
User Details
- User Since
- Mar 29 2021, 5:20 PM (160 w, 2 d)
- Availability
- Available
- LDAP User
- Unknown
- MediaWiki User
- Tru2198 [ Global Accounts ]
Apr 28 2021
Apr 16 2021
Apr 15 2021
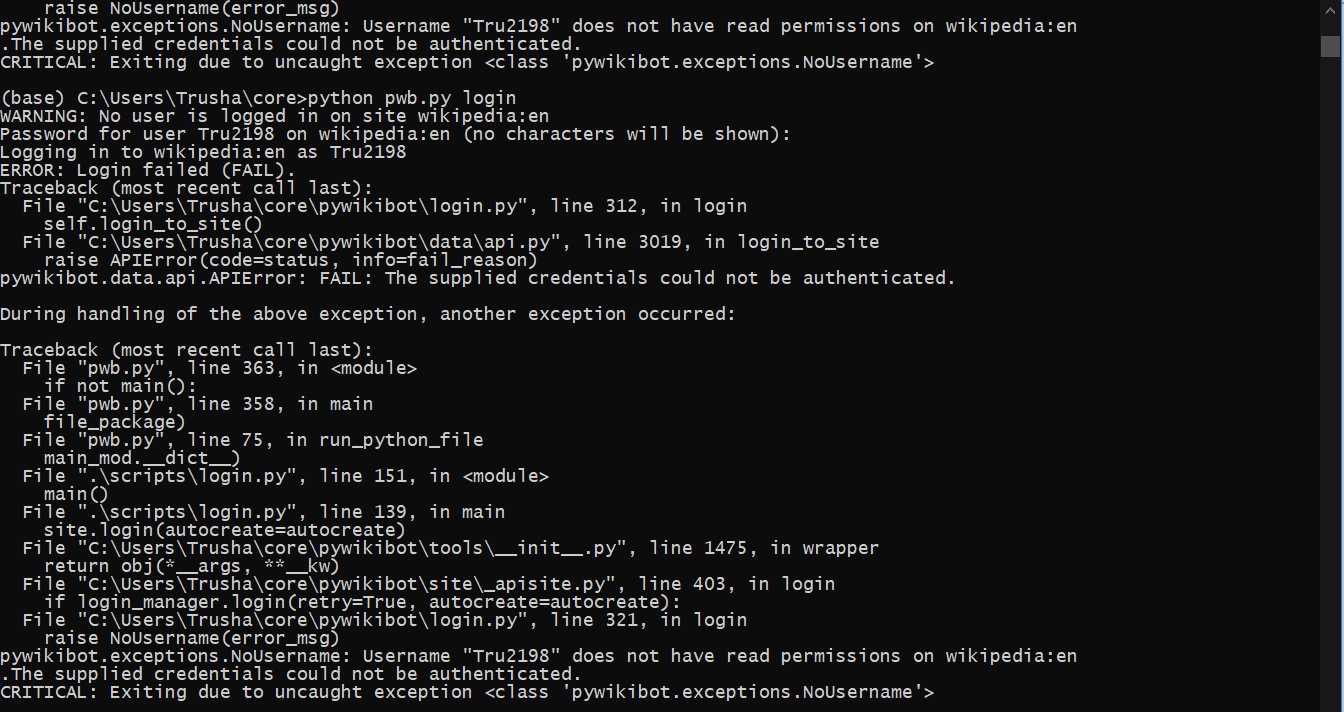
I am getting the error :
pywikibot.exceptions.NoUsername: Username "Tru2198" does not have read permissions on wikipedia:en
.The supplied credentials could not be authenticated.
CRITICAL: Exiting due to uncaught exception <class 'pywikibot.exceptions.NoUsername'>
Apr 11 2021
@Mike_Peel, I am picking the topic Category: JudoInside_template_with_ID_not_in_Wikidata. I hope that won't be an issue!
Apr 10 2021
@Mike_Peel, For Bonus: Explore how to identify the correct item when multiple terms are returned, can we approach the problem with the idea that for every QID returned through the searching title, we refine the correct one by parsing each item for a specific property? For instance, if my title is "Harry Potter". Now that returns Harry Potter movie, book, and character. But only the book will have the property "Language of the work", or "author", or "publication date"?
Apr 9 2021
Also, do review by task_2:
https://www.wikidata.org/w/index.php?title=User:Tru2198/Outreachy_2
Apr 8 2021
“Print out the information alongside the property name (e.g., "P31 = human"). “
Isn't this only in wikidata, as wikidata stores the information in the form of properties and QIDs?
@Mike_Peel So we have to print from both Wikipedia and wikidata? Maybe I mistakenly did only the bonus part! Thank you
Hi @MSGJ, I have completed task_3 which awaits your feedback!
Also, I think this tutorial is also ideal for task_4 that needs adding information to the wiki data.
Apr 7 2021
Hello @Mike_Peel, @MSGJ
I have completed Task_3. Though, I haven't used the parsing through the regex.
@Shristi0gupta , wonderful program! I wanted to know how did you deal with the parameter values who didn't have label? and also, some values without Qnumbers like dates?
Apr 6 2021
Although yesterday, my task_1 got approved, I have added few extra properties and an article that might deviate a bit.
@Mike_Peel, @MSGJ, I have completed task 2. I have mailed you.
Though here is the link:
https://www.wikidata.org/wiki/User:Tru2198/Outreachy_2
Await your feedback,
Thank you!
Apr 5 2021
@Mike_Peel Thank you for the heads up! No matter the interns, I am really enjoying the learning in the contribution!
Hello @Mike_Peel!
I have tried my best with Task_1, and look forward to your feedback. Kindly review it at your time.
Here is the link:
https://www.wikidata.org/wiki/User:Tru2198/Outreachy_1
I am having few confusions on the final tasks for Compare Reader Behavior across Languages. Finding the correct article that matches both the datasets and consequently comparing their (their respective source and destination) values across languages is not ideal and time-consuming as I have to resort to a trial and error approach. I would like to know how others have moved forward with the task?
Thanks!
Apr 2 2021
I have completed my first notebook's microtask with the basic implementation of the functions and analysis that are required. However, there are many updates and enhancements that I would act upon in the upcoming days that I have mentioned in this notebook. Should I record my first contribution and await the review on the Outreachy site?
Apr 1 2021
for the task: Compare Reader Behavior across Languages, will the comparison between two languages suffice, as most articles are supported by only one or two languages, other than the English language that intersects with the available clickstream data and that of the langlinks API?
Mar 31 2021
@MGerlach. Thanks for the suggestion. I'll work on it.
data_frame.group by('Destination').nunique()>=20 returns most of the values with false in Source, destination and link columns. Also, I am facing a deadlock in combining the queries of the TODO task: Choose a destination article from the dataset that is:
"relatively popular (at least 1000 page views (where I am using: data_frame.group by('Destination').sum()>=1000) and 20 unique sources in the dataset"
Hello, for the microtask, I am trying to convert the file to CSV with pandas and subsequently data frames, but I am getting the error where several rows have conflicting columns. So the parameter, error_bad_lines=False to ignore the troubling lines can be used. Is that option viable?