How are we doing in our strive for operational excellence? Read on to find out!
Incidents
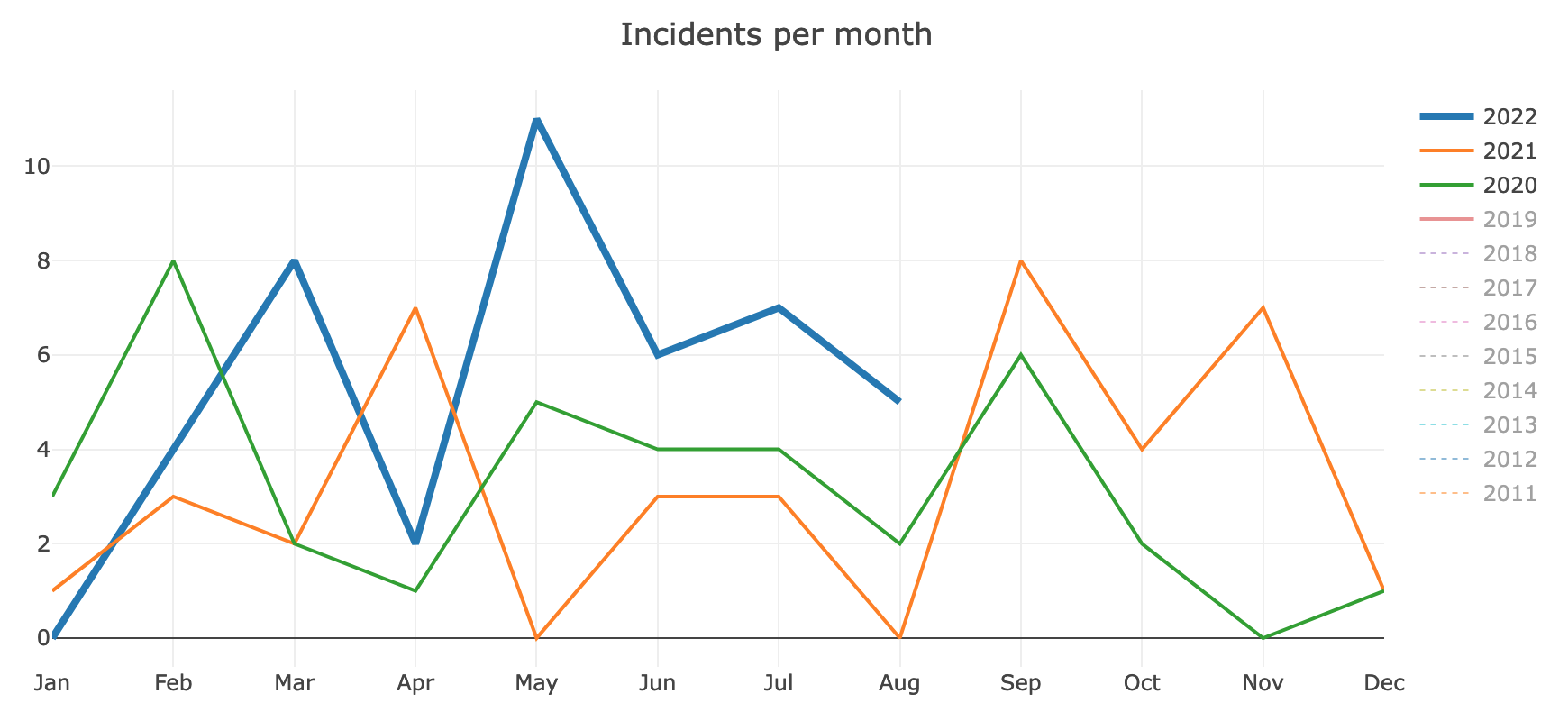
7 documented incidents in July, and 4 in August (Incident graphs). Read more about past incidents at Incident status on Wikitech.
2022-07-03 shellbox
Impact: For 16 minutes, edits and previews for pages with Score musical notes were slow or unavailable.
2022-07-10 thumbor
Impact: For several days, Thumbor p75 service response times gradually regressed by several seconds.
2022-07-11 FrontendUnavailable cache text
Impact: For 5 minutes, the MediaWiki API cluster in eqiad responded with higher latencies or errors.
2022-07-11 Shellbox and parsoid saturation
Impact: For 13 minutes, the mobileapps service was serving HTTP 503 errors to clients.
2022-07-12 codfw A5 power cycle
Impact: No observed public-facing impact. Internal clean up took some work, e.g. for Ganeti VMs.
2022-07-13 eqsin bandwidth
Impact: For 20 minutes, there was a small increase in error responses for thumbnails served from the Eqsin data center (Singapore).
2022-07-20 eqiad network
Impact: For 10-15 minutes, a portion of wiki traffic from Eqiad-served regions was lost (about 1M uncached requests). For ~30 minutes, Phabricator was unable to access its database.
2022-08-10 cassandra disk space
Impact: During planned downtime, other hosts ran out of space due to accumulating logs. No external impact.
2022-08-10 confd all hosts
Impact: No external impact.
2022-08-16 Beta Cluster 502
Impact: For 7 hours, all Beta Cluster sites were unavailable.
2022-08-16 x2 database replication
Impact: For 36 minutes, errors were noticeable for some editors. Saving edits was unaffected.
Incident follow-up
Recently completed incident follow-up:
Replace certificate on elastic09 in Beta Cluster
Brian (@bking, WMF Search) noticed during an incident review that an internal server used an expired cert and renewed it in accordance with a documented process.
Localisation cache must be purged after train deploy
@Tchanders (WMF AHT) filed this in 2020 after a recurring issue with stale interface labels. Work led by Ahmon (@dancy, WMF RelEng).
Remember to review and schedule Incident Follow-up work in Phabricator! These are preventive measures and tech debt mitigations written down after an incident is concluded.
Highlight from the "Oldest incident follow-up" query:
- T83729 Fix monitoring of poolcounter service.
Trends
The month of July saw 22 new production errors of which 9 are still open today. In August we encountered 29 new production errors of which 10 remain open today and have carried over to September.
Take a look at the Wikimedia-production-error workboard and look for tasks that could use your help.
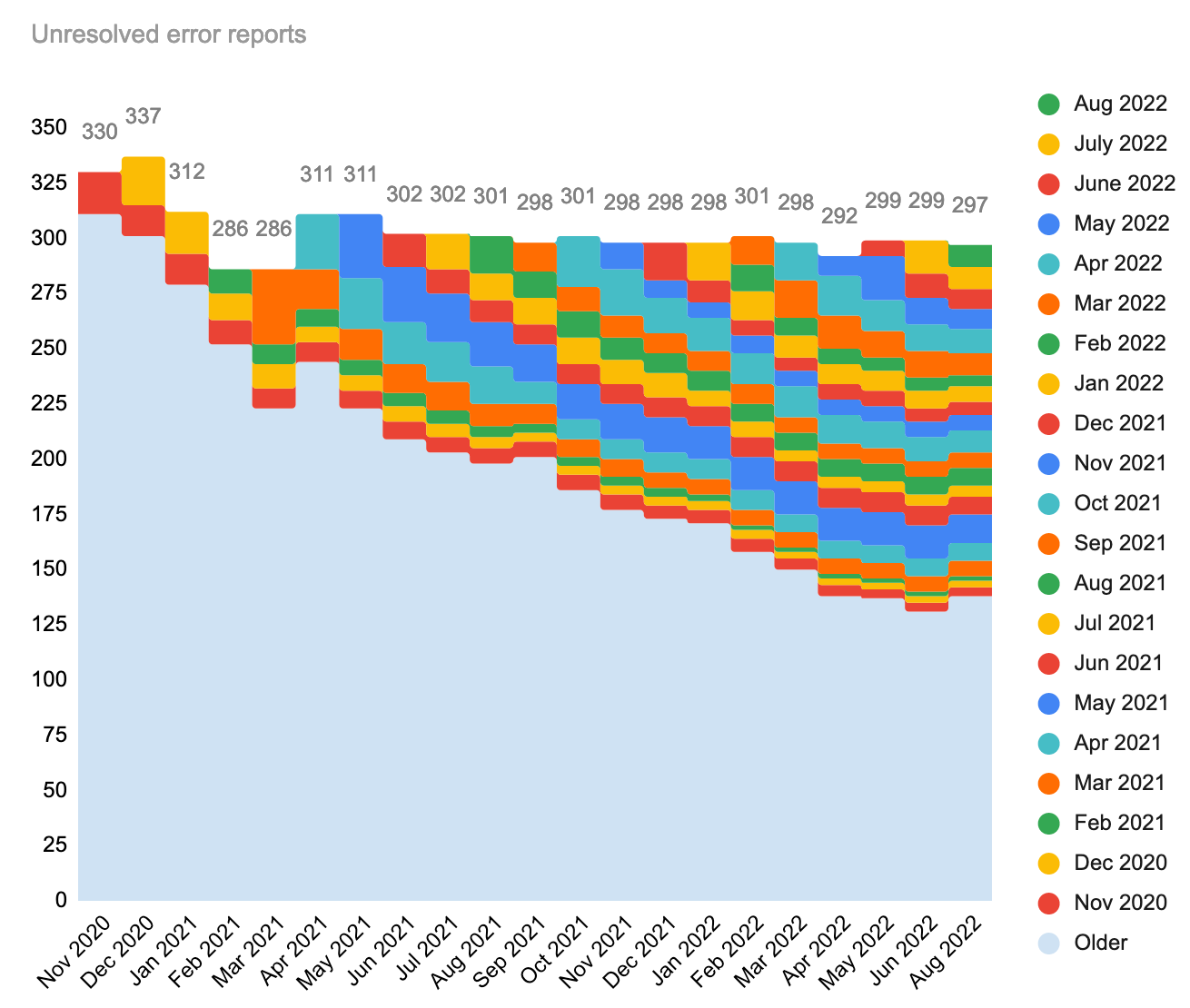
For the month-over-month numbers, refer to the spreadsheet data.
Thanks!
Thank you to everyone who helped by reporting, investigating, or resolving problems in Wikimedia production. Thanks!
Until next time,
– Timo Tijhof