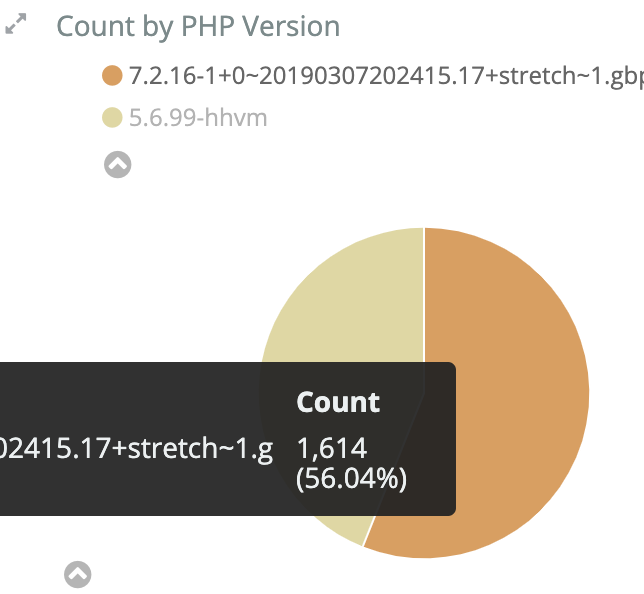
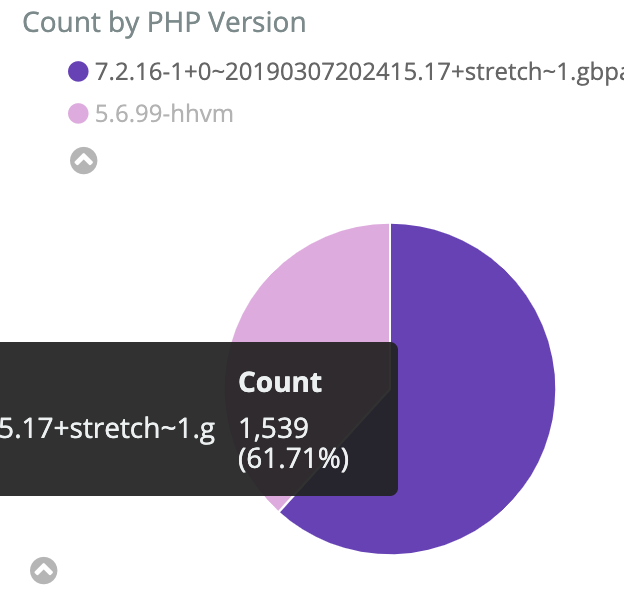
Two kinds of errors appeared during a deployment earlier today.
These was limited to one server (mw1262), one PHP run-time PHP 7, and recovered within a minute or two. This suggests it's related to opcache corruption or some such.
See also: T221347
Fatal error due to undefined interfaceRequest ID: XO1PdwpAADkAAAL-DwYAAABE
message[{exception_id}] {exception_url} PHP Fatal Error from line 29 of /srv/mediawiki/php-1.34.0-wmf.6/vendor/wikibase/data-model/src/Entity/Item.php: Interface 'Wikibase\DataModel\Statement\StatementListHolder' not foundIt seems there is no useful stacktrace. Ping T187147.
host mw1262 / php7.2 Duration 15:10-15:11 (2 minutes)
PHP error - undefined keyRequest ID: XO1PcgpAADkAAAL-Do8AAABA
messagePHP Notice: Undefined index: userlangattributes #0 /srv/mediawiki/php-1.34.0-wmf.6/includes/skins/QuickTemplate.php(117): MWExceptionHandler::handleError(integer, string, string, integer, array) #1 /srv/mediawiki/php-1.34.0-wmf.6/skins/Vector/includes/VectorTemplate.php(229): QuickTemplate->html(string) #2 /srv/mediawiki/php-1.34.0-wmf.6/skins/Vector/includes/VectorTemplate.php(205): VectorTemplate->renderPortal(string, array) #3 /srv/mediawiki/php-1.34.0-wmf.6/skins/Vector/includes/VectorTemplate.php(118): VectorTemplate->renderPortals(array) #4 /srv/mediawiki/php-1.34.0-wmf.6/includes/skins/SkinTemplate.php(230): VectorTemplate->execute() #5 /srv/mediawiki/php-1.34.0-wmf.6/includes/OutputPage.php(2749): SkinTemplate->outputPage() #6 /srv/mediawiki/php-1.34.0-wmf.6/includes/exception/MWException.php(180): OutputPage->output() #7 /srv/mediawiki/php-1.34.0-wmf.6/includes/exception/MWException.php(216): MWException->reportHTML() #8 /srv/mediawiki/php-1.34.0-wmf.6/includes/exception/MWExceptionHandler.php(119): MWException->report() #9 /srv/mediawiki/php-1.34.0-wmf.6/includes/exception/MWExceptionHandler.php(195): MWExceptionHandler::report(MWException) #10 /srv/mediawiki/php-1.34.0-wmf.6/includes/MediaWiki.php(542): MWExceptionHandler::handleException(MWException) #11 /srv/mediawiki/php-1.34.0-wmf.6/index.php(42): MediaWiki->run()
host mw1262 / php7.2 Duration 15:10
Error from line 448 of /srv/mediawiki/php-1.34.0-wmf.6/includes/CommentStore.php: Call to undefined method CommentStore::getCommentInternal()
Count 2,256 Host(s) mw1329 / php72 Duration 13:59 - 14:09 (10 mintes)
Call to undefined method PermissionManager::checkPageRestrictions()message[{exception_id}] {exception_url} Error from line 264 of /srv/mediawiki/php-1.34.0-wmf.6/includes/Permissions/PermissionManager.php: Call to undefined method MediaWiki\Permissions\PermissionManager::checkPageRestrictions() #0 /srv/mediawiki/php-1.34.0-wmf.6/includes/Permissions/PermissionManager.php(117): MediaWiki\Permissions\PermissionManager->getPermissionErrorsInternal(string, User, Title, string, boolean) #1 /srv/mediawiki/php-1.34.0-wmf.6/includes/Title.php(2217): MediaWiki\Permissions\PermissionManager->userCan(string, User, Title, string) #2 /srv/mediawiki/php-1.34.0-wmf.6/includes/Title.php(2185): Title->userCan(string, User, string) #3 /srv/mediawiki/php-1.34.0-wmf.6/includes/skins/SkinTemplate.php(987): Title->quickUserCan(string, User) #4 /srv/mediawiki/php-1.34.0-wmf.6/includes/skins/SkinTemplate.php(464): SkinTemplate->buildContentNavigationUrls() #5 /srv/mediawiki/php-1.34.0-wmf.6/includes/skins/SkinTemplate.php(228): SkinTemplate->prepareQuickTemplate() #6 /srv/mediawiki/php-1.34.0-wmf.6/includes/OutputPage.php(2749): SkinTemplate->outputPage() #7 /srv/mediawiki/php-1.34.0-wmf.6/includes/exception/MWExceptionRenderer.php(134): OutputPage->output() #8 /srv/mediawiki/php-1.34.0-wmf.6/includes/exception/MWExceptionRenderer.php(53): MWExceptionRenderer::reportHTML(Error) #9 /srv/mediawiki/php-1.34.0-wmf.6/includes/exception/MWExceptionHandler.php(121): MWExceptionRenderer::output(Error, integer) #10 /srv/mediawiki/php-1.34.0-wmf.6/includes/exception/MWExceptionHandler.php(195): MWExceptionHandler::report(Error) #11 /srv/mediawiki/php-1.34.0-wmf.6/includes/MediaWiki.php(545): MWExceptionHandler::handleException(Error) #12 /srv/mediawiki/php-1.34.0-wmf.6/index.php(42): MediaWiki->run()
Count 1,974 Host mw1273 / php72 Duration 15-20 minutes
GlobalVarConfig::get: undefined option[{exception_id}] {exception_url} ConfigException from line 53 of /srv/mediawiki/php-1.34.0-wmf.6/includes/config/GlobalVarConfig.php: GlobalVarConfig::get: undefined option: 'UseES'
Count 895 exceptions host mw1326 / php72 Duration ~ 10 minutes
Two different corruptions on the same serverMWException: Invalid callback \Wikibase\Client\Hooks\MagicWordHookHandlers::onMagicWordwgVariableID in hooks for MagicWordwgVariableIDs #0 /srv/mediawiki/php-1.34.0-wmf.6/includes/Hooks.php … #9 /srv/mediawiki/php-1.34.0-wmf.6/api.php(87): ApiMain->execute()
Host mw1227 / php72 Duration 18:51 (1 minute)
Host mw1227 / php72 Duration 18:50 (1 minute)