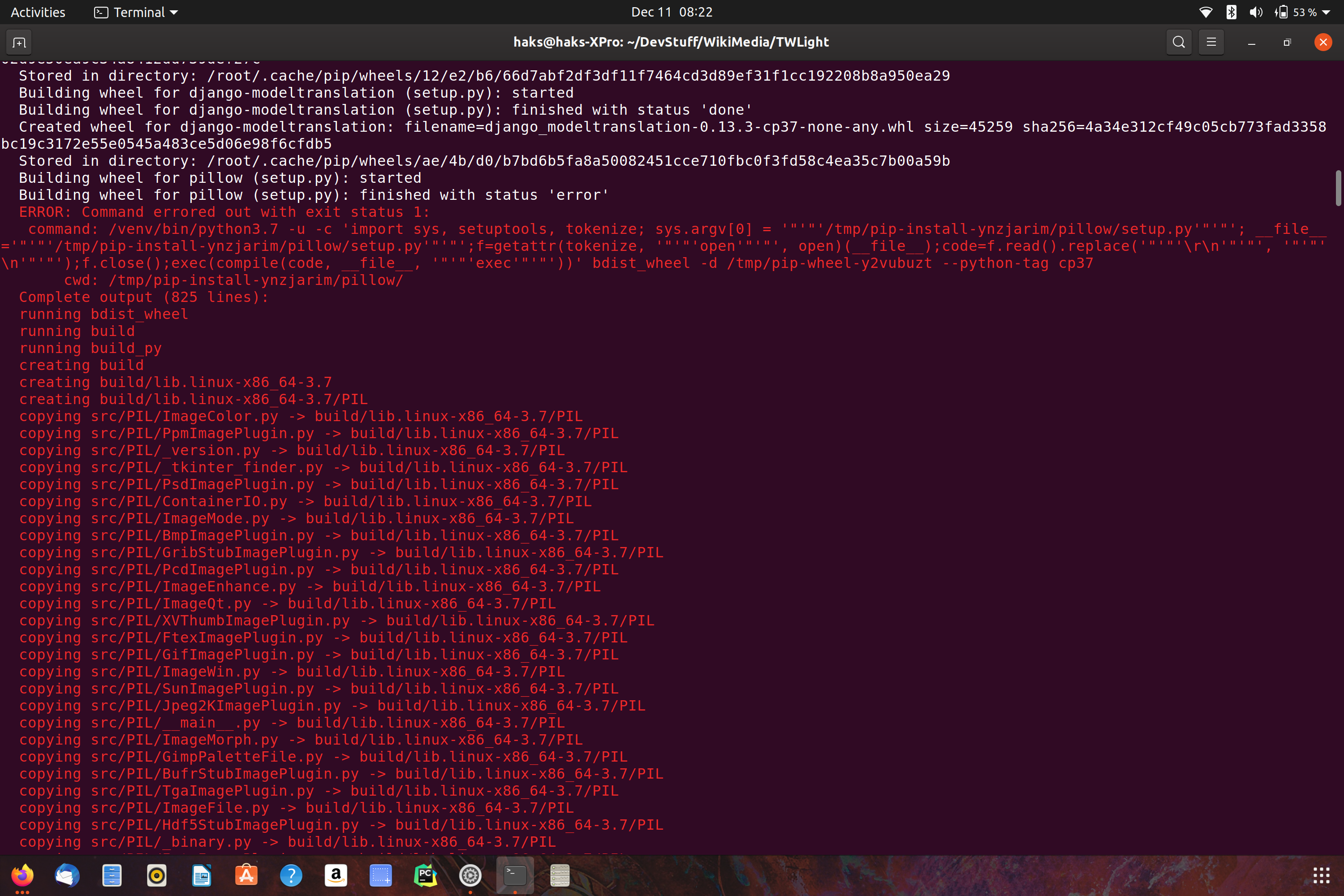
Thanks @AVasanth_WMF for the pointer. I'm trying to run docker-compose build && docker-compose up on my computer, but it comes up with errors and a very long traceback.
Dec 10 2019
I can do some research on that. Thanks for the swift reply @Halfak I'll get back to you.
Hello @Harej Is it possible for me to get more guidance for this task?
Hello @Harej This is something I'll like to work on.
Hello @Samwalton9 I'll like to work on this task. But I'm finding it a bit difficult figuring out the file that causes this behavior. I'll appreciate some help.
Dec 7 2019
@Dvorapa I realized that the argument for namespace doesn't even send to redirect. I made use of the example python pwb.py redirect double -namespace:6
Dec 4 2019
Thanks
Thanks @Dvorapa I've spent some time first checking another script, then the redirect script. I see that the script has the ability to pass namespaces to RedirectGenerator. But the value is not being extracted from the arguments as expected. So I'm to get it to extract and pass to RedirectGenerator. Am I thinking in the right direction?
Dec 3 2019
Hello @Dvorapa I am new here. Can I work on this? Though I do not fully understand the problem yet.
I'd like to work on this.