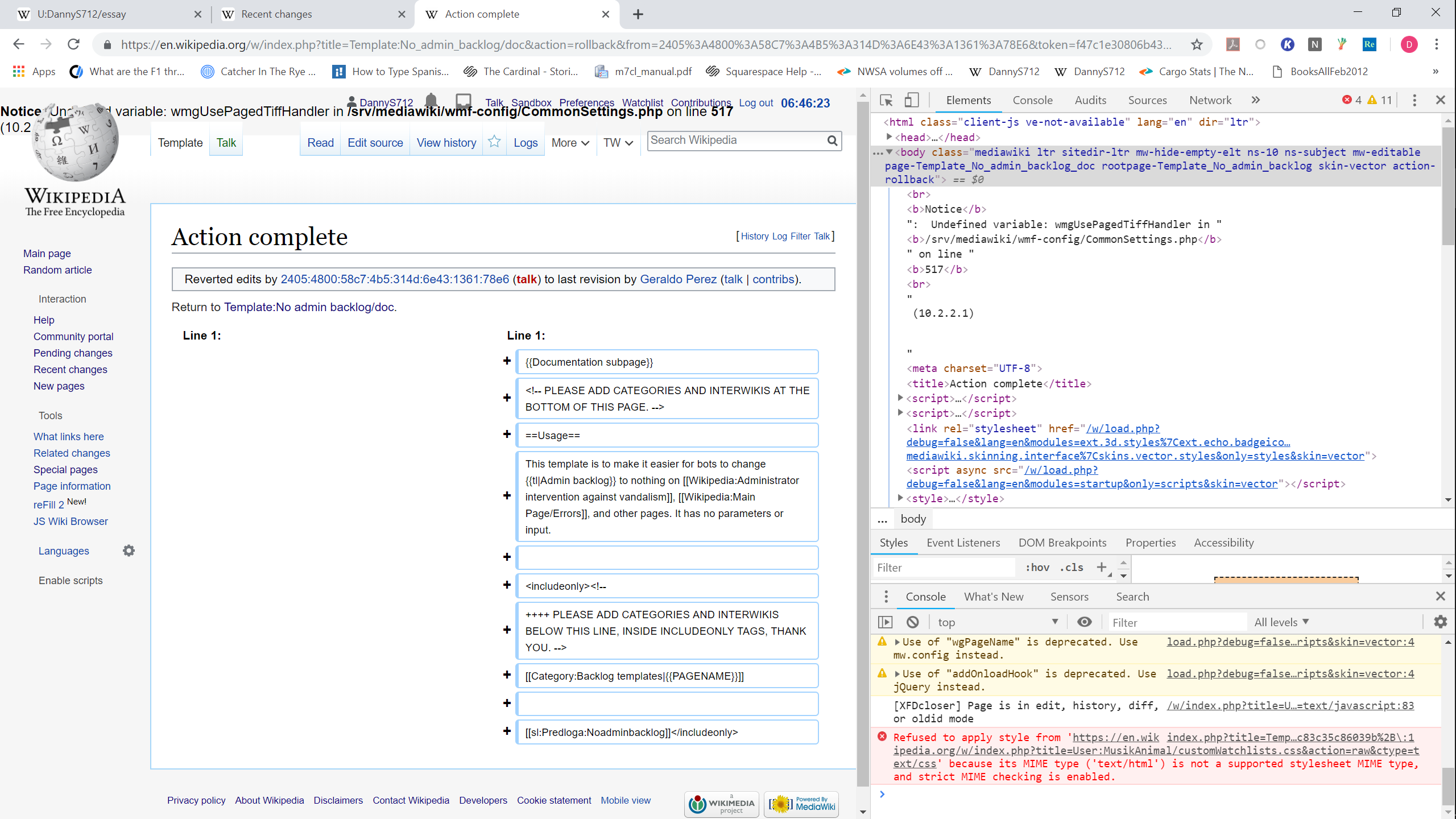
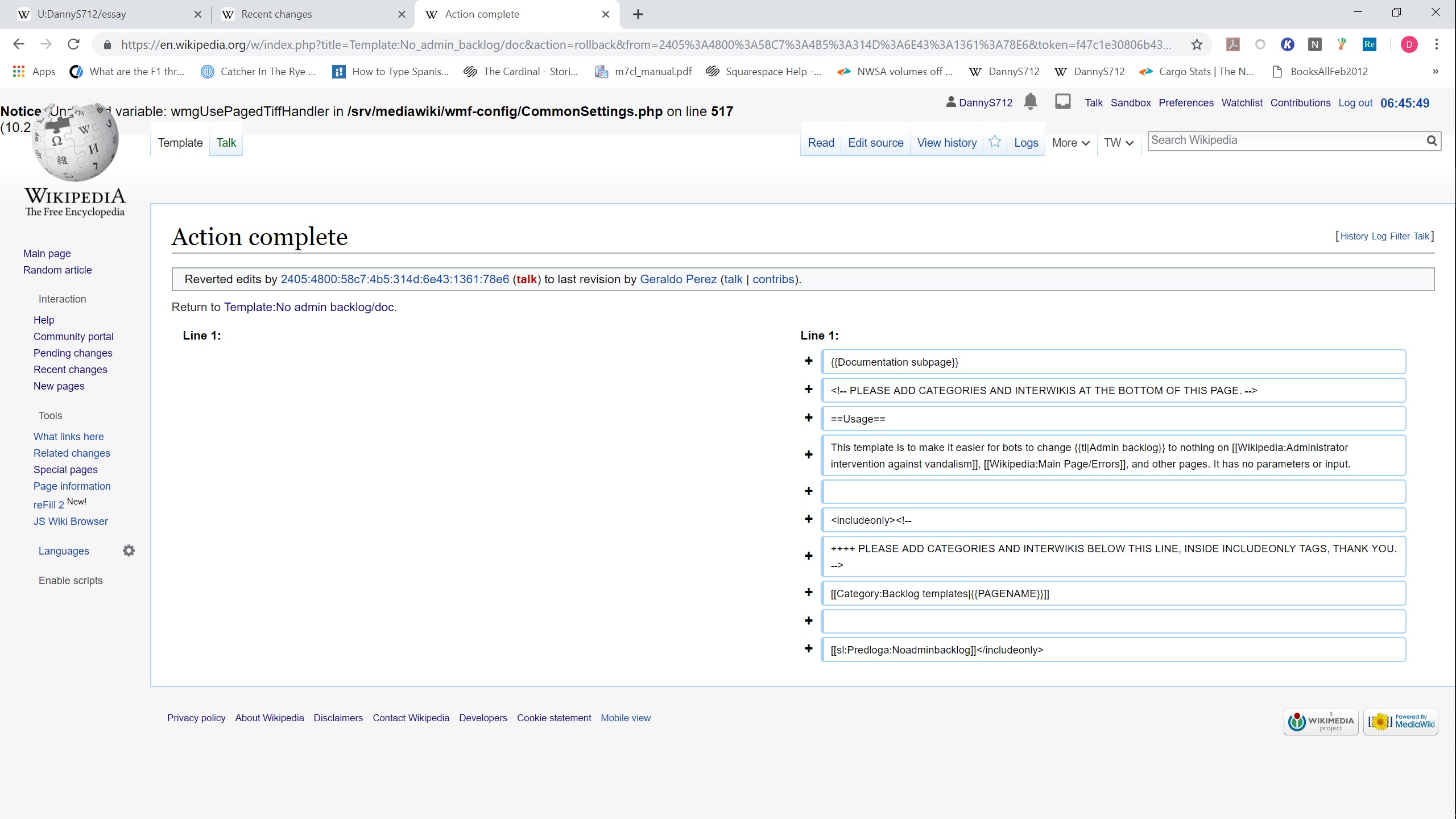
After performing this edit using rollback on the english wikipedia, I saw an error at the "Action complete" page (here). Screenshots of the page, and of the html that caused it to display, are attached. There were no errors in the console relevant to this. I believe it is related to https://github.com/wikimedia/operations-mediawiki-config/blob/master/wmf-config/CommonSettings.php#L517, since the error reports that $wmgUsePagedTiffHandler is undefined, and I can't find it mentioned previously in that file.