User Details
- User Since
- May 4 2020, 8:37 PM (207 w, 2 d)
- Availability
- Available
- IRC Nick
- pavol
- LDAP User
- Unknown
- MediaWiki User
- Pavol86 [ Global Accounts ]
Mar 2 2021
Feb 23 2021
Feb 22 2021
Feb 18 2021
Feb 16 2021
Feb 14 2021
Feb 13 2021
Feb 7 2021
Feb 4 2021
Jan 26 2021
Jan 14 2021
Jan 13 2021
Jan 4 2021
Dec 26 2020
Dec 24 2020
Aug 17 2020
@leila , If this task is still opened I would like to help.
Jul 23 2020
@VulpesVulpes825 thank you for the recommendation! I do not speak any of the languages so I am "best guessing" all the way :). The CJK tokenization should be part of the deltas library at the end - https://github.com/halfak/deltas . I prepared the code to be merged(pull request) with deltas and I have a call with @Halfak today. I will keep you updated..
FINAL NOTES (hopefully :) ):
Japanese:
- I did haven't tried SudachiPy as I saw poor performance stats, It is the only JP tokenizer that I was able to get running just by "pip install" without any additional instructions
- SudachiPy model loads quickly:
jp_sudachi model load time: 0.03719305992126465
- SudachiPy has 3 splitting modes A|B|C (https://github.com/WorksApplications/Sudachi ):
Sudachi provides three modes of splitting. In A mode, texts are divided into the shortest units equivalent to the UniDic short unit. In C mode, it extracts named entities. In B mode, into the middle units.
- I decided to use "mode A" - after checking splitting results
- SudachiPy has 3 possibilities for dictionary small | core[default] | full (https://github.com/WorksApplications/SudachiDict):
Small: includes only the vocabulary of UniDic Core: includes basic vocabulary (default) Full: includes miscellaneous proper nouns
- there is only a slight difference in the performance of tokenizer with each dict. (small slightly faster than core, etc.), see:
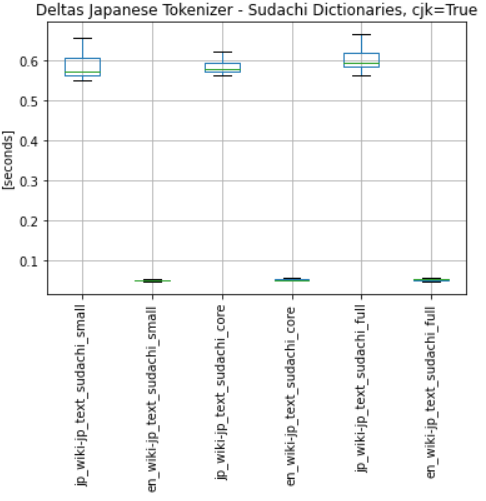
- I recommend use of full dict with split mode A, to download/use full dict:
pip install sudachidict_full sudachipy link -t full
Jul 15 2020
@Halfak I need your feedback on following. According to our call last week I did following :
- make the ch, jp, ko tokenizer decision more explicit in the code
- add "# noqa" to lines that should have >85 chars - as a workaround for flake8/pep8 test
- performance tests : run the code 100-1000x times on the same article and compare performance between prev/new version, cjk tokenization True/False
3.1 I tested the performance of original deltas tokenizer, see following boxplots - y-axis marks the type of wiki and type of text (EN wiki with EN text, Chinese wiki with Chinese text,... EN wiki with Chinese text, etc..)
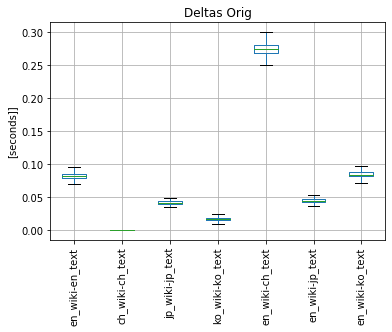
3.2 I found out that the loading of the Chinese tokenizer model is a bottleneck, so I tested pkuseg, thulac, jieba on Chinese wiki with Chinese text. Jieba is the only tokenizer that needs to be initialized only once and then it is kept in memory. Pkuseseg and Thulac take 2-3s to initialize. Model load of each tokenizer (including jap and kor)
Jul 8 2020
NOTE1: I have some issues with creating a pull request for delta package, we should be able to resolve it with Aaron...
NOTE2: this is the application + explanation of the code, I thank @jeena and @VulpesVulpes825 for their ideas, we will check the performance of other dictionaries/tools, but for now I wanted to have a working basic CJK tokenizer..
Jun 21 2020
Note
Export from jupyter notebook after I struggled with JapaneseTokenizers I decided to get at least 1 working - hardest part is to find some free segmented dataset, now I know why this task is still opened :) - I forgot that nothing is free in Japan and OpenSource is a very new concept.. (my exp. ...)
Jun 19 2020
@VulpesVulpes825 thank you for your response. Do you know if there are any datasets/dictionaries that are used for benchmarking of tokenization methods?
Jun 17 2020
I can see that this thread is quite old, so first of all only couple of notes that we can talk about with Aaron on Thursday call..
Jun 8 2020
Results of dimensionality reduction on the testing(sampeld dataset):
| model name | quantized | vocabulary cutoff | dimensions | retrain | qnorm | f1 micro | f1 macro |
| enwiki.articletopic | True | 10k | 10 | False | False | 0.639 | 0.45 |
| enwiki.articletopic | True | 10k | 10 | True | False | 0.649 | 0.468 |
| enwiki.articletopic | True | 10k | 10 | False | True | 0.639 | 0.451 |
| enwiki.articletopic | True | 10k | 10 | True | True | 0.65 | 0.468 |
| enwiki.articletopic | True | 10k | 25 | False | False | 0.693 | 0.54 |
| enwiki.articletopic | True | 10k | 25 | True | False | 0.698 | 0.557 |
| enwiki.articletopic | True | 10k | 25 | False | True | 0.693 | 0.54 |
| enwiki.articletopic | True | 10k | 25 | True | True | 0.698 | 0.557 |
| enwiki.articletopic | True | 10k | 50 | False | False | 0.703 | 0.558 |
| enwiki.articletopic | True | 10k | 50 | True | False | 0.706 | 0.573 |
| enwiki.articletopic | True | 10k | 50 | False | True | 0.704 | 0.558 |
| enwiki.articletopic | True | 10k | 50 | True | True | 0.706 | 0.576 |
| enwiki.drafttopic | True | 10k | 10 | False | False | 0.598 | 0.406 |
| enwiki.drafttopic | True | 10k | 10 | True | False | 0.61 | 0.425 |
| enwiki.drafttopic | True | 10k | 10 | False | True | 0.598 | 0.407 |
| enwiki.drafttopic | True | 10k | 10 | True | True | 0.611 | 0.426 |
| enwiki.drafttopic | True | 10k | 25 | False | False | 0.651 | 0.493 |
| enwiki.drafttopic | True | 10k | 25 | True | False | 0.656 | 0.508 |
| enwiki.drafttopic | True | 10k | 25 | False | True | 0.652 | 0.494 |
| enwiki.drafttopic | True | 10k | 25 | True | True | 0.654 | 0.507 |
| enwiki.drafttopic | True | 10k | 50 | False | False | 0.662 | 0.512 |
| enwiki.drafttopic | True | 10k | 50 | True | False | None | None |
| enwiki.drafttopic | True | 10k | 50 | False | True | 0.663 | 0.51 |
| enwiki.drafttopic | True | 10k | 50 | True | True | None | None |
May 30 2020
@aaron, I need help with understanding the results and if it makes sense what I did to test vocabulary sizes.
(in following I use brackets to list file names options)
(i) Does it make sense what I did?
- As I mentioned in previous update I extracted word2vec vocab with sizes [10k,25k,50k,75k,100k] using gensim limit parameter and then using fasttext quantize function => I create 10 word2vec datasets names w2v_[gensim,quantized][10k,25k,50k,75k,100k].kv
- I created new file for each word2vec dataset in drafttopic\drafttopic\feature_lists : enwiki_[gs,qt][10k,25k,50k,75k,100k].py
- I added new commands to drafttopic\Makefile
- I ran the commands related to enwiki except "tuning" - I killed the process when I saw it uses gridsearch and it will try 16 parameter combinations :)
(ii) Results explanation
- Statistics - UNDERSTAND
- rates/match_rate/filter_rate - DONT UNDERSTAND (fractions from the dataset?)
- recall/precision/accuracy/f1/fpr/roc_auc/pr_auc - UNDESRTAND
- !recall/!precision/!f1 - DONT UNDERSTAND (what does the "!" mean?)
(iii) Summary
Difference between classification stats of 10k and 100k versions are small, but quantized 10k word2vec dataset performs a bit better than gensim limited 100k dataset, eg:
| f1 micro | f1 macro | |
| enwiki.articletopic_gs100k | 0.681 | 0.512 |
| enwiki.articletopic_qt100k | 0.69 | 0.533 |
| enwiki.articletopic_gs10k | 0.672 | 0.504 |
| enwiki.articletopic_qt10k | 0.685 | 0.53 |
| enwiki.drafttopic_gs100k | None | None |
| enwiki.drafttopic_qt100k | 0.645 | 0.485 |
| enwiki.drafttopic_gs10k | 0.627 | 0.454 |
| enwiki.drafttopic_qt10k | 0.641 | 0.478 |
May 26 2020
Short update
- initial DraftTopic testing issues[resolved] : (i) module versions issues, (ii) default MiniConda python3.8 issue - 3.8 has some issues with GenSim and other modules used in DraftTopic, (iii) calculations are memory/CPU intense (I created virtual env. on a machine I don't use), (iv) sample dataset too big, downloading crashed multiple times - Aaron provided smaller version
- I created word2vec GenSim models according to python-mwtext : https://github.com/mediawiki-utilities/python-mwtext/blob/master/mwtext/utilities/word2vec2gensim.py
- I created limit = [10k,25k,50k,75k,100k] dictionary size models from provided preprocessed text as a baseline with :
model = KeyedVectors.load_word2vec_format(input_path, limit=limit)
- I created quantized models with cutoff dictionaries
(again issue with Python 3.8 so I ended up with using FastText command line/terminal commands)
model = fasttext.train_supervised(input_path, **params) model.quantize(input=train_data, retrain=True, cutoff=[10k,25k,50k,75k,100k])
https://github.com/mediawiki-utilities/python-mwtext/blob/master/mwtext/utilities/learn_vectors.py
- as I had so many issues with python 3.8 I switched to 3.7.2 -> fewer issues
- I added commands to Makefile to create [10k,25k,50k,50k,75k,100k] versions of enwiki.balanced_article_sample.w_article_text.json and enwiki.balanced_article_sample.w_draft_text.json
- I created cached versions of sampled datasets
- I trained the models with new balanced cached datasets - I didn't notice the model training command is calling "drafttopic.feature_lists.enwiki.drafttopic" which has a hardcoded word2vec GenSim model/dictionary (.kv) - "enwiki-20191201-learned_vectors.50_cell.100k.kv"
- I followed KISS principle ("keep it simple, stupid") and created "drafttopic.feature_lists.enwiki" file per word2vec dictionary, eg. :
drafttopic.feature_lists.enwiki_gs100k (referring to gensim limited model to 100k dict) drafttopic.feature_lists.enwiki_qt100k (referring to quantized model with cutof=100k) drafttopic.feature_lists.enwiki_gs75k ...
May 6 2020
I went through the documentation for gensim and fasttext(very limited info), and a lot of other pages.. :) . To proceed further: what is the goal of python-mwtext?
May 4 2020
according to Medium article (but this issue is common on forums) :