Users on commons are reporting experiencing an increased number of upload errors, particularly with chunked upload. https://commons.wikimedia.org/wiki/Commons:Village_pump#Problems_with_uploading_files_above_100_MiB
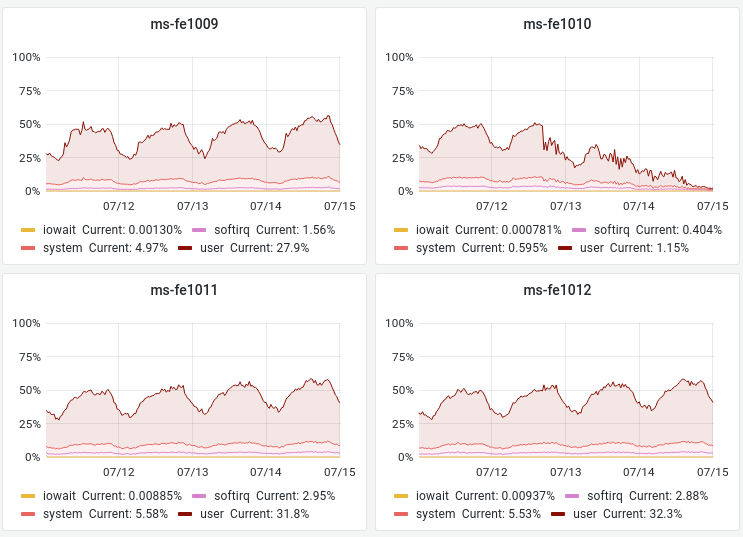
On logstash, there is a large spike in HTTP 502 (Bad Gateway) in 'SwiftFileBackend::doGetLocalCopyMulti' (and othe swift rfunctions) errors, about 10,000 per hour, starting around July 12 16:00 UTC. https://logstash.wikimedia.org/app/dashboards#/view/AXFV7JE83bOlOASGccsT?_g=h@3f6e3a2&_a=h@4a68d83
All this suggests something is partially broken with swift.