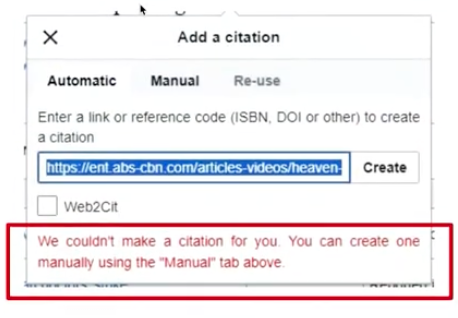
A number of websites have blocked Citoid due to the high volume of traffic its activity is placing on their websites. This results in Citoid errors when attempting to cite content by inserting these websites' URLs.
Known blocked websites
Original description
first seen today at an event: https://en.wikipedia.org/wiki/Special:Diff/1218432547
later during same event had a problem with NY times. https://en.wikipedia.org/wiki/Special:Diff/1218452300
I went home, pulled a link off NY times front page and tried a test at [[Wikipedia:Sandbox]]. (didn't save)
link: https://www.nytimes.com/2024/04/11/us/politics/spirit-aerosystems-boeing-737-max.html
error message: We couldn't make a citation for you. You can create one manually using the "Manual" tab above.
NY times was definitely working here, (2024-02-13) this URL also now broken: https://en.wikipedia.org/wiki/Special:Diff/1207056572