How’d we do in our strive for operational excellence last month? Read on to find out!
Incidents
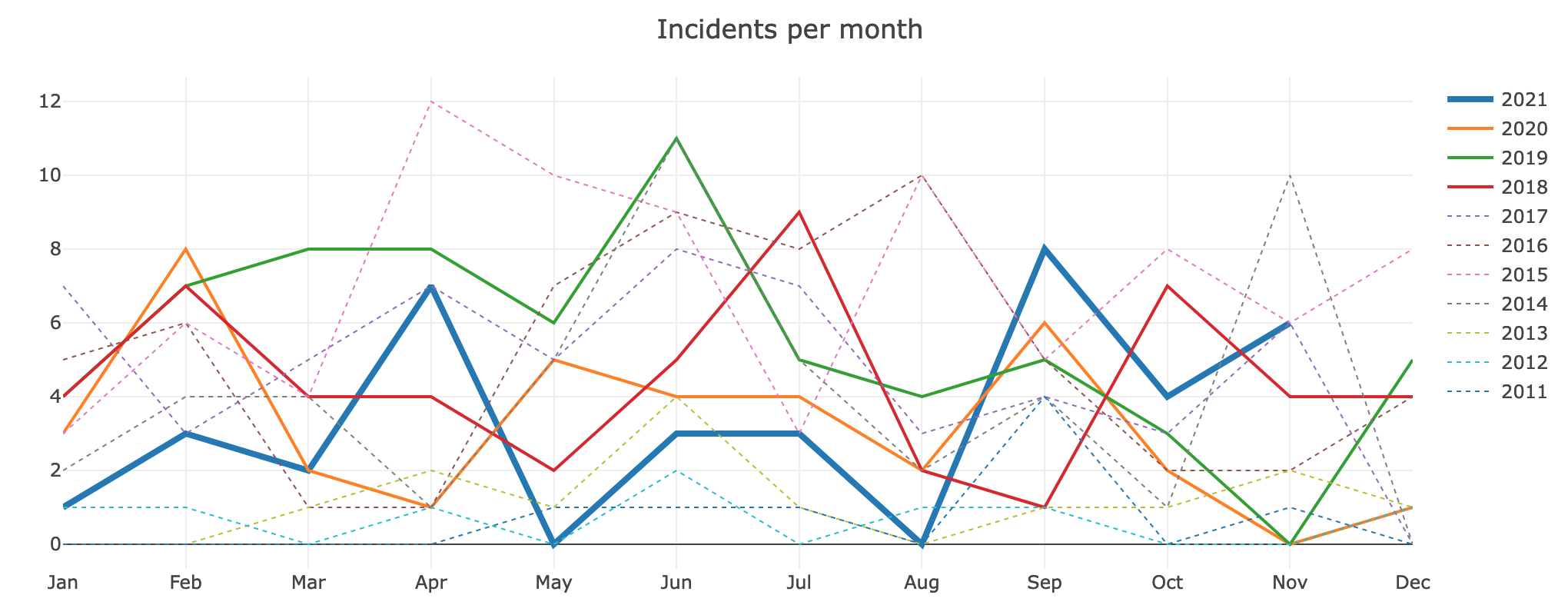
6 documented incidents last month. That's above the two-year and five-year median of 4 per month (per Incident graphs).
2021-11-04 large file upload timeouts
Impact: For 9 months, editors were unable to upload large files (e.g. to Commons). Editors would receive generic error messages, typically after a timeout. In retrospect, a dozen different distinct production errors had been reported and regularly observed that were related and provided different clues, however most of these remained untriaged and uninvestigated for months. This may be related to the affected components having no active code steward.
2021-11-05 TOC language converter
Impact: For 6 hours, wikis experienced a blank or missing table of contents on many pages. For up to 3 days prior, wikis that have multiple language variants (such as Chinese Wikipedia) displayed the table of contents in an incorrect or inconsistent language variant (which are not understandable to some readers).
2021-11-10 cirrussearch commonsfile outage
Impact: For ~2.5 hours, the Search results page was unavailable on many wikis (except English Wikipedia). On Wikimedia Commons the search suggestions feature was unresponsive as well.
2021-11-18 codfw ipv6 network
Impact: For 8 minutes, the Codfw cluster experienced partial loss of IPv6 connectivity for upload.wikimedia.org. This did not affect availability of the service because the "Happy Eyeballs" algorithm ensures browsers (and other clients) automatically fallback to IPv4. The Codfw cluster generally serves Mexico and parts of the US and Canada. The upload.wikimedia.org service serves photos and other media/document files, such as displayed in Wikipedia articles.
2021-11-23 core network routing
Impact: For about 12 minutes, Eqiad was unable to reach hosts in other data centers via public IP addresses. This was due to a BGP routing error. There was no impact on end-user traffic, and impact on internal traffic was limited (only Icinga alerts themselves) because internal traffic generally uses local IP subnets which we currently route with OSPF instead of BGP.
2021-11-25 eventgate-main outage
Impact: For about 3 minutes, eventgate-main was down. This resulted in 25,000 MediaWiki backend errors due to inability to queue new jobs. About 1000 user-facing web requests failed (HTTP 500 Error). Event production briefly dropped from ~3000 per second to 0 per second.
Incident follow-up
Remember to review and schedule Incident Follow-up work in Phabricator, which are preventive measures and tech debt mitigations written down after an incident is concluded. Read more about past incidents at Incident status on Wikitech.
Recently resolved incident follow-up:
Disable DPL on wikis that aren't using it.
Filed after a July 2021 incident, done by Amir (Ladsgroup) and Kunal (Legoktm).
Create easy access to MySQL ports for faster incident response and maintenance.
Filed in Sep 2021, and carried out by Stevie (Kormat).
Create paging alert for primary DB hosts.
Filed after a Sept 2019 incident, done by Stevie (Kormat).
Trends
November saw 27 new production error reports of which 14 were resolved, and 13 remain open and carry over to the next month.
Of the 301 errors still open from previous months, 16 were resolved. Together with the 13 carried over from November that brings the workboard to 298 unresolved tasks.
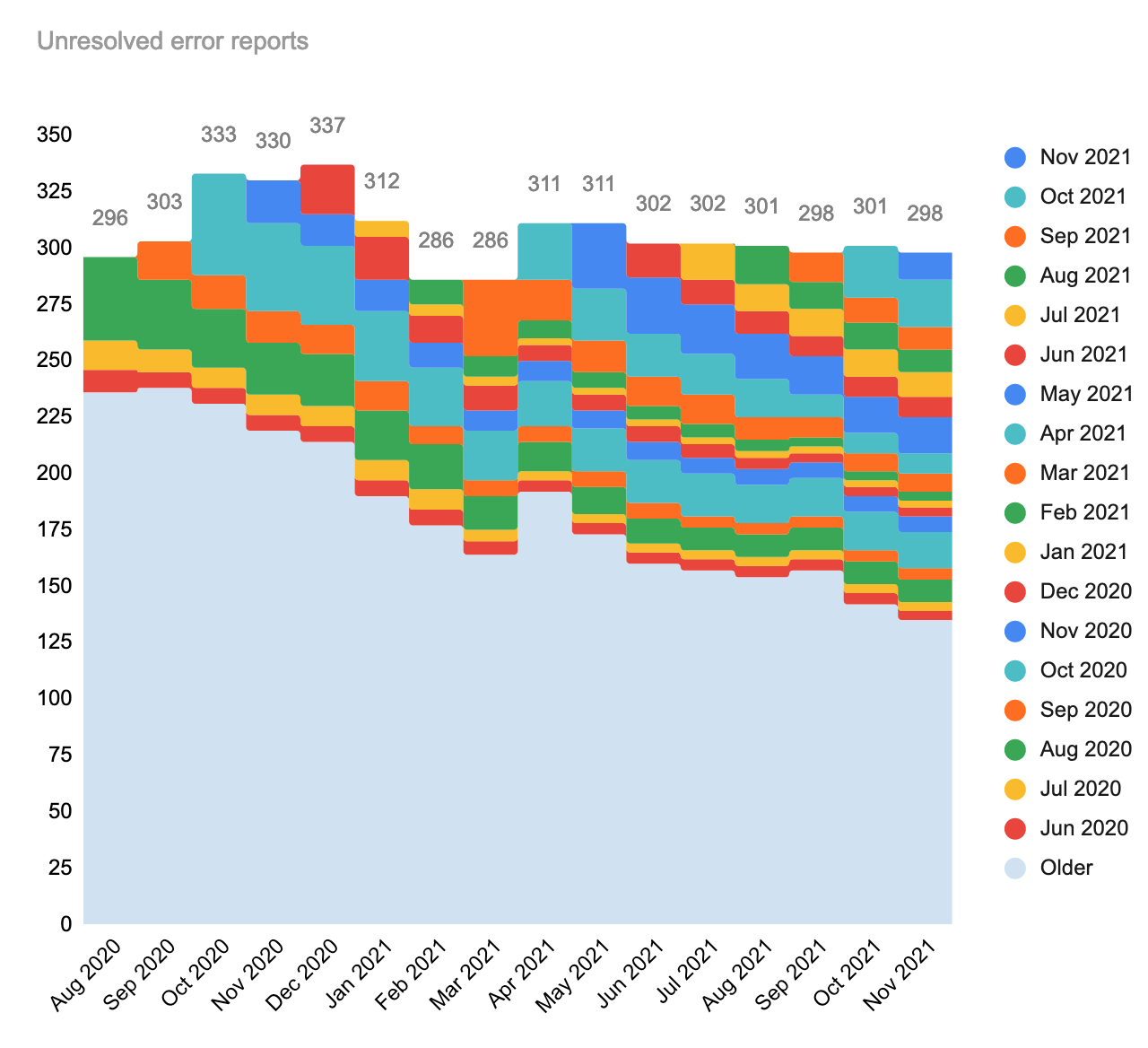
For the month-over-month numbers, refer to the spreadsheet data.
Outstanding errors
Issues carried over from recent months:
| Apr 2021 | 9 of 42 issues left. |
| May 2021 | 16 of 54 issues left. |
| Jun 2021 | 9 of 26 issues left. |
| Jul 2021 | 11 of 31 issues left. |
| Aug 2021 | 10 of 46 issues left. |
| Sep 2021 | 10 of 24 issues left. |
| Oct 2021 | 20 of 49 issues left. |
| Nov 2021 | 13 of 27 new issues are carried forward. |
Thanks!
Thank you to everyone who helped by reporting, investigating, or resolving problems in Wikimedia production. Thanks!
Until next time,
– Timo Tijhof
- Projects
- None
- Subscribers
- None
- Tokens