
User Details
- User Since
- Nov 1 2022, 1:30 PM (77 w, 1 d)
- Availability
- Available
- LDAP User
- Stevemunene
- MediaWiki User
- SMunene-WMF [ Global Accounts ]
Today
Yesterday
Tue, Apr 23
run an apt update on the hadoop workers
stevemunene@cumin1002:~$ sudo cumin A:hadoop-worker 'apt update' 106 hosts will be targeted: an-worker[1078-1175].eqiad.wmnet,analytics[1070-1077].eqiad.wmnet
To upgrade the version
Thu, Apr 18
The deployment was successful and we are now running datahub v0.12.1
Wed, Apr 17
Could we also run a sanity Spark test? See T344910#9331963 for an example that jsut runs two Spark SQL queries.
Ran into the same issue as previously even with the BOOTSTRAP_SYSTEM_UPDATE_WAIT_FOR_SYSTEM_UPDATE set to default. The datahub-main-system-update-job-lnk9h ran to completion and successfully reindexed the indices, then the rest of the pods datahub frontend, mae-consumer,mce-consumer-main, gms-main were all recreated without any error.
The current error is from the datahub-main-nocode-migration-job being unable to access gms-main, with the endpoint returning a 503
New package installs correctly and the conda functionality seems unaffected.
Tue, Apr 16
From the community and docs, it seems we do need to update the BOOTSTRAP_SYSTEM_UPDATE_WAIT_FOR_SYSTEM_UPDATE https://github.com/wikimedia/operations-deployment-charts/blob/master/helmfile.d/services/datahub/values.yaml#L96 when upgrading datahub to a new version since there are tasks performed by the system update job on upgrades. Re: very informative slack dicussion. The downside of this being some downtime which is/was expected for the v0.11.0 upgrade details below:
Crossposting an update for visibility
We hit a bit of a delay with this while building the new conda package, so far we have updated the conda-analytics-clone command to include the --pinned tag so that the file is available to everyone using it as per Creating_a_new_environment.
However, we ran into a debian related challenge where the buster-backports repo is no longer available which prevents us from building any images that include his repo on apt-update failure. This is being tracked on T362518 and we plan to solve this by rebuilding our container on bullseye here T362648 so as to unblock progress on this.
datahub-gms-main was in error and was rolled back before I could get any error logs from there. Should we revert the BOOTSTRAP_SYSTEM_UPDATE_WAIT_FOR_SYSTEM_UPDATE back to the default? mce and mae were all ok
First upgrade attempt has failed on codfw with some errors on the datahub-main-nocode-migration-job
Mon, Apr 15
Datahub v0.12.1 is successfully running in staging without any issues, we can proceed with the main upgrade.
Fri, Apr 5
Thu, Apr 4
Thanks @nshahquinn-wmf at the moment the pinned file can only be included in clones if the user wishes to. There is not yet a default way to avail this which does not have the optimal UX.
The pinned file can be availed during cloning by introducing the --pinned tag when cloning shown below;
Wed, Apr 3
Got the following errors during the build process
We have some failed container builds which I am looking into https://gitlab.wikimedia.org/repos/data-engineering/datahub/-/pipelines/47394
New package introduces a pinned file for the base environment
stevemunene@an-test-client1002:~$ cat /opt/conda-analytics/conda-meta/pinned # https://phabricator.wikimedia.org/T356230 numpy <1.24 # https://phabricator.wikimedia.org/T356230 pandas <2.2
The current pinned file is a base model and we might need a more standardised production pinned file cc @nshahquinn-wmf
We have introduces a conda analytics pinned file with pandas and numpy versions for starters and built the dev deb package which we are going to test on an-test-client1003
Thu, Mar 28
Feb 27 2024
Ack, the checklist has been moved to https://wikitech.wikimedia.org/wiki/Analytics/Systems/Superset/Administration which is where we will also have the runbook.
Feb 26 2024
Feb 23 2024
superset and superset-next checklists have been added with the only missing values being the metrics and monitor urls which are a WIP.
We now have some saved views for superset and superset next
superset
superset-next
Feb 20 2024
Feb 15 2024
Once the patch to Add stat1010 and stat1011 to scap targets is merged, we shall add a note on the ops week deployment and keep an eye out during the deployment incase of any issues with the two hosts.
Once the patch to Add stat1010 and stat1011 to scap targets is merged, we shall add a note on the ops week deployment and keep an eye out during the deployment incase of any issues with the two hosts.
adding a link to the rsync-published.service resolution and potential discussion on the stat1011 ticket. https://phabricator.wikimedia.org/T354526#9546019
The rsync-published.service error is similar to what we encountered when bringing up stat1009 on T336036.
The error occurs as we try to Rsync $source to $destination/$::hostname using the published-sync script. The destination host is expected to use the statistics::published class to merge $::hostname directories into a single directory.
However, for this case the rsync service user does not have enough permission to create the $::hostname directory in the destination folder on an-web1001. Resulting in the error below when starting
Feb 13 2024
Spent some time looking at Advanced logging configuration and how we use Airflow at the foundation. This is a method that can be explored if there are issues with our current logs or if the specific teams want to fine tune their specific logs, otherwise it was not a viable solution to this specific task especially on the SRE side.
Furthermore, If we check the script used to delete the logs clean_logs.sh, the script uses find for files and directories older than 90 Days and deletes them and it was okay without any need for modification. Tried some variations and all checked out.
Feb 8 2024
Feb 7 2024
The hosts are slowly balancing in the cluster and should help with the low capacity warnings we were getting.
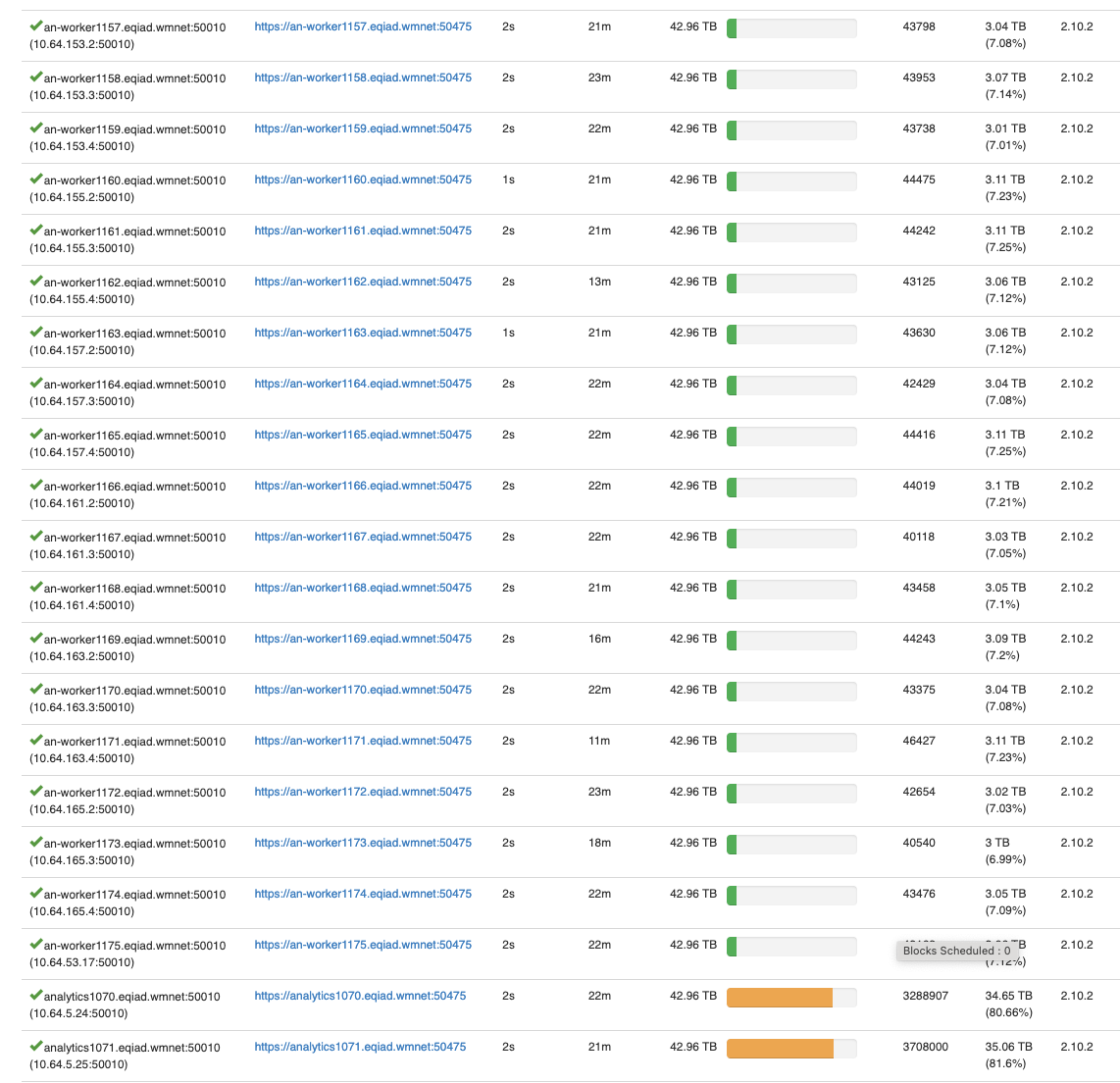
Feb 6 2024
Sure, I'll try the manual failover and restart of the services probably during our sync
Hosts are visiblue on the namenode UI and should rebalance with time
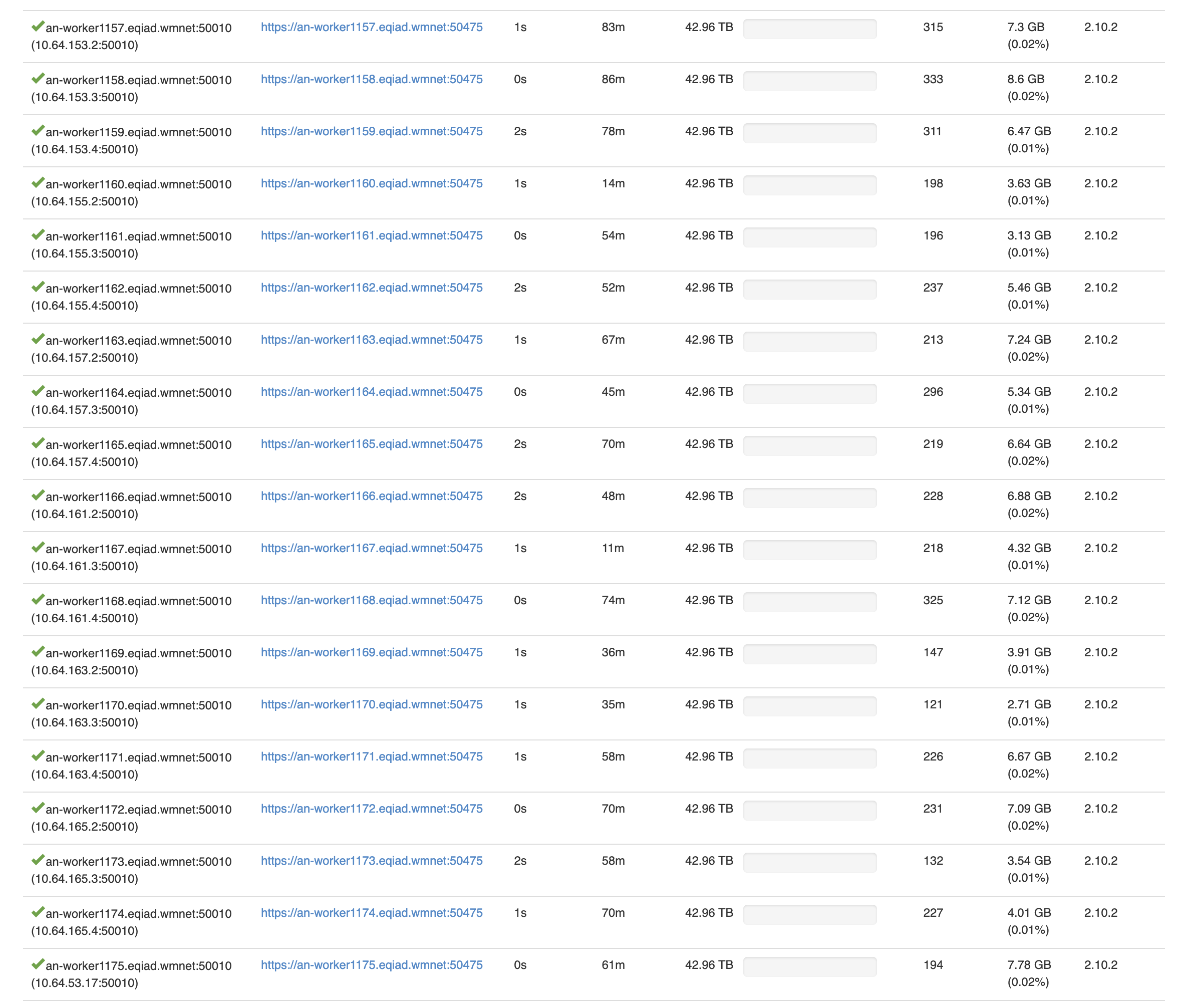
The hosts have been added to net_topology and assigned the right role. Hosts are also running OK without any RAID related alerts. However, some hosts are in the default rack so we shall need to run a role restart of the masters sudo cookbook sre.hadoop.roll-restart-masters analytics this was checked with
stevemunene@an-master1003:~$ sudo -u hdfs kerberos-run-command hdfs hdfs dfsadmin -printTopology
hosts on the default being some of the newly added hosts
Rack: /eqiad/default/rack 10.64.153.2:50010 (an-worker1157.eqiad.wmnet) 10.64.153.3:50010 (an-worker1158.eqiad.wmnet) 10.64.153.4:50010 (an-worker1159.eqiad.wmnet) 10.64.155.4:50010 (an-worker1162.eqiad.wmnet) 10.64.157.2:50010 (an-worker1163.eqiad.wmnet) 10.64.157.3:50010 (an-worker1164.eqiad.wmnet) 10.64.157.4:50010 (an-worker1165.eqiad.wmnet) 10.64.161.2:50010 (an-worker1166.eqiad.wmnet) 10.64.161.4:50010 (an-worker1168.eqiad.wmnet) 10.64.165.2:50010 (an-worker1172.eqiad.wmnet) 10.64.165.4:50010 (an-worker1174.eqiad.wmnet)
Keeping an eye on the cluster
HDFS Capacity remaining
HDFS Available vs used space
Feb 2 2024
Thanks @BTullis, updating wikitech and the cookbook once I get the right commands
Feb 1 2024
From the iDRAc interfce we can verify that the hosts have been set to RAID0 and that the virtual drives are visible as expected.
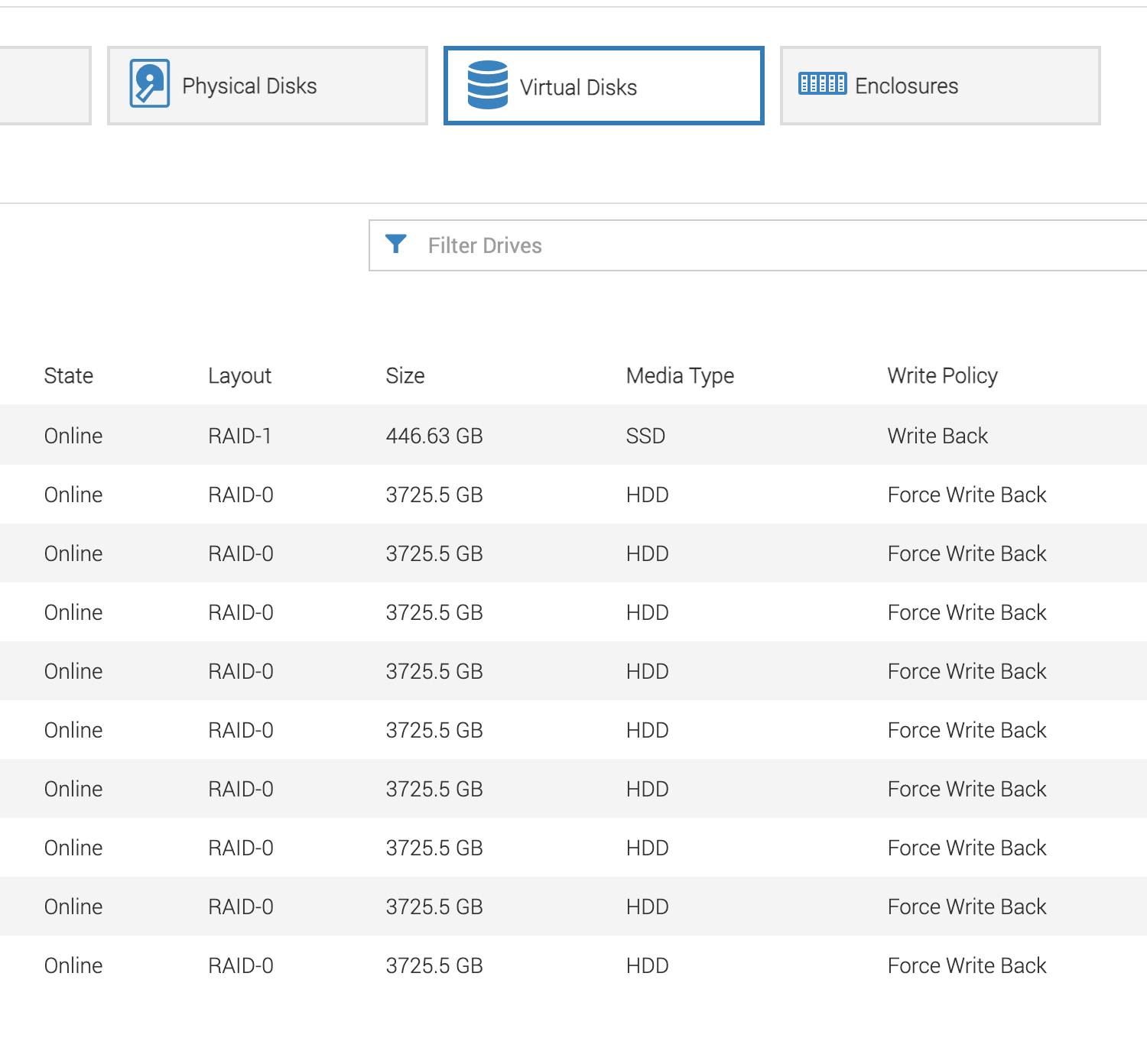
Still trying to understand how they are not visible via megacli commands. Exploring reimaging an-worker1157 with the default playbook and setting up the disks to be visible with
sudo megacli -CfgEachDskRaid0 WB RA Direct NoCachedBadBBU -a0
Jan 31 2024
Saw some comments on some RAID config issues here https://phabricator.wikimedia.org/T349936#9360470 by @Papaul from the rack/setup task but not as detailed.
The new an-workers1157-1175 do not have any Virtual drive configured, however the datanode disks/partitions initialized are as expected. Comparing new host an-worker1157 to previously initialized host an-worker1156
Jan 30 2024
Adding to this, had to run the cookbook sre.hadoop.init-hadoop-workers to install megacli first on all the hosts then pass the megacli command to create a RAID0 volume on each of the physical disks in the array. So we can edit the cookbook to check on the number of drives on the hosts and run the command to create the volumes. However, comparing the parameters passed and those available on the cookbook MegaCLI specific settings. there are some variations in the WB value and NoCachedBadBBU which I would like to look into a bit further.
Currently looking into an error from the playbook
Thanks @BTullis , We can add it to the cookbook for future reference. Did some further reading on the RAID Configuration Input Options used from the StorCLI Reference Manual
RA: Read Ahead
WB: Write Back
Direct: Direct I/O.: Sets the logical drive cache policy. Direct I/O is the default.
CachedBadBBU: Enable bad BBU caching.: Enables caching when BBU is not functioning. Disabled is the default.
The sre.hadoop.init-hadoop-workers fails in creating new partitions. running the cookbook for an-worker1157 fails with the details below