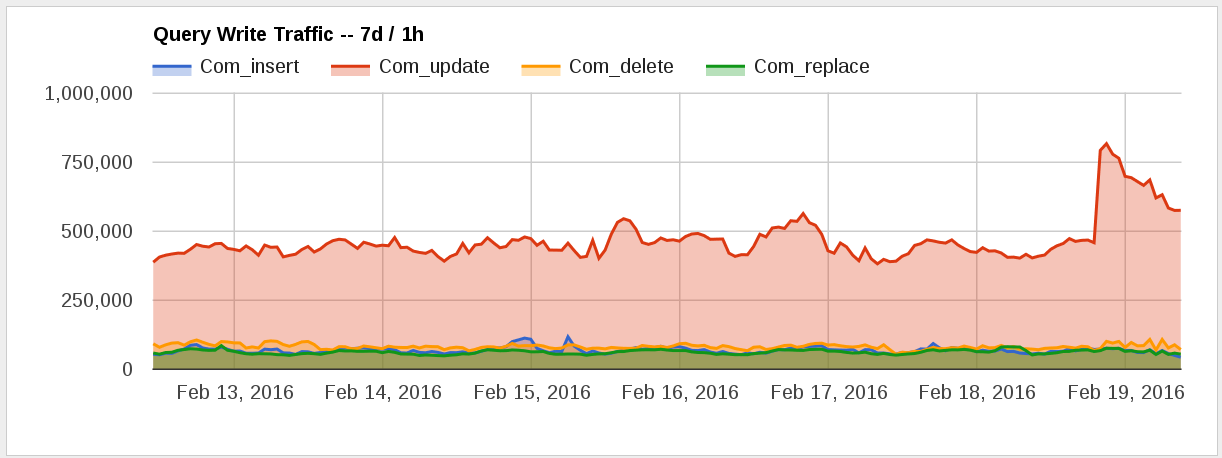
I see some slow queries in the logs for touch usages:
UPDATE /* Wikibase\Client\Usage\Sql\EntityUsageTable::touchUsageBatch */ wbc_entity_usage SET eu_touched = '20150907064933' WHERE eu_row_id IN ('2430363','2430361','2430345','2430360','2430348','61591','61590','107383','2430347','2430358','2430343','2430362','2430365','2430351','2430353','2430354','2430344','rEVED243035664a3b','2430350','2430366','2430355','2430359','2430352','2430357','2430346','2430349','2430364')
We should still think about how to improve these.