As part of the work to migrate Prometheus based checks from Icinga to Alertmanager (T293399) I have discovered something that I feel needs to be double-checked before I can proceed.
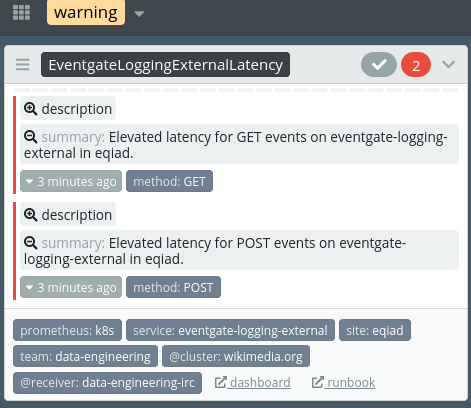
This relates to the alert for Elevated latency for eventgate-logging-external alert.
At the moment it appears to me that a latency warning should be in Icinga, but is not there due to a metric having been renamed.
The Icinga check itself is here and is currently green (although the dashboard link is broken).

I'd appreciate help please to understand which of the following is/are likely
- there is a latency issue affecting ~ 10% of these events, which requires investigation
- I should increase the warning/critical thresholds to match the observations
- there is a problem with the way that this metric is calculated
or, naturally,
- I've made a number of half-witted mistakes in getting this far 🙂
Currently, that latency alert is defined by a monitoring::check_prometheus resource in Icinga here.
It queries a Prometheus metric named service_method:service_runner_request_duration_seconds:90pct5m{service="eventgate-logging-external"}
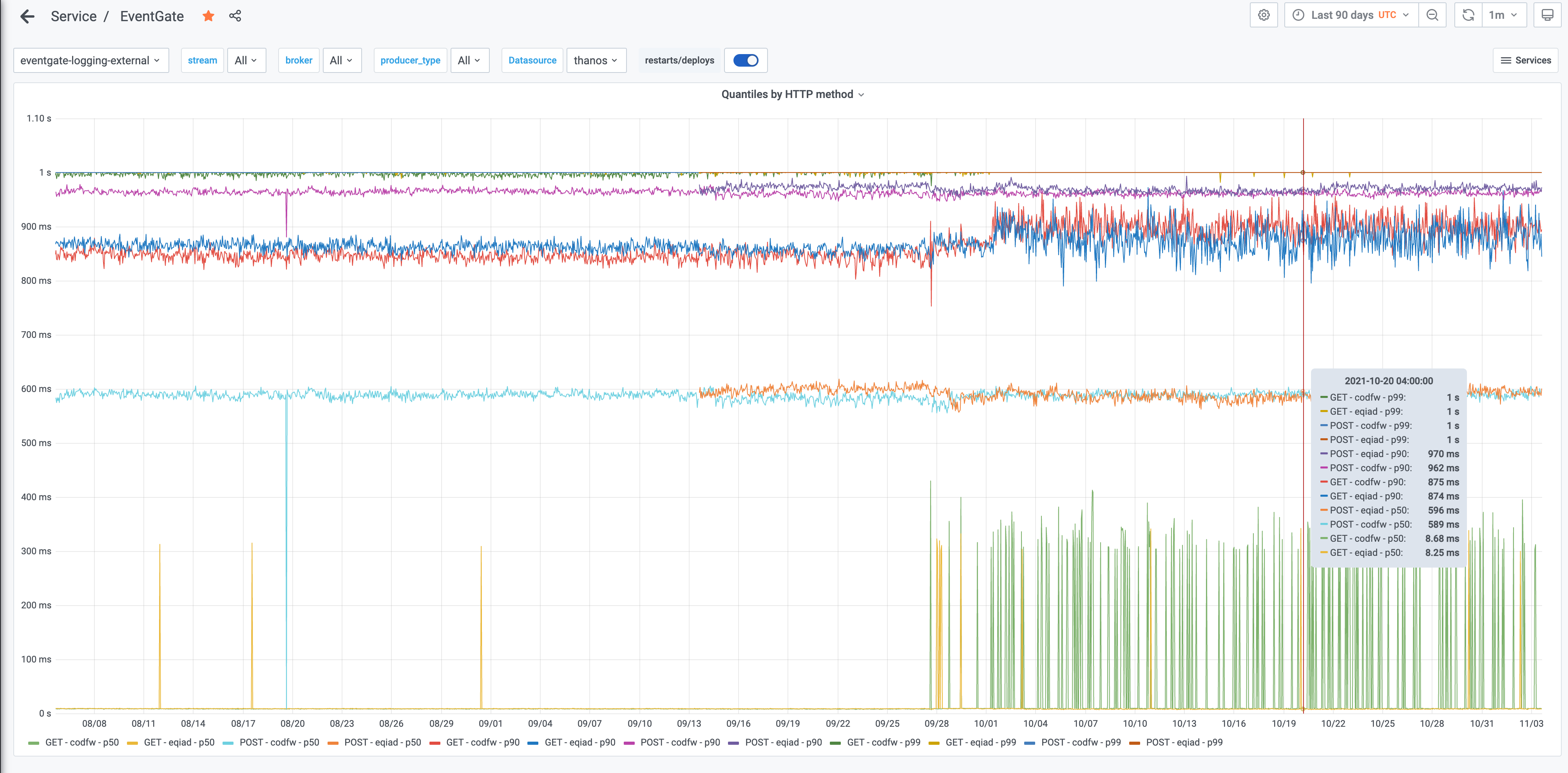
However, if we check Thanos and search for that metric, we can see that the only place it now exists is on the k8s-staging cluster.
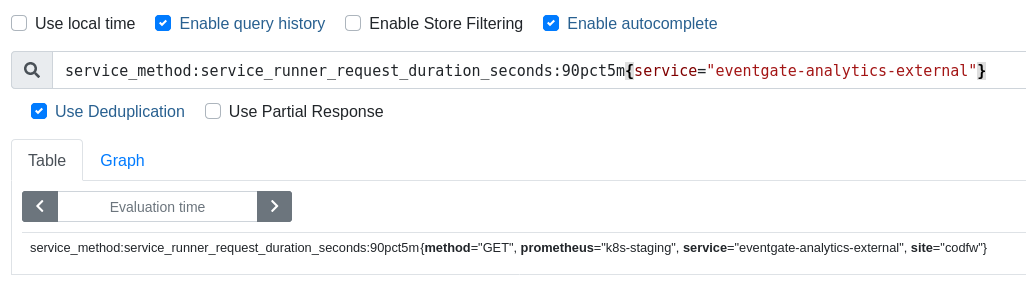
I believe that the name of the metric has been renamed from service_runner_request_duration_seconds to express_router_request_duration_seconds during the migration of this service to Kubernetes. This renaming was discussed here T238658#5947574 and here T278141#6949288.
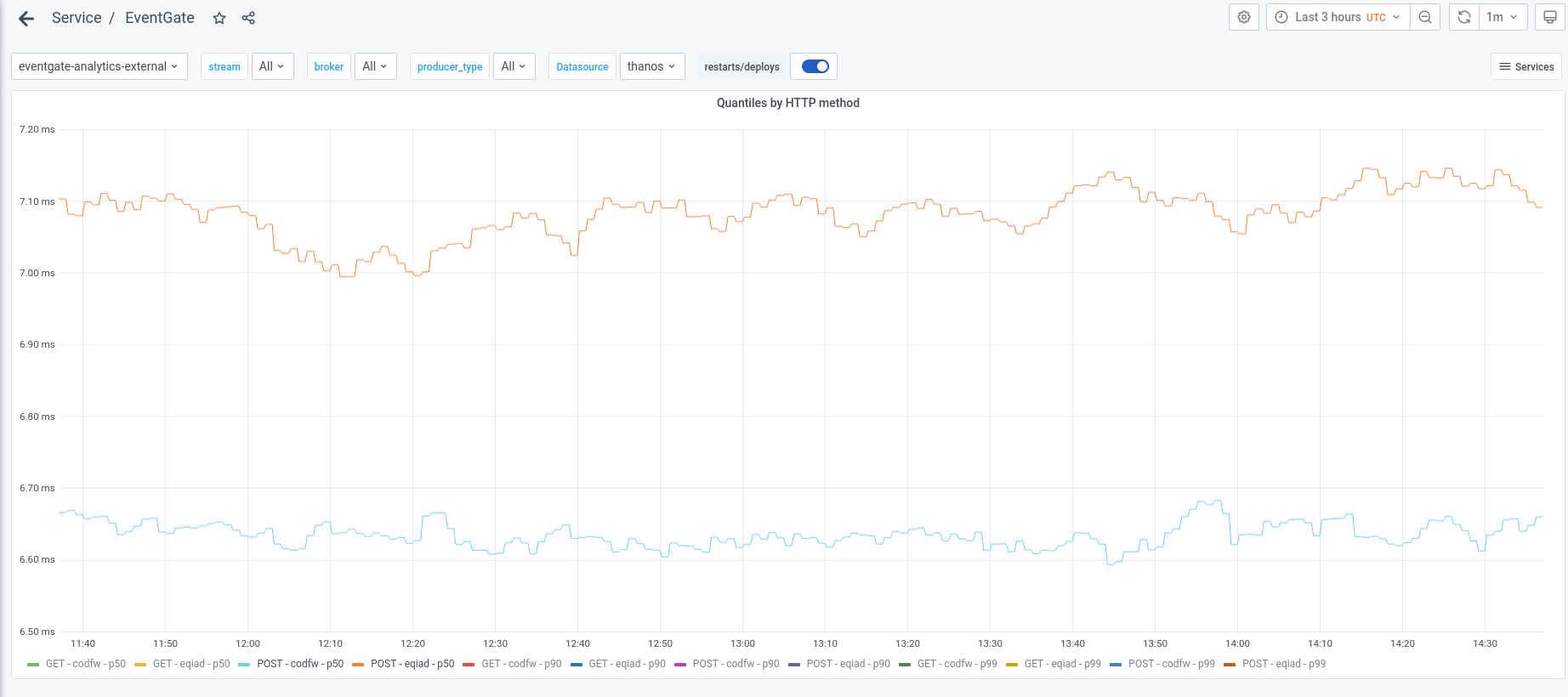
The Grafana dashboard tracking this received an update and that service_runner_request_duration_seconds:90pct5m metric, tracking the 90th centile latency is shown on a panel named Quantiles by HTTP method on the Latency row of the Eventgate dashboard here.
We can see from that graph that the 90th percentile values for that metric, including eqiad and codfw, POST and GET methods, are between 730ms and 950ms and have been for a long time.
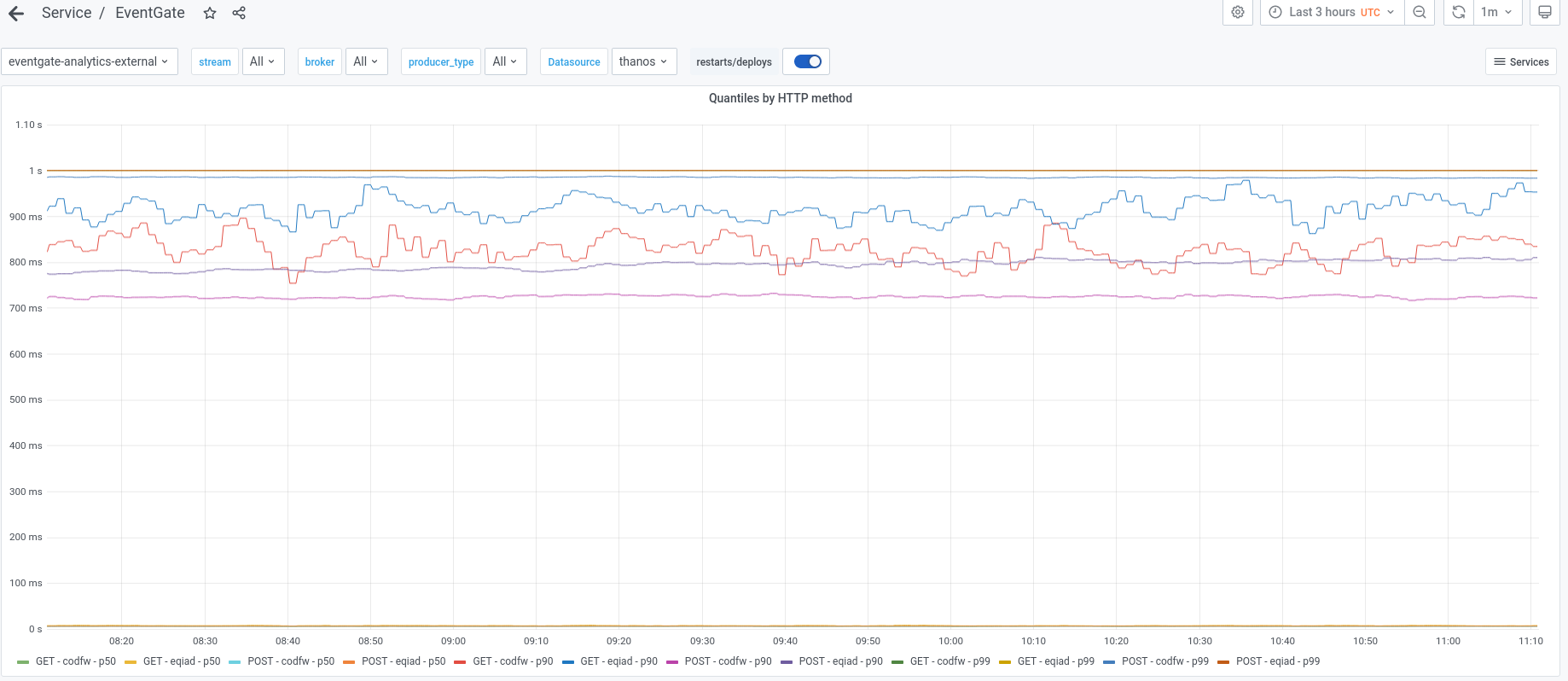
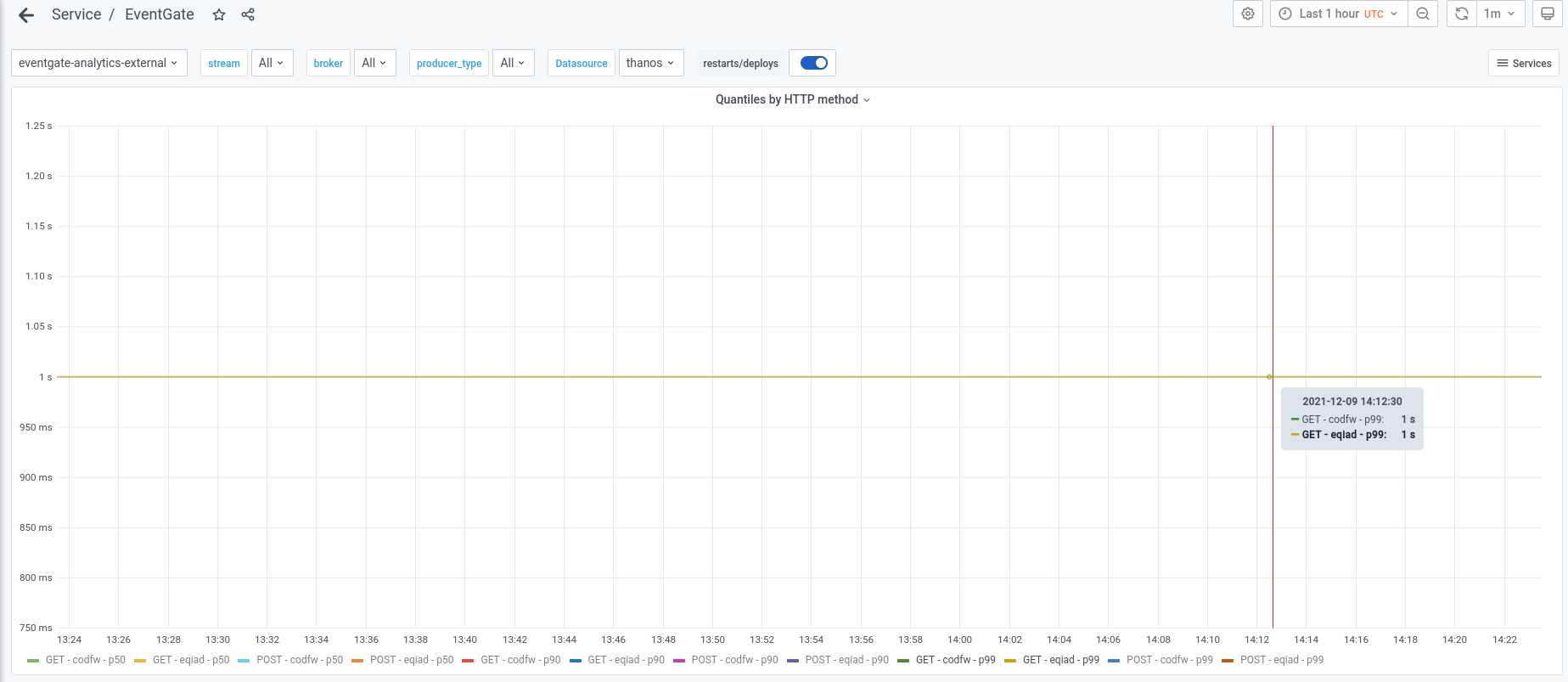
Currently the check in Icinga should issue a warning if the latency is above 500ms and a critical if it is above 1 second.
The Icinga check currently does not issue a warning because the set of values it returns is empty. See the following example for eqiad.
btullis@alert1001:~$ /usr/lib/nagios/plugins/check_prometheus_metric.py --debug --url 'http://prometheus.svc.eqiad.wmnet/k8s' -w '0.5' -c '1' -m 'ge' 'service_method:service_runner_request_duration_seconds:90pct5m{service="eventgate-logging-external"}'
DEBUG:urllib3.util.retry:Converted retries value: 2 -> Retry(total=2, connect=None, read=None, redirect=None, status=None)
DEBUG:__main__:Running 'service_method:service_runner_request_duration_seconds:90pct5m{service="eventgate-logging-external"}' on 'http://prometheus.svc.eqiad.wmnet/k8s/api/v1/query'
DEBUG:__main__:Checking vector data for []
All metrics within thresholds.
btullis@alert1001:~$ echo $?
0If I change the prefix of the metric from service_runner_ to express_router_ and re-run the same check manually, then the check seems to the correct data and exits with a warning:
btullis@alert1001:~$ /usr/lib/nagios/plugins/check_prometheus_metric.py --debug --url 'http://prometheus.svc.eqiad.wmnet/k8s' -w '0.5' -c '1' -m 'ge' 'service_method:express_router_request_duration_seconds:90pct5m{service="eventgate-logging-external"}'
DEBUG:urllib3.util.retry:Converted retries value: 2 -> Retry(total=2, connect=None, read=None, redirect=None, status=None)
DEBUG:__main__:Running 'service_method:express_router_request_duration_seconds:90pct5m{service="eventgate-logging-external"}' on 'http://prometheus.svc.eqiad.wmnet/k8s/api/v1/query'
DEBUG:__main__:Checking vector data for [{'metric': {'__name__': 'service_method:express_router_request_duration_seconds:90pct5m', 'method': 'GET', 'service': 'eventgate-logging-external'}, 'value': [1635938600.36, '0.8878082191780825']}, {'metric': {'__name__': 'service_method:express_router_request_duration_seconds:90pct5m', 'method': 'POST', 'service': 'eventgate-logging-external'}, 'value': [1635938600.36, '0.9683779399837793']}]
method={GET,POST} service=eventgate-logging-external
btullis@alert1001:~$ echo $?
1I'll tag this ticket with Data-Engineering but mention @Ottomata , @colewhite , @akosiaris, and @fgiunchedi because I believe that they may have insight into the issue and may know better than me how to investigate further.