User Details
- User Since
- Dec 2 2015, 11:01 PM (437 w, 5 d)
- Availability
- Available
- LDAP User
- Unknown
- MediaWiki User
- OlafJanssen [ Global Accounts ]
Feb 7 2024
Oct 6 2023
@TheDJ Thanks for creating this ticket so rapidly after me reporting it on the help pages! Much apprectiated!
May 16 2023
Apr 11 2023
Mar 9 2023
I used to have that same error of my wikibase.cloud https://kbtestwikibase.wikibase.cloud/, for which I originally reported T310419 (issue is closed now)
Feb 1 2023
I've a question: the URL of the Wikidata query example page is currently https://www.wikidata.org/wiki/Wikidata:SPARQL_query_service/queries/examples
Jan 18 2023
Aug 18 2022
If $wgWBRepoSettings['statementSections'] is set for cloud wikis, will it be possible to overrule this setting by adding a custom property ordering page such as https://kbtestwikibase.wikibase.cloud/wiki/MediaWiki:Wikibase-SortedProperties ?
Aug 1 2022
Jul 20 2022
Yes, I support the idea to include this extension in Wikibase.cloud and in the official Docker.
Jul 5 2022
@I_is_chan : thanks! Adding such page to my Wikibase indeed did the trick: https://kbtestwikibase.wikibase.cloud/wiki/MediaWiki:Wikibase-SortedProperties , resulting in an accordingly sorted page, eg https://kbtestwikibase.wikibase.cloud/wiki/Item:Q29
Jun 30 2022
Jun 28 2022
I think I might have hit the same (or at least similar) bug: since pm 4 days any changes in Ps and Qs (including labels, descriptions, aliases) I make via the GUI on https://kbtestwikibase.wikibase.cloud are not when running SPARQL queries.
Jun 24 2022
@Tarrow Many thanks for pointing this out, I totally overlooked / forgot this 'legacy' admin account, which is indeed one of my common user names.
Jun 17 2022
Jun 16 2022
Jan 6 2021
Dec 1 2020
Nov 23 2020
Nov 20 2020
Jul 2 2020
Just for info: I just started work on 3 articles in English explaining the approach, tools and outcomes of my KB-statistics work. It'll be basically a written out & illustrated version of https://commons.wikimedia.org/wiki/File:Het_meten_van_hergebruik_van_de_collecties_van_de_Koninklijke_Bibliotheek_via_de_Wikimedia-platformen_-_18-06-2020.pdf
Jul 1 2020
Next two things that might be improved:
Re: It may also be very interesting to ask Olaf what he would *like* to measure
Jun 24 2020
Yes, very nice! I (obviously) support this idea, but you might indeed want to summarize it, because it's overdetailed at some points.
May 5 2020
Apr 10 2020
Excellent, seems to work very well again. Did some testing for multiple/different URLs, all seems well, no more weird "caching".
Apr 8 2020
Dec 23 2019
I've checked it lately. I'm using a hosted WB-instrance from wbstack.com, so the need for a self-hosted instance for experimentation purposes has decreased/vanished.
Nov 21 2019
Nov 20 2019
Nov 14 2019
Scans and full-texts available at https://www.delpher.nl/nl/tijdschriften/results?cql%5B%5D=%28ppn+exact+%22410763969%22%29&coll=dts&sortfield=date
Nov 6 2019
We can also try doing it via the Webscraper-plugin for Chrome browser - https://chrome.google.com/webstore/detail/web-scraper/jnhgnonknehpejjnehehllkliplmbmhn
Nov 5 2019
I'm an expert on these collections, AMA
I'm an expert on this collection, AMA
I'll need at least 90 minutes for this workshop, preferably more....
Oct 31 2019
Aug 28 2019
@SandraF_WMF Yes, I also showed her that as well. The idea of ISA is to show her an easier tool, which acts better on mobile. Also, the idea of running campaigns is of added value compared to the WMC-interface
Aug 27 2019
Aug 23 2019
Aug 22 2019
Yes, I was thinking of requesting this feature as well.... so I very much support this idea.. I'll check out this new feature as soon as it comes live
Aug 21 2019
Aug 14 2019
Slides on Commons: https://commons.wikimedia.org/wiki/File:Wikimedia_APIs.pdf
Aug 12 2019
Aug 9 2019
One more thing: How should be go about implementing the updated line of code
Aug 8 2019
OK, thanmk you, I'll use the approach you suggest, I've put it in my notebook by now
@Chicocvenancio Ah, I see... although my appraoch seems to work as well (by accident?).
@Chicocvenancio Thanks for elegant your solution. I looked at https://stackoverflow.com/questions/10606133/sending-user-agent-using-requests-library-in-python
@Chicocvenancio Thanks for that !pip tip, I was not aware of that
Jul 18 2019
Jul 8 2019
Jun 17 2019
This item can be closed, I know by now how to to achieve the goals mentioned using OpenRefine indeed.
May 23 2019
Deze taak is uitgevoerd/compleet, ik heb sinds de laatste Techstorm en GLAMwiki Tel Aviv zoveel meer over Wikidata, datamodelering en Sparql geleerd (dankzij en hulde aan de gemeenschap!) dat bovenstaande geen echte uitdagingen/vragen meer zijn.
Oct 27 2018


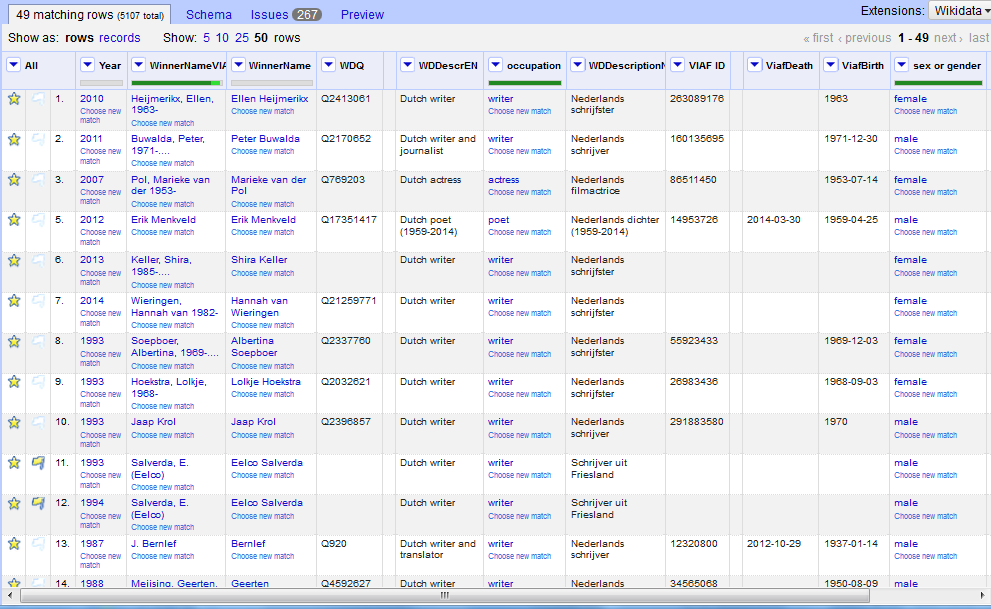
Example of item created https://www.wikidata.org/wiki/Q57826098
Excel with winners of Dutch literary awards 1881-2015 https://drive.google.com/file/d/1-T0mrZcmhFuSVNDQ8v3xM75RHKLs9K5g/view?usp=sharing