How’d we do in our strive for operational excellence last month? Read on to find out!
Incidents
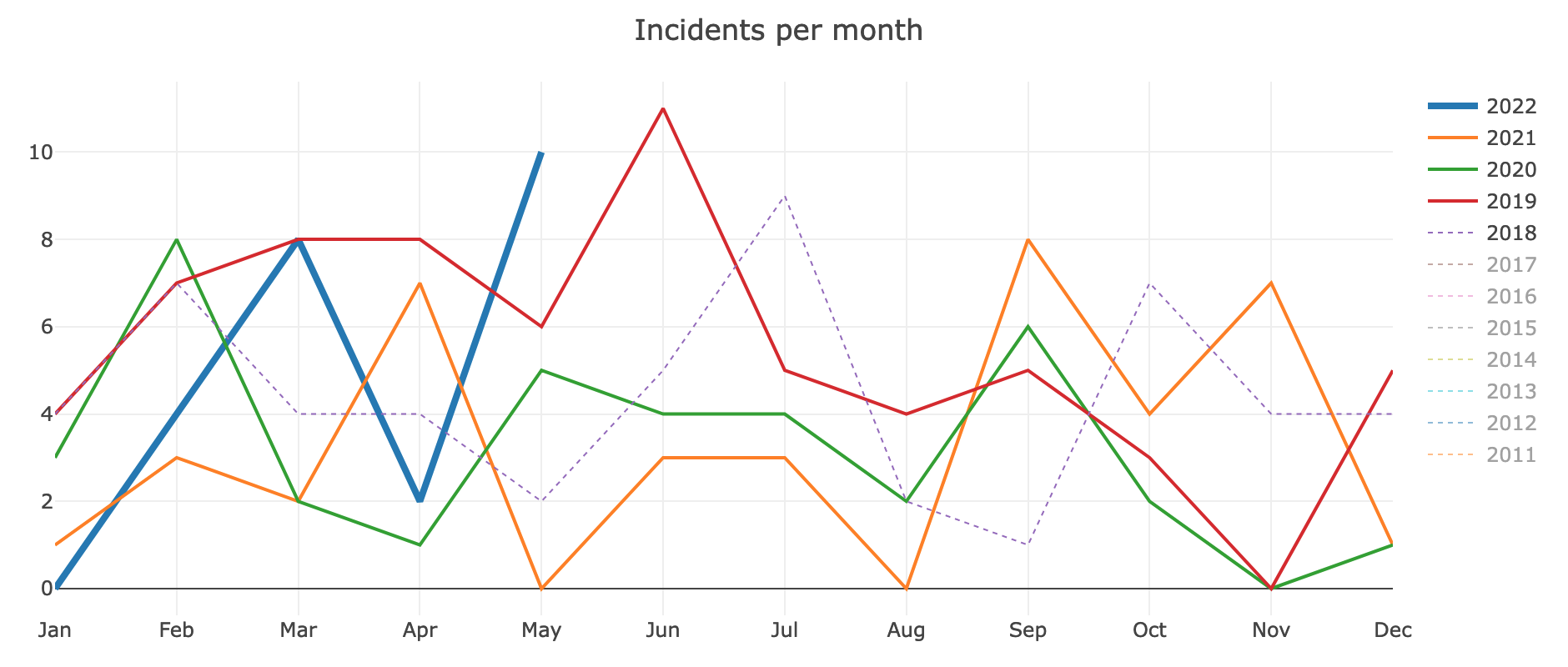
By golly, we've had quite the month! 10 documented incidents, which is more than three times the two-year median of 3. The last time we experienced ten or more incidents in one month, was June 2019 when we had eleven (Incident graphs, Excellence monthly of June 2019).
I'd like to draw your attention to something positive. As you read the below, take note of incidents that did not impact public services, and did not have lasting impact or data loss. For example, the Apache incident benefited from PyBal's automatic health-based depooling. The deployment server incident recovered without loss thanks to Bacula. The Etcd incident impact was limited by serving stale data. And, the Hadoop incident recovered by resuming from Kafka right where it left off.
2022-05-01 etcd
Impact: For 2 hours, Conftool could not sync Etcd data between our core data centers. Puppet and some other internal services were unavailable or out of sync. The issue was isolated, with no impact on public services.
2022-05-02 deployment server
Impact: For 4 hours, we could not update or deploy MediaWiki and other services, due to corruption on the active deployment server. No impact on public services.
2022-05-05 site outage
Impact: For 20 minutes, all wikis were unreachable for logged-in users and non-cached pages. This was due to a GlobalBlocks schema change causing significant slowdown in a frequent database query.
2022-05-09 Codfw confctl
Impact: For 5 minutes, all web traffic routed to Codfw received error responses. This affected central USA and South America (local time after midnight). The cause was human error and lack of CLI parameter validation.
2022-05-09 exim-bdat-errors
Impact: During five days, about 14,000 incoming emails from Gmail users to wikimedia.org were rejected and returned to sender.
2022-05-21 varnish cache busting
Impact: For 2 minutes, all wikis and services behind our CDN were unavailable to all users.
2022-05-24 failed Apache restart
Impact: For 35 minutes, numerous internal services that use Apache on the backend were down. This included Kibana (logstash) and Matomo (piwik). For 20 of those minutes, there was also reduced MediaWiki server capacity, but no measurable end-user impact for wiki traffic.
2022-05-25 de.wikipedia.org
Impact: For 6 minutes, a portion of logged-in users and non-cached pages experienced a slower response or an error. This was due to increased load on one of the databases.
2022-05-26 m1 database hardware
Impact: For 12 minutes, internal services hosted on the m1 database (e.g. Etherpad) were unavailable or at reduced capacity.
2022-05-31 Analytics Hadoop failure
Impact: For 1 hour, all HDFS writes and reads were failing. After recovery, ingestion from Kafka resumed and caught up. No data loss or other lasting impact on the Data Lake.
Incident follow-up
Recently completed incident follow-up:
Invalid confctl selector should either error out or select nothing
Filed by Amir (@Ladsgroup) after the confctl incident this past month. Giuseppe (@Joe) implemented CLI parameter validation to prevent human error from causing a similar outage in the future.
Backup opensearch dashboards data
Filed back in 2019 by Filippo (@fgiunchedi). The OpenSearch homepage dashboard (at logstash.wikimedia.org) was accidentally deleted last month. Bryan (@bd808) tracked down its content and re-created it. Cole (@colewhite) and Jaime (@jcrespo) worked out a strategy and set up automated backups going forward.
Remember to review and schedule Incident Follow-up work in Phabricator! These are preventive measures and tech debt mitigations written down after an incident is concluded. Read more about past incidents at Incident status on Wikitech.
Trends
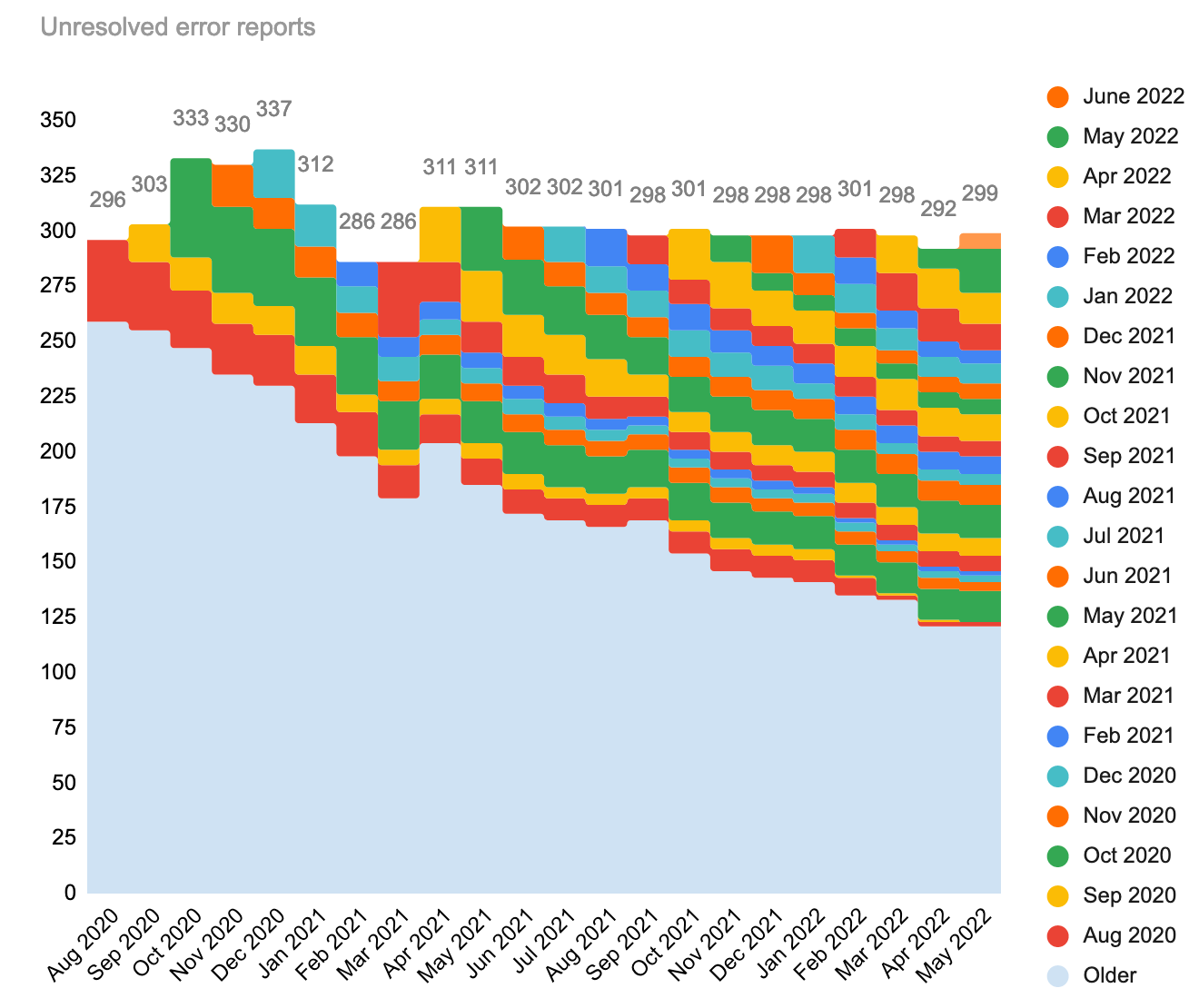
In May we discovered 28 new production errors, of which 20 remain unresolved and have come with us to June.
Last month the workboard totalled 292 tasks still open from prior months. Since the last edition, we completed 11 tasks from previous months, gained 11 additional errors from May (some of May was counted in last month), and have 7 fresh errors in the current month of June. As of today, the workboard houses 299 open production error tasks (spreadsheet, phab report).
Take a look at the workboard and look for tasks that could use your help.
View Workboard
Thanks!
Thank you to everyone who helped by reporting, investigating, or resolving problems in Wikimedia production. Thanks!
Until next time,
– Timo Tijhof
- Projects
- None
- Subscribers
- None
- Tokens