Overview
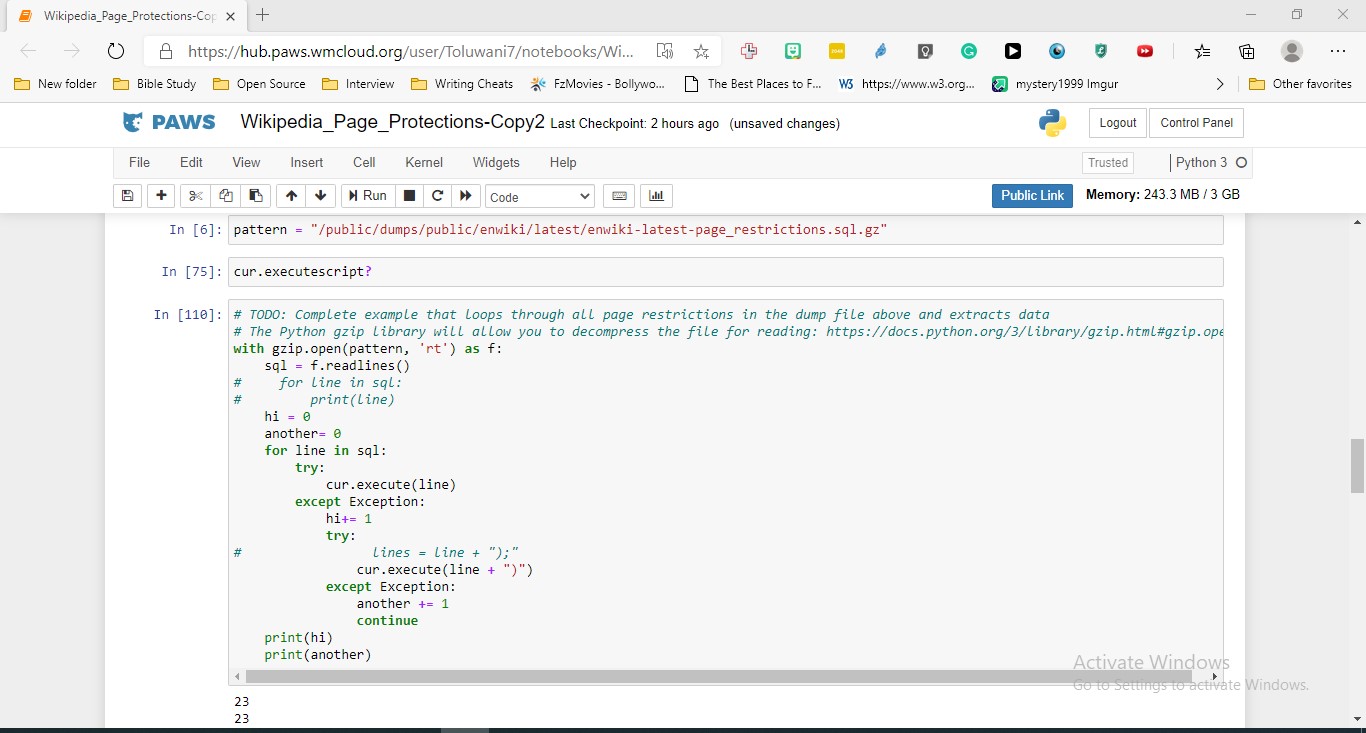
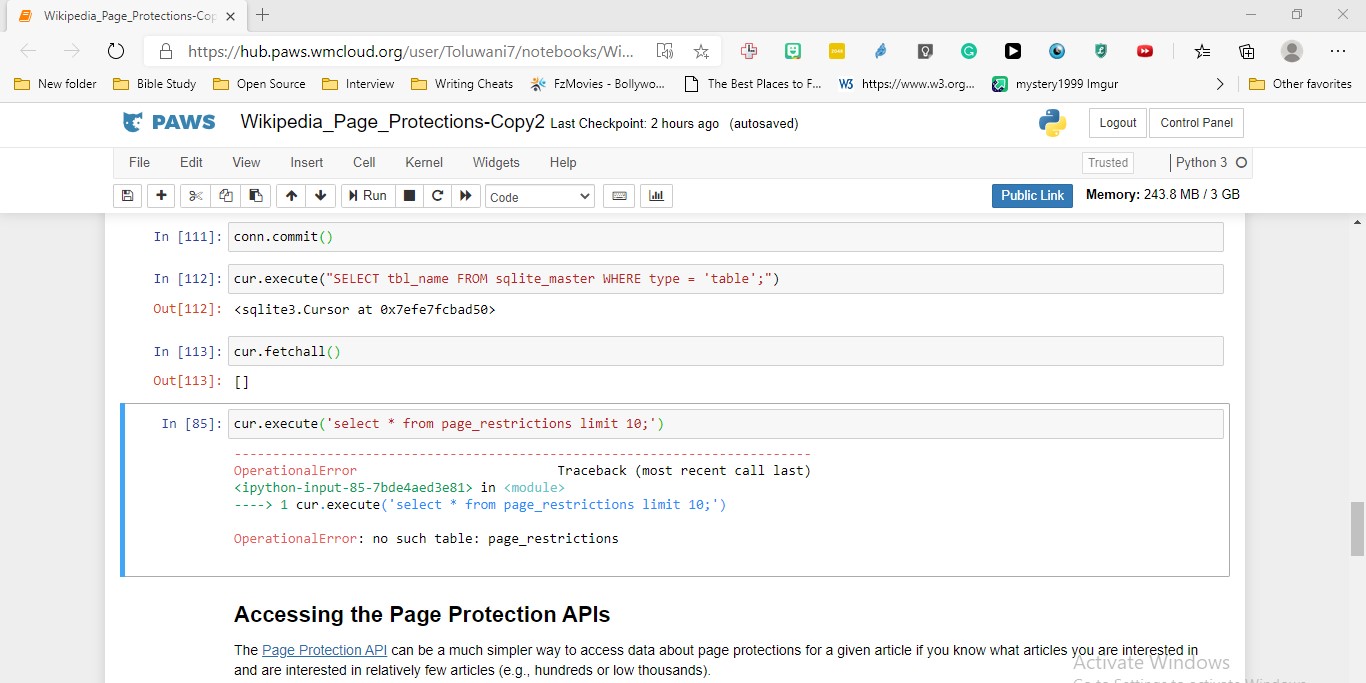
Create your own PAWS notebook tutorial (see set-up below) that completes the TODOs provided in this notebook. The full Outreachy project will involve more comprehensive coding than what is being asked for here (and some opportunities for additional explorations as desired), but this task will introduce some of the APIs and concepts that will be used for that full task and give us a sense of your Python skills, how well you work with new data, and documentation of your code. We are not expecting perfection -- give it your best shot! See this example of working with Wikidata data as an example of what a completed notebook tutorial might look like.
Set-up
- Make sure that you can login to the PAWS service with your wiki account: https://paws.wmflabs.org/paws/hub
- Using this notebook as a starting point, create your own notebook (see these instructions for forking the notebook to start with) and complete the functions / analyses. All PAWS notebooks have the option of generating a public link, which can be shared back so that we can evaluate what you did. Use a mixture of code cells and markdown to document what you find and your thoughts.
- As you have questions, feel free to add comments to this task (and please don't hesitate to answer other applicant's questions if you can help)
- If you feel you have completed your notebook, you may request feedback and we will provide high-level feedback on what is good and what is missing. To do so, send an email to your mentor with the link to your public PAWS notebook. We will try to make time to give this feedback at least once to anyone who would like it.
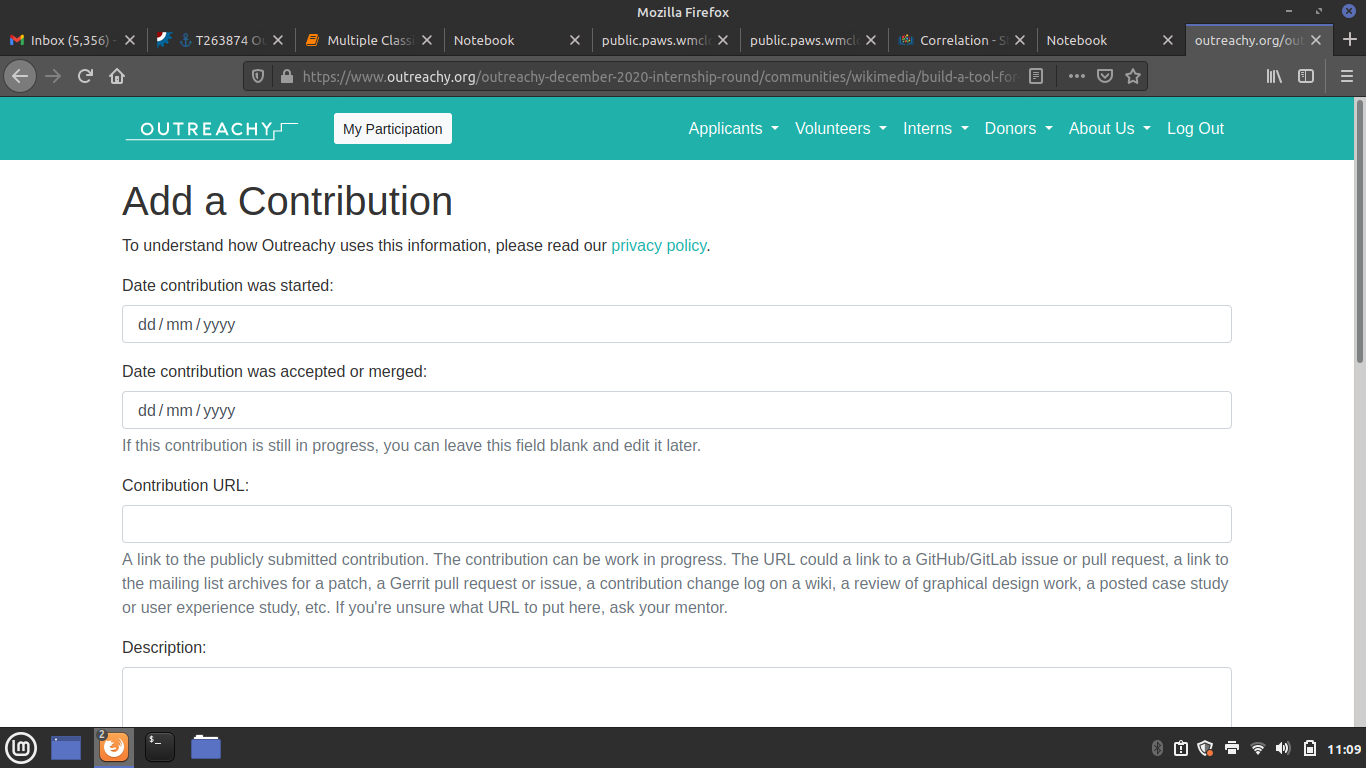
- When you feel you are happy with your notebook, you should include the public link in your final Outreachy project application as a recorded contribution. You may record contributions as you go as well to track progress.