| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Open | None | T189339 An expert panel to produce recommendations on open data sharing for public good | |||
| Resolved | • Nuria | T267283 Evaluate a differentially private solution to release wikipedia's project-title-country data | |||
| Resolved | • Nuria | T280385 Apache Beam go prototype code for DP evaluation |
Event Timeline
Hi all — I'm Hal Triedman, the new Privacy Engineering intern. Over the last few days, I've been working on re-implementing the tool that @Isaac made (https://diff-privacy.toolforge.org) using Go's Apache Beam SDK and Google's Privacy on Beam package, rather than Python, Flask, and hand-coded DP functions.
I don't yet have access to the pageview_hourly dataset (I only started two weeks ago), so for the moment I'm taking a simplistic approach of creating faux session data from the pageview API. I understand that that is not the actual schema of the data, and the pipeline will look more like this example, but I need to get started somewhere, because my understanding is that Beam won't work with preaggregated data. This data is created with the following assumptions:
- Each session has a unique integer ID
- Each session comprises a single page visit
On that data, I'm running two count functions — one using normal Beam, and the other using Privacy on Beam. I currently have it running on my local machine, and am working to get it up to Toolforge in the next few days.
Thanks for starting on this @Htriedman ! I wanted to elevate something that has been discussed in different places and impacts the implementation approach, which is: what is our privacy unit? It's not a blocker yet but something we will have to decide on that will affect the code. There are two main approaches that we can choose between (I'm largely pulling from @TedTed's comment in T267283#6607616 with some additional context of my own):
- User:
- The goal is to limit the number of pageviews any given individual contributes to a data release to some maximum threshold -- e.g., 5 pageviews per day -- so that you can't tell whether they are part of the data release. In theory this provides really strong individual privacy guarantees and in practice it's a bit dicey for Wikimedia because we don't track users so it's hard to enforce a threshold.
- This is a pretty commonplace approach by other organizations doing differential privacy because they do track users via their accounts and so the theory matches well with the practical.
- Providing a guarantees that no one can determine if any given person contributed any pageviews to a data release is useful for a couple of reasons:
- Editors have a very well-documented string of pageviews (in terms of pages they edited) and if someone was trying to identify a particular editor and whether they were from a given country, they might be able to determine this from a data release that didn't provide user-level privacy.
- By enforcing user-level privacy, we are reducing the impact any given person should be able to have on the dataset. In certain ways, this makes the dataset more robust because it helps to ensure that it reflects many readers' interests etc. instead of just a few prolific readers. Without additional filtering, an individual e.g., on a desktop computer could contribute up to 800 pageviews per day to the dataset before they'd be labeled as automated and filtered out.
- In practice, going with a user-level privacy unit is difficult at Wikimedia because we don't track readers in this way so it means we need a proxy for "user" that would likely be user-agent (device) + IP address (location) -- i.e. userhash. This currently works okay over the time period of e.g., 1 day, but also suffers for mobile users (IP addresses change more frequently) and could suffer further with Chrome's proposed reduction of the user-agent to a much more generic string (T242825). This introduces some hesitation into trusting that there is a nice 1:1 mapping between userhashes and individuals in our data. For example, individuals with multiple devices or no fixed IP address will have their data spread out amongst many userhashes and thus the filtering will not help them much. Conversely, shared IP proxies and Chrome's proposed changes may mean that we're combining many individuals' data together under a single userhash and thus filtering out much more than we ideally would.
- For implementation, this would mean that you're probably starting with a table of individual pageviews with associated userhashes and then I assume Privacy on Beam does the requisite filtering / counting based on your input parameters.
- Pageview:
- We would do almost no filtering of the data and make no assumptions about who contributed which pageview. We will still be able to guarantee that any given pageview will be private but patterns in the aggregate might reveal information about individuals -- e.g., editors who edit many different pages would be at increased risk of having their country revealed. In practice it would be quite hard to deidentify them but there would be no guarantees of privacy for their whole pattern of pageviews.
- NOTE: if we go this route, we could try to filter out editors from the data separately from the differential privacy aspect as they are our most at-risk group, but we still lose our formal guarantees.
- The allure of this approach is it simplicity and transparency -- we don't have to make assumptions about our userhashes that may turn out to be incorrect. We probably choose more conservative privacy parameters to account for the lower guarantees. Most readers still get excellent protection (assuming they don't read many pages per day) and other controls like the threshold at which we release data will all combine to make this still pretty privacy-protecting.
- For implementation, you would likely follow the suggestion here from TedTed: T267283#6608103
- We would do almost no filtering of the data and make no assumptions about who contributed which pageview. We will still be able to guarantee that any given pageview will be private but patterns in the aggregate might reveal information about individuals -- e.g., editors who edit many different pages would be at increased risk of having their country revealed. In practice it would be quite hard to deidentify them but there would be no guarantees of privacy for their whole pattern of pageviews.
I go back and forth about which of these approaches I think is better for our situation. User is more standard and has stronger guarantees but more complicated and increasingly less stable unless we come up with a better proxy. Pageview provides less guarantees upfront (especially for editors) but is a lot simpler. I am willing to support either with the caveat that if we move forward with pageview then I think we need to discuss what additional filtering to do to protect editors as they are the most at-risk group here (there's a related task to this: T277785).
User is more standard and has stronger guarantees but more complicated
Also, our privacy policy prevent us from keeping data at the user level, so DP notions that are user centric will not really serve our use case. I doubt they serve the case of any service you can use while not authenticated.
Just wanted to give you a quick status update — I have a somewhat functional re-implementation of @Isaac's tool using Golang/Beam up and running locally. I'm still working on getting it working/hosted in Toolforge (which doesn't as a service play very nicely with Go quite yet), but I'm hoping that should be done this week.
If anyone wants to play around with it locally for the moment, it's publicly available here: https://github.com/htried/wiki-diff-privacy
The readme has documentation of how to get it up and running. Let me know if you have any questions!
Also, our privacy policy prevent us from keeping data at the user level, so DP notions that are user centric will not really serve our use case. I doubt they serve the case of any service you can use while not authenticated.
@Nuria User-level privacy would not require retaining user-level data. The privacy unit just dictates how we filter the initial data, but once the filtering is done, there is no need to retain the userhashes and the final dataset will have the exact same format. For user-level privacy, we could easily work within the 90-day retention. We would probably start with pageview_actor and then just apply the filtering to arrive at the final <country, language, article, count> tuples.
The readme has documentation of how to get it up and running. Let me know if you have any questions!
Looks great @Htriedman ! A few quick thoughts / questions:
- You mention processing 500,000 rows in the README. Am I correct in assuming this is the process: 1) gather top-50 viewed articles from API for that language, 2) de-aggregate the data and load into database so that e.g., an article with 50,000 pageviews becomes 50,000 separate rows, 3) extract the data and run through the diff-privacy framework (any filtering + addition of noise), 4) return privacy-aware counts.
- If so, then I'm assuming the ~90 seconds to process 500,000 rows is vastly concentrated in step 2 and we should expect this to run pretty quickly on the cluster?
- You're applying pageview-level privacy, which makes sense because you don't have access to userhashes. I'm assuming switching to user-level privacy would be very simple though and not change the processing time because it would just be switching a synthetic userhash for a real one (that actually has some duplicates)?
- This might be a rabbit hole so I wouldn't spend too much time on it, but can you think of a simple way of realistically simulating user-level privacy? For example, I could provide you with data on what proportion of pageviews comes from userhashes w/ 1 pageview, 2 pageviews, ..., 800 pageviews. If there's a simple way to randomly assign pageviews to users such that the end distribution matches this data, that would be great because then we could play with parameters and see how much data is filtered out etc.
- You mention processing 500,000 rows in the README. Am I correct in assuming this is the process: 1) gather top-50 viewed articles from API for that language, 2) de-aggregate the data and load into database so that e.g., an article with 50,000 pageviews becomes 50,000 separate rows, 3) extract the data and run through the diff-privacy framework (any filtering + addition of noise), 4) return privacy-aware counts.
@Isaac, that is exactly right.
- If so, then I'm assuming the ~90 seconds to process 500,000 rows is vastly concentrated in step 2 and we should expect this to run pretty quickly on the cluster?
Exactly. Right now, I'm using the direct runner, which runs things locally. There's also a Apache Spark runner, and we should be able to switch between the two relatively easily in the code. I picked languages with ~500,000 daily views from the top 50 pages because I wanted to run it locally, but English usually is are 13-14 million daily views from the top 50 pages. Even scaling up by a factor of ~30x, I would presume that these aggregations will run decently quickly on the cluster.
Another thing to note about runtime is that for each language, the DP count is happening 16 times (to illustrate the effects of combinations of values, where epsilon in {0.1, 0.5, 1, 5} and delta in {10e-9, 10e-8, 10e-7, 10e-6}). Once we nail down a privacy unit, it will be much easier to provide a single tuple of <epsilon, delta> for each language. Tell me if I'm wrong, but for the pageview model epsilon = 1, and for the user model epsilon = whatever we decide the maximum number of views is. Delta can probably be computed dynamically for each language-country combo, and will be 1/f(||db||), where db is the database, ||db|| is the size of the database, and f(x) >>> poly(x) for all x. All of that is to say: I'd expect the runtime to go way down once we've constrained our hyperparameters.
- You're applying pageview-level privacy, which makes sense because you don't have access to userhashes. I'm assuming switching to user-level privacy would be very simple though and not change the processing time because it would just be switching a synthetic userhash for a real one (that actually has some duplicates)?
- This might be a rabbit hole so I wouldn't spend too much time on it, but can you think of a simple way of realistically simulating user-level privacy? For example, I could provide you with data on what proportion of pageviews comes from userhashes w/ 1 pageview, 2 pageviews, ..., 800 pageviews. If there's a simple way to randomly assign pageviews to users such that the end distribution matches this data, that would be great because then we could play with parameters and see how much data is filtered out etc.
Yep, right now my synthetic pageview id is just a monotonically increasing integer. All that would change, I think, is adding a column to that db with a synthetic userhash and making some alterations to the context in which the DP count function is called in beam.go. And as far as doing that analysis with synthetic data goes I would just need the probability distribution PV of the form (num_views, proportion) of what proportion of pageviews come from users with 1 view, 2 views, ..., n views. Then the algorithm could look like (written in pythonish psuedocode):
PV = list of tuples of form (num_views, proportion), where sum(PV.proportion) = 1
users = map from int --> list of strings
pageviews = list of pageviews
output = list of tuples of form (id, page)
for p in PV:
estimated_users = (p.proportion * len(pageviews)) / p.num_views
for i in estimated_users:
id = generate_synthetic_hash()
users[p.num_views].append(id)
counter = 0
pageviews = shuffle(pageviews) # randomize pageview order
for i in len(pageviews):
if i >= PV[counter].proportion * len(pageviews):
counter++
output.append((random.uniform(users[counter]), pageviews[i]))
send output to the dbOf course, there are a couple of problems with this approach — the top 50 pages can be news-driven, so are probably disproportionately likely to be 1- or 2-page visits; this approach could end up with a user with 700 pageviews, 250 of which are the homepage. Let me know if you think it's worth it to go down this rabbit hole in dev.
Just wanted to update with some of the work that @Htriedman has done and discussions we've had off-ticket (feel free to jump in Hal to correct / add / etc.):
- Moved the tool from local/toolforge to Cloud VPS for greater control over installing packages etc.
- Still some basic UI / styling fixes, but Hal got the Apache-beam based version of the tool up and running on Cloud VPS! Check it out: https://diff-privacy-beam.wmcloud.org/
- Right now, the tool is implementing pageview-based privacy like the earlier Python-based prototype (see T280385#7022112) but I generated some representative statistics on pageviews-per-user for large-, medium-, and small-sized wikis that he's working on implementing to simulate user-based privacy. It won't be perfect but hopefully will give a sense of the impact of additional filtering that user-based privacy does.
- I have some lingering confusion on the role of delta in the Apache-beam implementation because my understanding is that parameter shouldn't be required for basic epsilon differential privacy w/ the laplace distribution.
- Hal put together some scripts to make it easy to deploy this tool on Cloud VPS and update it as needed: https://github.com/htried/wiki-diff-privacy/tree/main/config
- Once a few other small fixes are made, probably ready to think about how to achieve consensus on the privacy-unit question and what it would take to migrate some of this to the cluster where the Apache Spark runner could be tested
I love the demo, congrats for your work on this!
I have some lingering confusion on the role of delta in the Apache-beam implementation because my understanding is that parameter shouldn't be required for basic epsilon differential privacy w/ the laplace distribution.
When using the Laplace distribution, the noise doesn't consume the δ, however some of the δ is consumed by something we call partition selection.
To understand the problem, imagine two neighboring pageview datasets, one that has exactly one view associated with the page Blanquette de veau, and the other that has exactly the same data, except no view is associated with this page. If all you do is add noise to the counts for the pages you see in your data, then the page will appear in the output statistic of the first dataset, but not the output of the second dataset: this would allow an attacker to distinguish between the two possibilities, and break the differential privacy property. To prevent this, one option is to consume the δ budget to threshold the output counts. A longer explanation of this phenomenon can be found on my blog. (Note that, in certain cases, Privacy on Beam actually uses a smarter partition selection technique than the one described there, but the idea is the same.)
If you want to avoid this, you can use the PublicPartitions feature of Privacy on Beam: instead of finding the list of pages from the private data, you can specify a predefined list of all the pages (importantly: including those that don't have any data). Then, you don't have to do any thresholding, and the entire computation can be ε-DP (with δ=0). As a side-effect, all pages will now appear in the output, even those who didn't have any data to begin with.
Side-note inspired by a remark from my colleague Mirac: given that the sensitivity is fixed to 1 in the code (which makes sense if using a pageview as the privacy unit), what is the meaning of setting it to a different value in the web UI?
@TedTed, thanks for explaining thresholding and why δ is necessary, even with Laplace noise. Really useful to know what's happening under the hood of Privacy on Beam.
To your second question, I'm currently in the middle of implementing simulated user-level privacy guarantees, which I'll hopefully have done today or Monday. Part of that is going to be making the sensitivity configurable — 1 in the case of pageview-level privacy, and either 5 or 10 in the case of user-level privacy. My apologies for leaving a confusing relic in the UI; it's still definitely a work in progress.
When using the Laplace distribution, the noise doesn't consume the δ, however some of the δ is consumed by something we call partition selection.
@TedTed thanks for this update, the delta component now makes much more sense. I see that I was doing this already in the initial Python prototype -- i.e. I also was trying to determine the appropriate threshold for data release such that we didn't have to also add noise to the millions of 0-pageview pages / need a 100% accurate accounting of what pages existed on any given day. I just hadn't connected this parameter to the role of delta. Even though it's technically possible to provide Beam w/ a list of all possible pages, I think I'd advocate for the library's delta/threshold approach for its simplicity. We could always revisit that if we moved to releasing fuller differentially-private datasets for researchers looking to do large-scale quantitative analyses that required the ability to e.g., accurately compute averages over all articles. Right now I think a top-k list for editor review is still the main motivation for this work though and that aligns nicely with throwing out the long-tail of low pageview data.
what it would take to migrate some of this to the cluster where the Apache Spark runner could be tested
We probably do not want to install beam on the cluster just for this experiment so can we use jupyter rather and run beam on python? https://beam.apache.org/get-started/quickstart-py/
Hi all — just finished updating the demo to get it into a good place. You can see the finished product (UI, user- and pageview-level privacy, etc.) at https://diff-privacy-beam.wmcloud.org. Please let me know what you think, and if there are any next steps that any of you can see toward getting this into a production prototype. Thanks for all the help so far :)
We probably do not want to install beam on the cluster just for this experiment so can we use jupyter rather and run beam on python? https://beam.apache.org/get-started/quickstart-py/
@Nuria this is where I get out of my expertise, but my understanding is the Beam differential privacy library is only available in Go (and thus needs the Go SDK to run). So not sure that Python is an option unless the differential privacy library gets ported to Python. Hal's tool uses the Beam Go SDK so we have confirmation that it works with a local runner (SQLlite backend) and now the main questions are:
- Policy: what configuration of parameters / privacy do we use?
- Engineering: does the Apache Beam differential privacy library work on our cluster? Hal has shown that it works using a local SQLlite database so really there isn't any more intermediate steps to test and next would be trying it with the Spark backend runner. This starts to go over my head though I assume there are two parts to this:
- Make sure Go Beam SDK can be installed on the cluster (or wherever this job would be run from)
- Swap out the SQLlite backend for the Spark runners and test this out on the data in HDFS (a simple choice is using wmf.pageview_actor because that will support both pageview-level privacy and user-level privacy depending on our choice)
I'm making this high so we can try and pick it up, but it's still behind lots of other work. The proof of concept is very useful, thanks for the good work @Htriedman
I'm making this high so we can try and pick it up, but it's still behind lots of other work. The proof of concept is very useful, thanks for the good work
Thanks @Milimetric!
@Nuria (and others) I was pondering how we might achieve user-level privacy while reducing the impact of the assumptions that render it imperfect in our context. User-level privacy really is what we should be aiming for (it's a much stronger privacy guarantee) but I also understand the hesitation to base it on assumptions about user identification that are shaky -- i.e. how do we confidently limit how many pageviews an individual contributes to a dataset given the lessening in utility of our current user proxy (IP + UA) as a result of increased mobile views (IPs more likely to shift over the course of a day) and some of the changes that Chrome wants to push to make user-agents far more generic.
I came up with two possible approaches that I thought maybe we could consider (though I think I like the second one much better). Both require us to decide in advance on a universal sensitivity value (I call it k in the examples) for all differentially-private datasets but that's a very acceptable trade-off in my opinion. We could always still decrease the epsilon value (add more noise) if there was a particularly sensitive dataset we were releasing.
Approach 1: Fingerprint and toss
Collect an identifying cookie but only keep it for 24 hours to filter our pageview datasets and then purge it. Details:
- For a reader's first pageview in a day, we'd add a unique cookie to their browser that is set to expire at midnight UTC. This would be an exact fingerprint so unless that person clears their cache, we'd be able to see exactly which pages were viewed by that device+browser on that day (without relying on IP/UA). The midnight UTC expiry would be to ensure that it changes daily so we could never use it to connect readers across days.
- The unique cookie would not be stored in any tables (we'd have to be careful to filter it from webrequests) but would be used by a daily job to create a pre-filtered differentially-private pageview table. In essence, we'd have a second pageview_actor dataset (exact same fields) except some filtering would have already been applied to it to ensure that no device+browser contributed more than k pageviews to the table on any given day.
- The benefit from this approach is exactness without actually retaining any additional sensitive data (beyond the 24 hours needed to generate the table) if we implement it correctly.
- The obvious issue is that we've avoided this sort of fingerprint cookie for very obvious privacy concerns so going this route requires users to trust that we aren't retaining it and we'd obviously have to talk with Legal about it.
Approach 2: User-side filtering
We put a generic counter in the user's cookies that tracks how many pageviews they've viewed that day. When that counter exceeds k, all further pageviews that day are sent with a header telling us to filter them from differentially-private datasets.
- I see this is akin to the last-access cookie or session-length metrics in that it helps us achieve our goal without actually fingerprinting users (yay!). The counter cookie would expire at midnight UTC too so it would never store data locally on the device beyond 24 hours.
- The benefit of this approach is that it doesn't require any additional invasive tracking of users so it's much more transparent and there's no opportunity for us to screw it up and accidentally retain sensitive information. It's also way simpler -- all the logic would be client-side and it would be an additional key in the X-Analytics header but I don't think it would require us to purge any new data.
- The downside of this is ideally when we do filtering of a user's pageviews to the max threshold, it would be a random selection of pageviews, whereas this approach would just filter down to the first ten pageviews. I think this is unlikely to introduce bias but it's also not ideal.
My thoughts on the proposals:
- Anything related to fingerprinting is a slippery slope, today we toss it, and in the future we might not. Like @BBlack famously said: 'we should protect ourselves from ourselves from the future'. Then, given that the proposal with minimum changes can be used to track users daily behavior, I do not think we should consider it.
- Requiring a new variable to release this data (true for both approaches) fundamentally prevents us from releasing existing data that does not have those values already, so -ideally- we would come up with a strategy that does not require any additional data from the one we currently have.
Further thoughts on proposal #2
Approach 2: User-side filtering
We put a generic counter in the user's cookies that tracks how many pageviews they've viewed that day. When that counter exceeds k, all further pageviews that day are sent with a header telling us to filter them from >differentially-private datasets.
I think the vision behind this idea is not to include all pageviews from heavy users (is this correct?) but I am not sure it truly works as we are releasing ALL pageviews per wiki per hour in the hourly pageview files, which means that any observer knows all pageviews not included in the DP dataset (w/o the country dimension)
(1) DP dataset = some pageviews (where n<k) per article per wiki per country + noise
(2) pageview_hourly dataset = all pageviews per article per hour per wiki
Seems (2) will already leak a lot of the data not contained in (1), specially telling for heavy users. The minimun time interval for (1) to be useful is daily so you could find (within a day) the tally of pageviews for every one article that is missing in the DP dataset, the tally would not tell you the country distribution of missing pageviews, but the actual missing pageviews (over the k threshold) will be there.
Maybe I am off here cause I thought we were trying to protect against releasing location of users with a few pageviews thus protecting those users whose number of pageviews is rather small, not large. But i see from other work (pageviews per country) that we have tried to remove contributions from power users before. Please do let me know if I am missing the point you are trying to make.
Thanks @Nuria for weighing in!
Anything related to fingerprinting is a slippery slope, today we toss it, and in the future we might not.
Agreed -- let's take Proposal 1 (fingerprinting and toss) off the table and focus on the User-side filtering!
Requiring a new variable to release this data (true for both approaches) fundamentally prevents us from releasing existing data that does not have those values already, so -ideally- we would come up with a strategy that does not require any additional data from the one we currently have.
I would push back on this as a requirement. A few thoughts:
- While back-releasing differentially-private datasets would be nice, I'm less concerned with that because our use case right now is having new datasets to guide editors so historical data is probably of less use at the moment. For researchers interested in historical data, there will always be the NDA option if the research questions are deemed important enough. All to say, I personally value building the right solution moving forward over choosing a solution that is easier to apply consistently to past datasets.
- Historical data feels less sensitive to me so I would actually be much more okay with doing pageview-level privacy (which wouldn't require these additional filters) there because a lot of my concerns about threats to editors are minimized by virtue of it being past data (though I'd definitely want Security to weigh in on that). It's not ideal because then the two datasets aren't directly comparable but that's not exactly a new problem when it comes to pageview data :)
I think the vision behind this idea is not to include all pageviews from heavy users (is this correct?) but I am not sure it truly works as we are releasing ALL pageviews per wiki per hour in the hourly pageview files, which means that any observer knows all pageviews not included in the DP dataset (w/o the country dimension)
Yes to particular focus on limiting pageviews from heavy users. As for existence of other pageview datasets: differential privacy assumes the existence of these datasets and just promises that the new differentially-private dataset won't release substantially more information about an individual. So if we want to discuss concerns with the existing public datasets, that's a separate discussion (though my feeling is that the lack of country information in those datasets makes them largely harmless). See T267283#6774889 for a better explanation. But the point is you can a) know that an article received exactly 100 pageviews on a given day, b) somehow know for certain that 99 people from Country A viewed that article that day, c) know that it was edited by an user from an unknown country, and, d) we can still release a differentially-private dataset that says 100 pageviews to that article came from Country A and the noise/filtering will guarantee that you won't be able to say with any confidence that that unknown user was from Country A or not.
Maybe I am off here cause I thought we were trying to protect against releasing location of users with a few pageviews thus protecting those users whose number of pageviews is rather small, not large. Please do let me know if I am missing the point you are trying to make.
Users with a few pageviews are much less concerning for me as they're much more likely to be "covered" by the noise. However, power readers (who often also edit) are, in my opinion, both a) more sensitive because edit activity is much more likely to cause a govt, etc. to try to identify you than just reading, and, b) more vulnerable because they have more pageviews so more places where someone might identify them if their contributions aren't appropriately filtered.
Thanks @Isaac and @Nuria for the in-depth discussion of the relative pros and cons of these two approaches, and for the deep dive on user-side filtering. I wanted to chime in with some more context that I recently learned about putting DP into production, regardless of how we filter/limit pageviews. These considerations may be relevant as we move toward creating this as a service.
Over the last week, I've been meeting and corresponding with @fkaelin and @gmodena about productionizing these systems. There are two main approaches: running DP counts in a distributed fashion on Spark and running DP counts on a single large analytics machine. I'll go through their relative pros and cons, as well as the open questions that remain for each approach.
Distributed count on Spark: Doing a distributed differentially-private count using Privacy on Beam is possible, but it may be tough/buggy, because we would have to put together (a) some way of compiling/submitting the Beam pipeline that isn’t reliant on Docker, and (b) some way of writing from Beam to HDFS using Golang, which doesn’t yet exist. We also might find out that not all Beam primitives we need are available at runtime on Spark.
- Pros of doing this:
- If we could get it working, it might be the most generalizable way of doing DP at WMF, because Privacy on Beam is highly abstracted. We wouldn’t have to deal with any of the low-level complexities of DP that will come with coding everything ourselves.
- It is easier to create external modes of access (i.e. an API endpoint) from HDFS than it is from the analytics cluster.
- Less use of analytics team compute resources and more scalability.
- Cons of doing this:
- Both Go and Privacy on Beam are experimental and subject to change, so hacking our way through this problem might not be sustainable as far as technical debt/not having things randomly break at some point in the future.
- We would have to figure out/create two substantial pieces of data infrastructure (compiling without Docker and writing to HDFS) to get it to work.
- Things to explore:
- There may be some Beam primitives that are not available at runtime on Spark. I've dug into the debug log of the current DP pipeline and compared it to the Beam Capability Matrix, and don't think there will be any issues, particularly if we use batch mode — right now the capabilities being used are ParDo, CoGroupByKey, and Combine, all of which are supported on Spark.
- Implementing some form of DP using the Java differential privacy library from Google, which would be significantly easier to deploy on our infrastructure, which is heavily JVM based.
- It is still unclear whether the Google Java DP library will be conducive to MapReduce. I personally believe it likely will be, but that is something we have to investigate if we go this route.
Non-distributed count on an analytics machine: It might also be possible to do a differentially-private count on a single machine within the Analytics cluster (likely on stat1007, which I think has a lot of RAM). This could be either with Privacy on Beam (using the local runner) or with Google’s Java/Go implementations of DP.
- Pros of doing this:
- Will almost certainly be a lot simpler than figuring out/executing all the necessary steps for doing things distributed. It’s much more likely to just work.
- Cons of doing this:
- Could only publish this information as a static dataset (at https://analytics.wikimedia.org/published/).
- Less generalizable/applicable to other DP stats that we might want to release in the future
- Less scalable, could use a lot of analytics team compute resources
- Things to explore:
- How to filter to just sensitivity pageviews per user?
- Should we preaggregate some of this information to make it computationally easier on a single machine? What are the functional differences between DP count (if not preaggregated) and DP sum (if preaggregated)?
Thanks @Htriedman for the deep dive. A few notes on our tooling, in case this helps:
- Privacy on Beam is still marked experimental out of caution, but we don't expect the API to change in backwards-incompatible ways. My understanding is that it's the same for the Apache Beam Go SDK.
- All our building block libraries, including Java, are made to support large-scale distributed computations and integrations in frameworks like MapReduce. In fact, they're used internally for scalable end-to-end tools (equivalent to Privacy on Beam) in C++ & Java, which we have not made open-source (yet) for tricky technical reasons. We don't have concrete plans to do so, but if we were to open-source the Java version, would it solve your problem entirely, or would point (a) (compiling without Docker) still be a problem?
- The local runner for Apache Beam in Go is not very well optimized, at least last time we checked. It's worth trying, but I would not be surprised if you're unable to use it at your scale, even on a beefy machine.
- For DP, the main thing that needs to happen during the aggregation stage is the contribution bounding. This is also the computationally expensive part. If you do it manually, then you could use one of our building block libraries directly on the aggregated metrics, rather than Privacy on Beam on the raw data. It's less robust (since it adds assumptions to your infra), and it only works for the simplest aggregations like sums and counts, but it's an option.
- If you use pageviews as a privacy unit and all you do is count pageviews, then contribution bounding isn't necessary at all.
It might also be possible to do a differentially-private count on a single machine within the Analytics cluster (likely on stat1007, which I think has a lot of RAM). This could be either with Privacy on Beam >(using the local runner) or with Google’s Java/Go implementations of DP.
Part of this task is to make data releases of this type part of the cycle of data releases at WMF so I do not think we should pursue the option of treating this project like a one off data release, rather we should think of it running it as any other data flow as a core requirement.
I also suspect that we will run into limitations cause large computing flows are mean to be run in a distributed manner, trying to run those "mainframe style" frequently runs into issues of memory, concurrency, disk space..( also, while 1007 might be not a small machine is a shared resource and it has limits to resources any one user can consume)
We don't have concrete plans to do so, but if we were to open-source the Java version, would it solve your problem entirely, or would point (a) (compiling without Docker) still be a problem?
Probably will help as spark integrates with java more easily, so even a version that is mean to be dockerized if jars (and code) are available can probably be repurposed to work with spark. So, ya, i think releasing the java version it will be of great help.
Part of this task is to make data releases of this type part of the cycle of data releases at WMF so I do not think we should pursue the option of treating this project like a one off data release, rather we should think of it running it as any other data flow as a core requirement.
@Nuria I completely agree on that front — focusing on running DP on WMF's distributed architecture might be a bit more work on the front-end, but is ultimately more scalable, flexible, and oriented toward the wider use of DP at the Foundation.
One point of confusion that I have on a conceptual level: currently we apply what we loosely call a k-anonymity threshold, e.g. there would need to be at least k pageviews for a given tuple (time, wiki, page, country) for that tuple to be included in a public dataset. As @Nuria pointed out, we already release pageview counts without geographical dimension, and it would be great to find a way to include e.g. the country. One intuitive concern in the risk that a bad actor can identify users who read pages on a smaller wiki from a country that has few speakers of that language - e.g. a dissident who had to flee their home country. The k-anonymity approach forces us to define what an acceptable risk is (is it 100 pages views for a given page from a given country? 1000?), which is difficult and rather handwavey. However, that risk is not based on plausible deniability - e.g. if a bad actor is looking to identify users who have read a particular page and there were 68 views from a given country, it doesn't seem sufficient to be able to say that 68 is not the "true number" because we applied DP.
- Does this concern relate to a formal definition/parameter in differential privacy?
- How does the concept of the maximal contribution by a single unit of privacy (e.g the reader) influence that risk? E.g. assuming that the 68 views actually come from a single reader at risk.
- Could/should we apply k-anonymity thresholds on top of the DP dataset?
Infrastructure comments:
- there are a few layers in the easiest and most direct option to try: go sdk -> portable beam runner that can submit to yarn without docker on a stat machine -> spark job on yarn. These path is road less travelled it seems, but that is not a reason not to attempt it. It is a reason to be cautious of how to invest resources if it doesn't work as hoped.
- bypassing docker for the job-server seems fairly straight forward (https://github.com/apache/beam/tree/master/runners/spark/job-server)
- we can also add the flink runner for apache beam to the list of things to try before starting to hack on spark if there is an issue
- pre-computation to limit user aggregation: as @TedTed pointed out, this approach would tie Privacy on Beam framework to a custom pre-aggregation we would do on spark. For webrequests logs this pre-aggregation - ie counting and limiting per (ip/ua) page view counts - will significantly reduce the data, but my intuition is that it wouldn't be enough to run the remaining steps on a beefy machine, especially since the local runners are more for testing purposes.
Small update: The Apache Beam Go SDK is about to officially become stable. Privacy on Beam's 1.0.0 release can be considered stable as soon as it's done.
We have no plans to release the Java version of Privacy on Beam at this time. There are too many technical blockers, and our OSS investment is currently focused on developing the Python version. This might be something we do in the future, but there are no clear timelines, and it's unlikely to happen this year.
One intuitive concern in the risk that a bad actor can identify users who read pages on a smaller wiki from a country that has few speakers of that language - e.g. a dissident who had to flee their home country. The k-anonymity approach forces us to define what an acceptable risk is (is it 100 pages views for a given page from a given country? 1000?), which is difficult and rather handwavey. However, that risk is not based on plausible deniability - e.g. if a bad actor is looking to identify users who have read a particular page and there were 68 views from a given country, it doesn't seem sufficient to be able to say that 68 is not the "true number" because we applied DP.
- Does this concern relate to a formal definition/parameter in differential privacy?
The keyword here is identify. You can learn something about the number of users who read pages on a smaller wiki from a country that has few speakers of that language, but you can't detect whether someone in particular is a part of that group. Indeed, if that person wasn't in the dataset, you wouldn't be able to tell the difference (probabilistically).
- How does the concept of the maximal contribution by a single unit of privacy (e.g the reader) influence that risk? E.g. assuming that the 68 views actually come from a single reader at risk.
If you tell the framework "I want to protect each reader with epsilon ε", then you can choose any value of the maximal contribution per reader, and the guarantees will still hold at the reader level. If you increase the maximal contribution, the framework will add more noise to compensate. Instead, if your privacy unit is a view and your epsilon is ε, then a user who contributes 10 views would get a theoretical protection level of 10ε.
- Could/should we apply k-anonymity thresholds on top of the DP dataset?
Whether you should is up to you, but you can do any sort of post-processing on top of a DP dataset (including a thresholding stage), and the DP guarantees will still hold.
These path is road less travelled it seems, but that is not a reason not to attempt it.
Nice
if a bad actor is looking to identify users who have read a particular page and there were 68 views from a given country, it doesn't seem sufficient to be able to say that 68 is not >the "true number" because we applied DP.
I think here we are probably using the wrong tool for the job to think about the-small-bucket problem. DP is a statistical technique that works for significant data sizes, that, and not a k-anonymity size interval is what, I think, should determine the minimum size of bucket that we use to ad noise/release data. This is to say that I am agreeing with you in that DP is not the right approach for small buckets. @TedTed 's point regarding probability is a mathematical guarantee. Now, in the, ahem, "physical word" the probability of identifying what a "malasyan speaker read on san marino" is just too high regardless of noise in a (malasyan-wiki, san marino, date) tuple so we probably never event want to consider to release such data. This has come up before in many instances and there is several phab tickets about the risk trade offs.
For webrequests logs this pre-aggregation - ie counting and limiting per (ip/ua) page view counts
I do not understand would we want to do this when the unit of privacy we are thinking about is a pageview rather than a user (other than to remove maybe high contributors to pageviews like @Isaac has mentioned before)
Thanks all for the discussion / details on the engineering side! Chiming in on some things that were discussed from a policy perspective:
For DP, the main thing that needs to happen during the aggregation stage is the contribution bounding. This is also the computationally expensive part. If you do it manually, then you could use one of our building block libraries directly on the aggregated metrics, rather than Privacy on Beam on the raw data. It's less robust (since it adds assumptions to your infra), and it only works for the simplest aggregations like sums and counts, but it's an option.
If you use pageviews as a privacy unit and all you do is count pageviews, then contribution bounding isn't necessary at all.
I think it is fair at this point to assume that we don't need the user-filtering provided by Beam and can rely just on the DP primitives. It sounds like this might greatly simplify the engineering and we have two potentially workable solutions for not needing the filtering: either we are going with pageview-level privacy or we are going with user-level privacy but implementing our own filtering to some maximum contributions (I'd like to believe via something akin to Approach #2 that I sketched out in T280385#7066575).
Could/should we apply k-anonymity thresholds on top of the DP dataset?
Now, in the, ahem, "physical word" the probability of identifying what a "malasyan speaker read on san marino" is just too high regardless of noise in a (malasyan-wiki, san marino, date) tuple so we probably never event want to consider to release such data.
Regarding this discussion about having some k-anonymity / release threshold for small pageview counts. Differential privacy provides the same guarantees for small counts that it does for large counts. It's really just a question of how useful the data is. I outlined some potential approaches under "Data Quality Parameters" in T267283#6719455. In short, we will almost certainly define a threshold below which we don't release data. This is not because of privacy reasons but because if you're adding noise to counts, at a certain point, most of the data you're releasing is noise instead of actual pageviews. So to @Nuria's point about "identifying what a malasyan speaker read on san marino", that data almost certainly won't be released because it'll mostly be noise (but if we did release it, the same privacy guarantees would apply to it). This approach is still much better than just standard k-anonymity though because we have a strong privacy guarantee and are basing our threshold off of data quality/usefulness instead. And, importantly in terms of equity, the threshold we define will probably be something around 100 or 200, which is far lower than the usual 500-1000 that we go with and should ensure that we can still release data for countries that often get left out of these datasets.
However, that risk is not based on plausible deniability - e.g. if a bad actor is looking to identify users who have read a particular page and there were 68 views from a given country, it doesn't seem sufficient to be able to say that 68 is not the "true number" because we applied DP.
To @fkaelin's point, I'll also add that I still expect that we will leave out certain countries due to elevated privacy concerns. To restate the above, differential privacy guarantees that no individual is identifiable -- i.e. plausible deniability. That probably is not sufficient in certain regions where suspicion might be enough to get someone in trouble. Furthermore, differential privacy cannot protect from broader harms -- e.g., a country imposing censorship because they are seeing a lot more pageviews that they expected to articles about sensitive topics. This country-specific filtering isn't anything new for us. We apply this filtering to many other datasets too where we believe the risks outweigh the benefits -- e.g., the Covid-19 readership dataset that was just released.
Hi,
Small update: The Apache Beam Go SDK is about to officially become stable. Privacy on Beam's 1.0.0 release can be considered stable as soon as it's done.
We had some initial degree of success compiling and executing a Privacy on Beam pipeline on a Spark portable runner (non-dockerized). One challenge we encountered is that, to the best of my knowledge, HDFS support is not yet available in the Go SDK (and portable runners). Do you maybe know if HDFS support is planned for upcoming releases?
We have no plans to release the Java version of Privacy on Beam at this time. There are too many technical blockers, and our OSS investment is currently focused on developing the Python version. This might be something we do in the future, but there are no clear timelines, and it's unlikely to happen this year.
Thanks for the pointer. I'll have a look at this implementation.
@gmodena It might also be worth considering implementing HDFS in the Beam Go SDK ourselves — the template for doing it (which you can see here, for example) is relatively simple.
There are also stable, open-source native clients for HDFS written in Go like this one, which implements canonical filesystem commands, encryption protocols, etc.
I'd be happy to dive into contributing a HDFS runner following the guidelines set out in the Beam Contribution Guide if that would be useful. Let me know!
edit: Since Python is also a first-class citizen in the Hadoop world, we might also consider following this relatively simple example set out in PipelineDP. Either way, we should come to a decision about it.
Hi everyone — I know it's been several months since this ticket has been updated, but work on implementing DP at scale in production has continued over the last several months, and I wanted to post publicly with some updates on our process:
- You can find a centralized public hub for documentation on metawiki
- Generalized explanation of why we want to deploy DP
- Discussion of how user-level pageview filtering might work (in order to enforce a stricter formal notion of user-level privacy on a structural basis)
- Discussion of the pros and cons of various systems/frameworks (specifically in the context of WMF infrastructure and resources)
- Engineers, scientists, and product managers have been meeting on a bi-weekly basis to figure out the systems we'll be using, our MVP, timeline, etc.
- I've been investigating the viability of installing/using various systems on our analytics cluster (github link)
- We've also been getting out into the community
- I met with Google's PipelineDP team to see how that framework might function in the WMF context
- Several team members attended the OpenDP 2021 Community Meeting to learn and evaluate whether or not OpenDP would work in the WMF context
- I've also been compiling some examples of production-scale DP pipelines that we can work off of — Microsoft Broadband Coverage, Apple Learning with Privacy at Scale, LinkedIn Top-k Selection, LinkedIn Labor Market Insights at Scale
Would love to hear your thoughts/get some feedback on the progress we have made so far as we plan our MVP.
There's a lot in this task I can't catch up with, but it looks more than ready, happy to help you pitch it to all the teams that would need to be involved.
Hi @Milimetric! Thanks for commenting on this task — lots has happened in the last 3-4 weeks and this served as a good reminder to update this thread as to where we currently are on this project.
Right after I posted my update on 30 September, I got an email from @TedTed (who now works at Tumult Labs) saying that their DP pipeline library safetables might be a good solution for our use cases based on our infrastructural requirements. @Isaac and I had an initial meeting with the Tumult Labs team (which went well), then did some more digging into the exact system requirements for deploying safetables on the analytics cluster (which are a small-scale engineering lift, but nothing too major).
Since then, I've been working with @TAdeleye_WMF (an amazing PM who has been helping plan this project) to flesh out project requirements, an MVP, primary and secondary milestones, etc. as we've continued to correspond and meet with Tumult Labs and work toward some sort of contracting-/support-type engagement with them. Yesterday, we sent their team a detailed memo of those requirements, and are waiting on a proposed contractual agreement in response.
Ultimately, we're hoping to have an internally-usable DP engine that data and research scientists can use for differentially-private calculations and dataset releases somewhat independently of the Privacy Engineering team, and that is subject to some external data governance/privacy budget controls. The proposed system looks something like this:
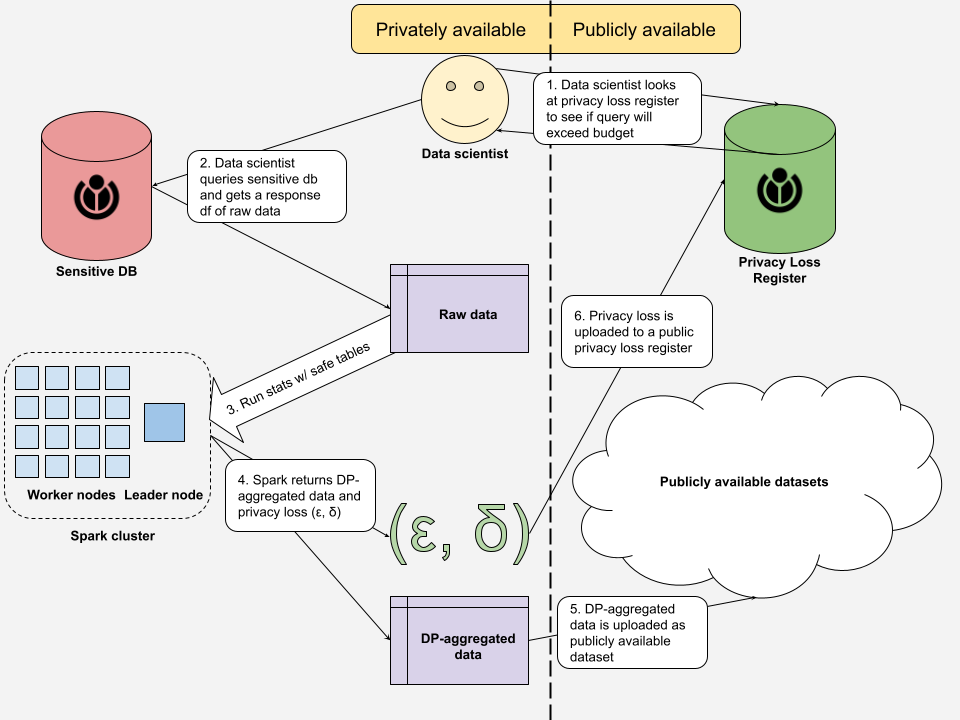
note: because our infrastructure is subject to unique constraints, we're going to be building the publicly accessible privacy loss register ourselves internally at WMF
We're asking Tumult Labs for help with the following:
- Milestone 1 — Functional deployment of safetables on WMF infra, with the following associated deliverables:
- Preliminary access to the Tumult Labs code base and resources (including an AWS JupyterHub instance Tumult Labs owns for playing around with safetables)
- A stable environment that can support running safetables in the WMF analytics cluster
- A stable instance of safetables that lives within the WMF analytics cluster, runs jobs on Apache Spark using YARN, and is accessible via a Jupyter Notebook
- Some test calculations on sample data to establish functionality
- Milestone 2 — Daily release of project-country-page-view histogram, with the following associated deliverables:
- An algorithm for the pageview histogram that can dynamically allocate privacy budget based on country and language
- Experimentation to find optimal configuration of privacy budget
- Documentation of the experimentation process
- Successful computation of the project-country-page-view histogram
- Milestone 3 — Education and socialization efforts, with the following associated deliverables:
- Documentation about how to run safetables on WMF infra (e.g. on Wikitech)
- General recipe notebooks for running generic DP data pipelines within the WMF analytics cluster
- A “Do I need differential privacy for this?” checklist/flowchart for internal WMF consumption
- Hands-on sessions to teach internal users about DP techniques and safetables
I know that this is a LOT of new information, since things have been moving quite quickly over the last few weeks. Please feel free to comment on this Phab task or email me directly if you have any questions/concerns!