Developers should own the process of putting their code into production. They should decide when to deploy, monitor their deployment, and make decisions about rollback.
But that’s not how we work at Wikimedia today, and we on Release Engineering aren’t sure how to get there, so we’ve decided to experiment.
Typically a deployment takes us a full week to complete—the week of March 21st, 2022, we deployed MediaWiki four times.
We called that week 🚂🧪Trainsperiment Week.
📻 Deployment frequency
MediaWiki's mainline branch is changing constantly, but we deploy MediaWiki weekly (kind of). We keep stats that measure how far our main branch is from production.
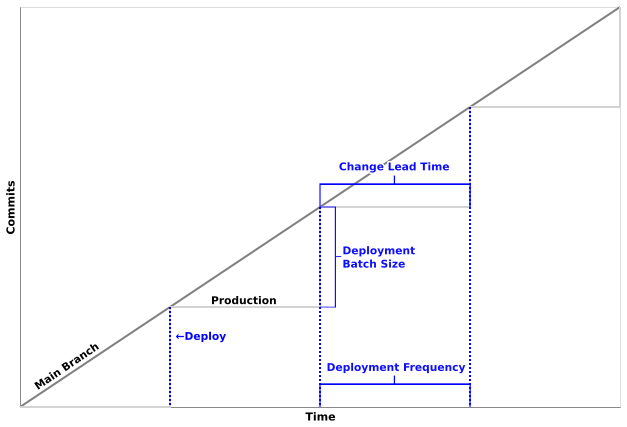
The trainsperiment changed our deployment frequency, which affected all the other metrics, too. Faster deployment means smaller batch size, and shorter change lead time.
📦 Change lead time
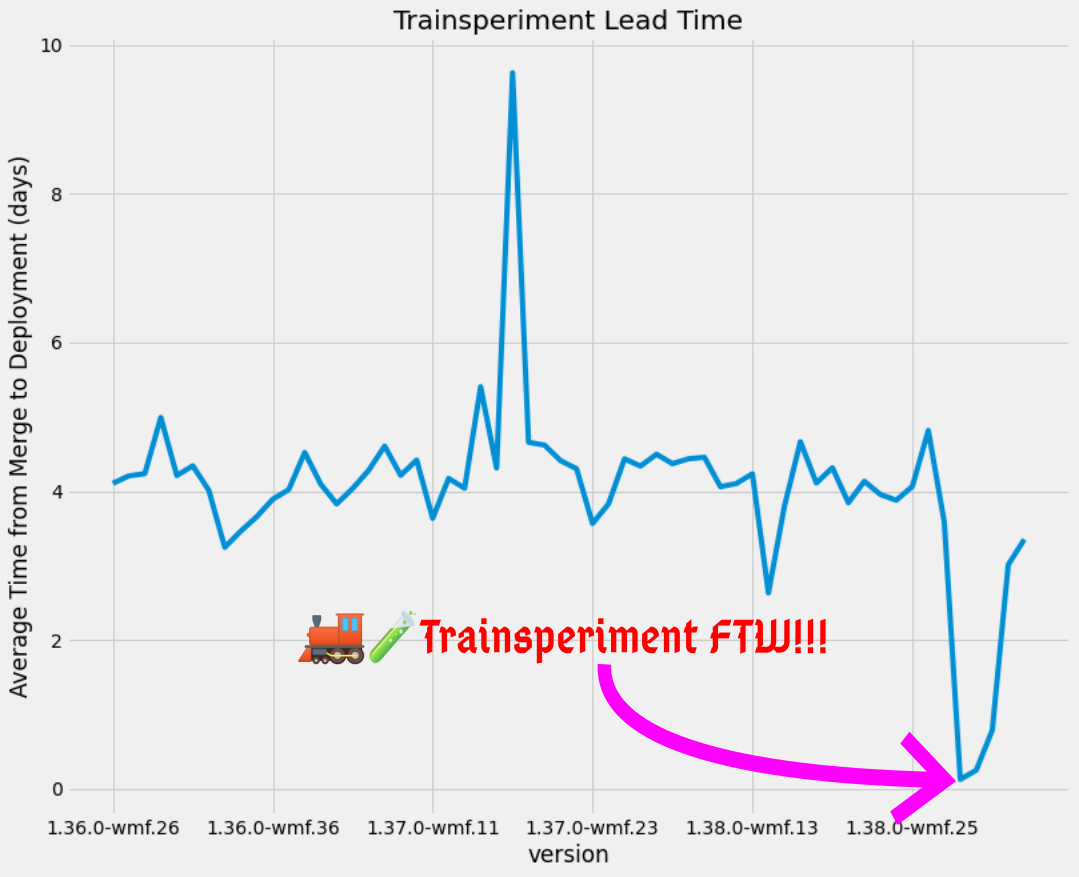
The number that we knew would change during trainsperiment week was change lead time—the time from merge to deploy. If I merge a change, then a minute later I deploy it, that change’s lead time is one minute.
This chart shows the average lead time of all patches in a given train:
The chart below compares a typical week (1.38.0-wmf.1) to trainsperiment week (1.38.0-wmf.2, wmf.3, and wmf.4). Each dot is a change in a particular version—fewer dots mean fewer changes.
During trainsperiment week, we deployed faster. Each deployment was smaller, and the lead time of each patch in a release was shorter.
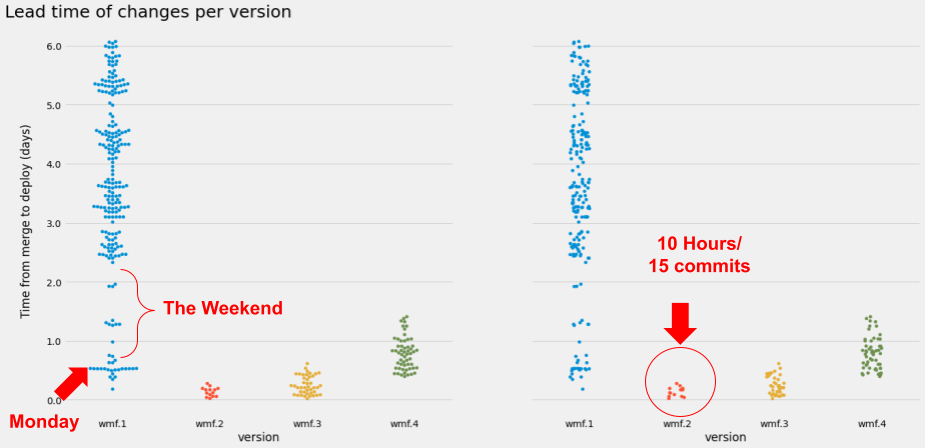
Here’s the same data on a logarithmic scale. During trainsperiment week there were only a few hours between trains, so the lead time could be measured in hours, not days!

📝 Survey Feedback
At the end of the week, we asked for feedback via the Wikitech-l mailing list. We collected comments from the mediawiki.org talk page and the summaries of candid conversations.
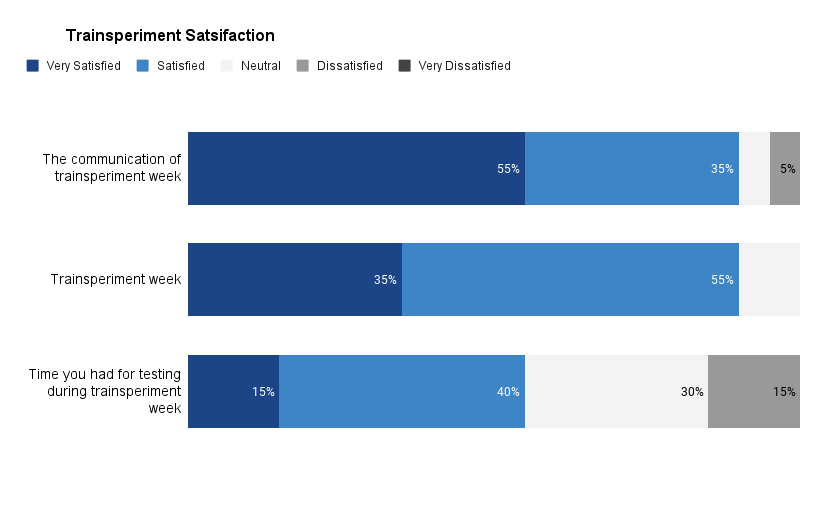
👍 Satisfaction
A small number of people took the time to respond to the survey—20 people answered our questions.
Almost everyone who took the survey seemed satisfied with communication. Most were satisfied with the experiment overall.
There were concerns on the talk page and in the survey responses about testing. Testing felt time-crunched, and everyone was worried about the time pressure on our Quality and Test Engineering Team (QTE).
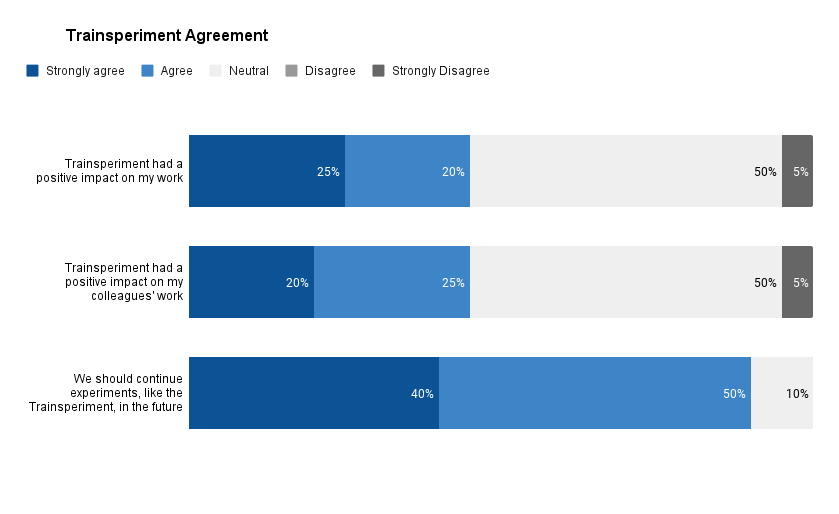
🌚 Impact
Less than half of our respondents felt that the Trainsperiment positively impacted their work, with one respondent strongly disagreeing that there was a positive impact.
Most people were neutral about the impact of this experiment on their work.
The person who felt that there was a negative impact was concerned about the lack of time allotted for testing—they urged us to rethink testing if we wanted to try this again.
💌 Comments
The survey contained free-form prompts for feedback. Below is a smattering of representative responses. Most of the comments below are amalgamations and simplifications, but the reactions in quotes are verbatim.
What should RelEng have done differently
- Automated alerts: emails whenever there’s a deploy or the train is blocked
What would you need to change if we did this every week?
- No time to find and fix regressions means the QA process would need to change somehow
- More transparency around when train rolls out and a clearer blocking process
- Translations
- “my mental model.”
Other Feedback
- “With less time between groups, breakage will reach all wikis very quickly”
- “Often Tuesdays are currently used to deploy bug fixes that are hard to test locally […] we would need to revisit many of our workflows”
- “This, at least on paper, will help devs”
- “This was a pure win, IMO.”
🗣️ Conversations
We talked individually to people who had concerns about the experiment on Slack and IRC, in meetings, in the survey feedback, and on the talk page.
People were concerned about shortening the time for review. This is understandable given that we shortened a 168-hour process to a 12-hour process.
Our QA process takes time. Our overburdened principal engineers take time to review code going live on a weekly basis. Due to some esoteric details, even our CI system gives us more confidence given more time—it was possible that MediaWiki could have broken compatibility with an extension without alerting anyone.
We have come to rely on the weekly cadence to make a careful release, and a faster process would mean rethinking our process pipeline to production.
🎀 Release Engineering's Feedback
The weekly train hides a lot of technical debt—it’s a giant feature flag and the missing testing environment rolled into one. It goes out every week (mostly), and Release Engineering spends about 20% of its time monitoring the release.
During trainsperiment week, we spent 100% of our time deploying—that’s not sustainable for our team.
We surfaced process pain points with this experiment, which was a success. We added to the already overlarge burdens of our principal engineers and quality engineers, which was a failure.
But this isn’t the end of the experiments. We endeavor to bring developers and production closer together—preferably with us standing back a healthy distance. If you’d like to help us get there—get in touch.
Thanks to @kchapman, @brennen, and @Krinkle for reading earlier drafts of this post and offering their feedback.
- Projects
- None
- Subscribers
- Remagoxer, • kchapman, Krinkle, brennen
- Tokens