
User Details
- User Since
- Jan 6 2020, 12:19 PM (223 w, 3 d)
- Availability
- Available
- LDAP User
- Unknown
- MediaWiki User
- HNowlan (WMF) [ Global Accounts ]
Yesterday
Tue, Apr 16
Mon, Apr 15
Thu, Apr 11
Wed, Apr 10
Tue, Apr 9
Mon, Apr 8
Do we have a plan for when and how we'd like to move this to production?
Kubernetes jobrunners were using the default max_execution_time of 180s, which might be the culprit for these behaviours. I've bumped it to match the metal jobrunners.
Having looked at this a little further, I have a strong suspicion the timeout is coming from somewhere other than the config that we currently have defined (perhaps a default somewhere that isn't explicit). Going to keep looking into it, there's a chance this timeout will be affecting other mw-on-k8s charts but just hasn't bitten us because they don't use the longer timeouts the jobrunners do.
Fri, Apr 5
Thu, Apr 4
What external paths should we be routing to what internal paths for this service?
After spending some time on this, I think we might have some difficulty with supporting the third citoid pattern of rewriting $site/v1/data/citation/$format/$search to /api?format=$format&search=$search. Envoy's support for this kind of mangling isn't very complete as it's something it kinda expects services to do elsewhere.
Wed, Apr 3
Deployed https://gerrit.wikimedia.org/r/c/operations/deployment-charts/+/1016794 to increase Typha memory limits
It looks like the network setup between staging and cassandra-dev is all what we would expect. Pods are allowed to connect, and the cassandra firewall allows the staging IP range. While nsentered into the mobileapps staging pod:
root@kubestage1003:/home/hnowlan# time nc -z 10.192.16.15 9042 && echo ok
Tue, Apr 2
I've merged the change to increase the envoy timeout to the jobrunners (thanks for the patches!) - looks like run times are increasing for the jobs in question but I'll continue to monitor before we take any further changes.
Declined in favour of T297222
Mon, Mar 25
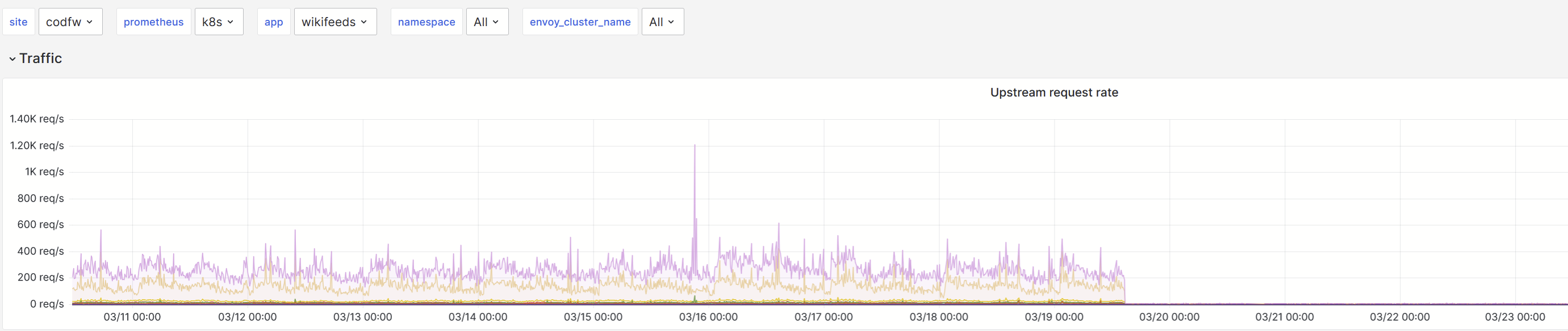
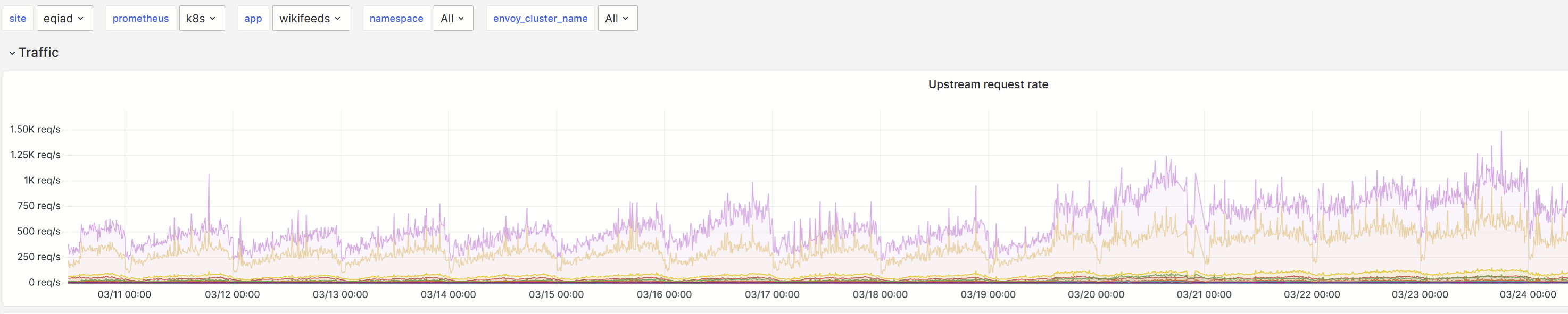
Turnilo says that this is mostly being caused by clients using the mobile apps, various versions. Logstash makes it clear that Wikifeeds itself is timing out when talking to restbase. The URL pattern in that query shows an oddity - request.url shows the featured link (or similar) but the failing internalURI is almost always always an image. I can't find reference for it but I'm fairly sure we've seen this timeout-upon-image-request behaviour in restbase before, but with changeprop.
Mar 6 2024
Is this the same bug as T356369?
Feb 28 2024
Feb 26 2024
Feb 23 2024
Feb 22 2024
Done
Feb 21 2024
All (non-videoscaler) jobs migrated to Kubernetes jobrunners. Videoscaler work tracked in T355292
Feb 20 2024
We saw a recurrence of this issue this morning, with a large number of jobs failing with 503 messages from eventgate for a short period. Envoy also saw failures connecting to eventgate around the same time.
Feb 19 2024
Feb 16 2024
Has there been a final decision on access and the scope of this ticket?
Does this ticket supersede T355170? Change created but dependent upon approval by group approvers (@odimitrijevic , @WDoranWMF, @Ahoelzl @Milimetric)
Any word on approvals for this ticket @odimitrijevic , @WDoranWMF, @Ahoelzl @Milimetric?
Feb 15 2024
Done
Feb 14 2024
Reimage was successful, networking survived a reboot. All done!
I tried another reimage and it currently proceeding successfully - maybe replacing the SFP did the job? This is all a bit inexplicable.
Reimaging fails still after these changes fwiw - however, a reboot has broken network connectivity again?! The host is up and rebooted in the management interface, but I can't ssh in again.
This command also fails - but interestingly the host itself appears to have lost network connectivity. ethtool reports that the link is up but I can't connect in or out and the arp table is empty, I can only get in via the management console.
To limit the impact of this rollout we'll be gradually deploying to restbase servers either in small numbers or one at a time rather than doing a full scap rollout.
Feb 13 2024
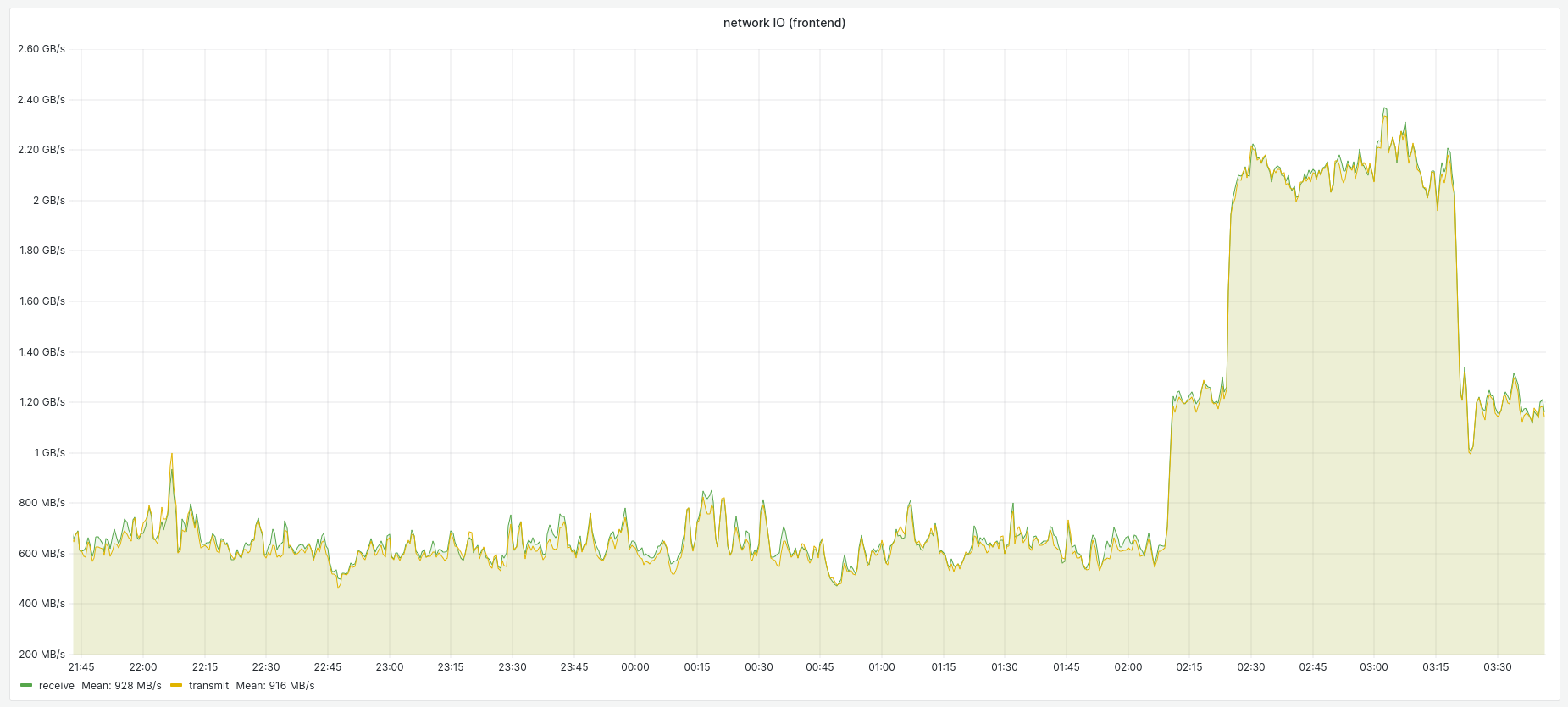
Feb 12 2024
User jaz has been added to analytics-privatedata-users, you should be able to use superset with the associated password.
Moving to stalled pending approval from an analytics-privatedata-users owner (@odimitrijevic , @WDoranWMF, @Ahoelzl @Milimetric)
Moving to stalled pending approval from an analytics-privatedata-users owner (@odimitrijevic , @WDoranWMF, @Ahoelzl @Milimetric)
Could Too many eqiad mediawiki originals uploads be a red herring? The traffic jumps are all in codfw. I'm not sure what's actionable in this ticket.
Required fields empty, no domain specified. Declining.
Feb 9 2024
This is kinda verging on a UBN for us as we go into the weekend because it's causing a lot of spam and it'll hide other error prod states for jobqueues.
This is now rendering after changes to resources for thumbor workers.
This may have been a question of resources, this image is now rendering after some recent bumps.
The train rollout hasn't fixed this issue and we're getting alerts every hour for error spikes on jobrunners - this is beginning to hide other prod issues with the jobrunners so this is a pretty serious concern for us. Apologies, the errors in the ticket *have* been fixed, however we're still seeing spikes of the other errors reported, and they are causing alerts to fire every two hours:
Feb 8 2024
Good catch! Unfortunately I'm still seeing the same PXE behaviour failing on boot
Feb 7 2024
To be explicit about routing differences - we have a rule for /api/rest_v1/metrics/* that directs traffic to the rest gateway and we have a rule for *most* other things under /api/rest_v1/* that defaults to restbase. There are some exceptions for services that have been migrated out of restbase.
Feb 6 2024
Feb 2 2024
Feb 1 2024
Jan 31 2024
Jan 30 2024
Failing disk:
root@aqs1013:/home/hnowlan# udevadm info --query=all --name=/dev/sde| grep SERIAL E: ID_SERIAL=MZ7KH1T9HAJR0D3_S4KVNA0MB04213 E: ID_SERIAL_SHORT=S4KVNA0MB04213 root@aqs1013:/home/hnowlan# dmesg | grep sde | tail [6107332.316343] sd 6:0:0:0: [sde] tag#13 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK cmd_age=0s [6107332.316359] sd 6:0:0:0: [sde] tag#13 CDB: Read(10) 28 00 02 e9 0f 80 00 00 08 00 [6107332.316365] blk_update_request: I/O error, dev sde, sector 48828288 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [6107332.327008] Buffer I/O error on dev sde1, logical block 6103280, async page read [6107332.335094] sd 6:0:0:0: [sde] tag#1 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK cmd_age=0s [6107332.335101] sd 6:0:0:0: [sde] tag#1 CDB: Read(10) 28 00 df 8f df 80 00 00 08 00 [6107332.335107] blk_update_request: I/O error, dev sde, sector 3750748032 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [6107332.345913] Buffer I/O error on dev sde2, logical block 462739952, async page read [6107370.360633] sd 6:0:0:0: [sde] tag#16 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK cmd_age=0s [6107370.360637] sd 6:0:0:0: [sde] tag#16 CDB: ATA command pass through(16) 85 06 2c 00 00 00 00 00 00 00 00 00 00 00 e5 00
This appears to have trailed off around 1400 on the 29th, but if there is a risk of this recurring it'd be great if we could avoid these exception spikes in future.
Jan 29 2024
A surge in this error started around 0700 on the 27th of January, and seems to only occur in volume upon hewikisource (there was a brief spike on itwikivoyage on the 26th also).