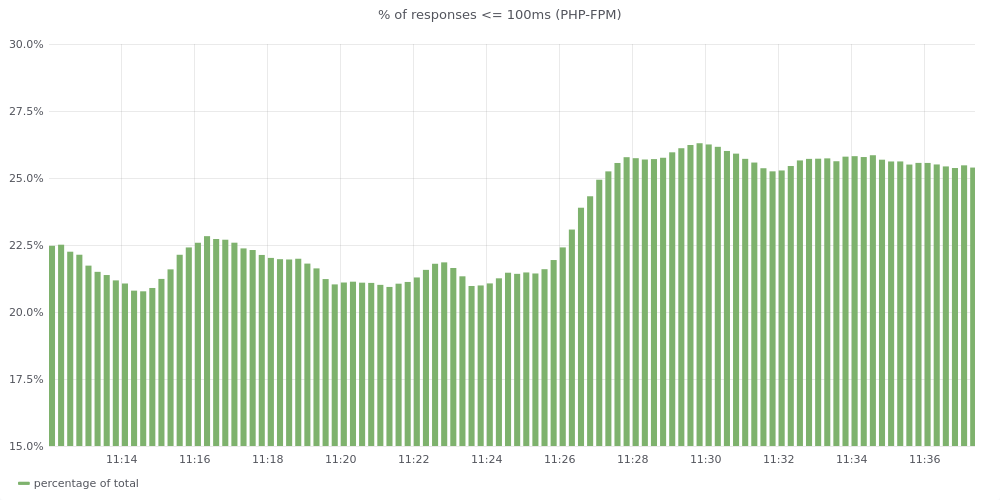
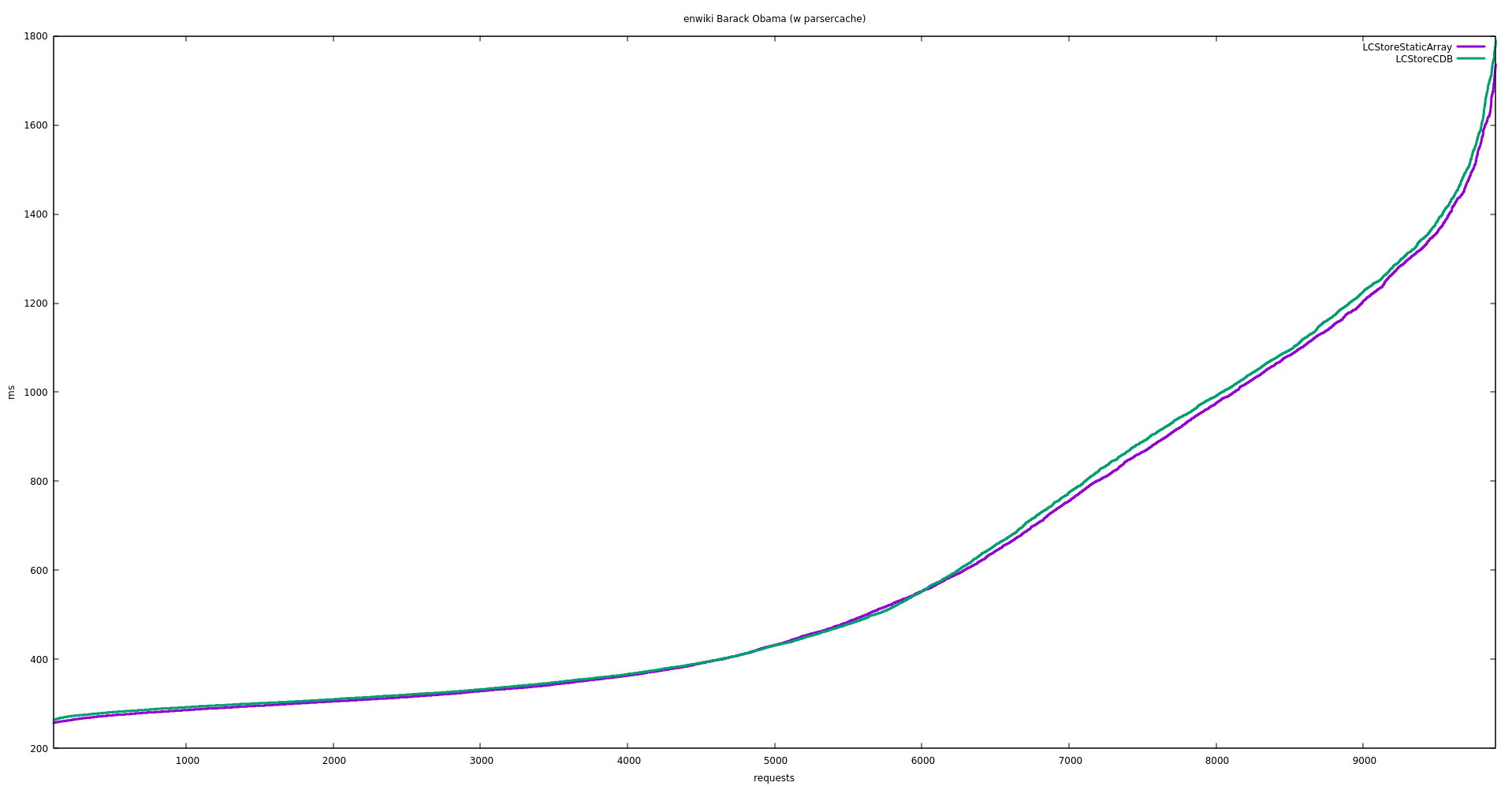
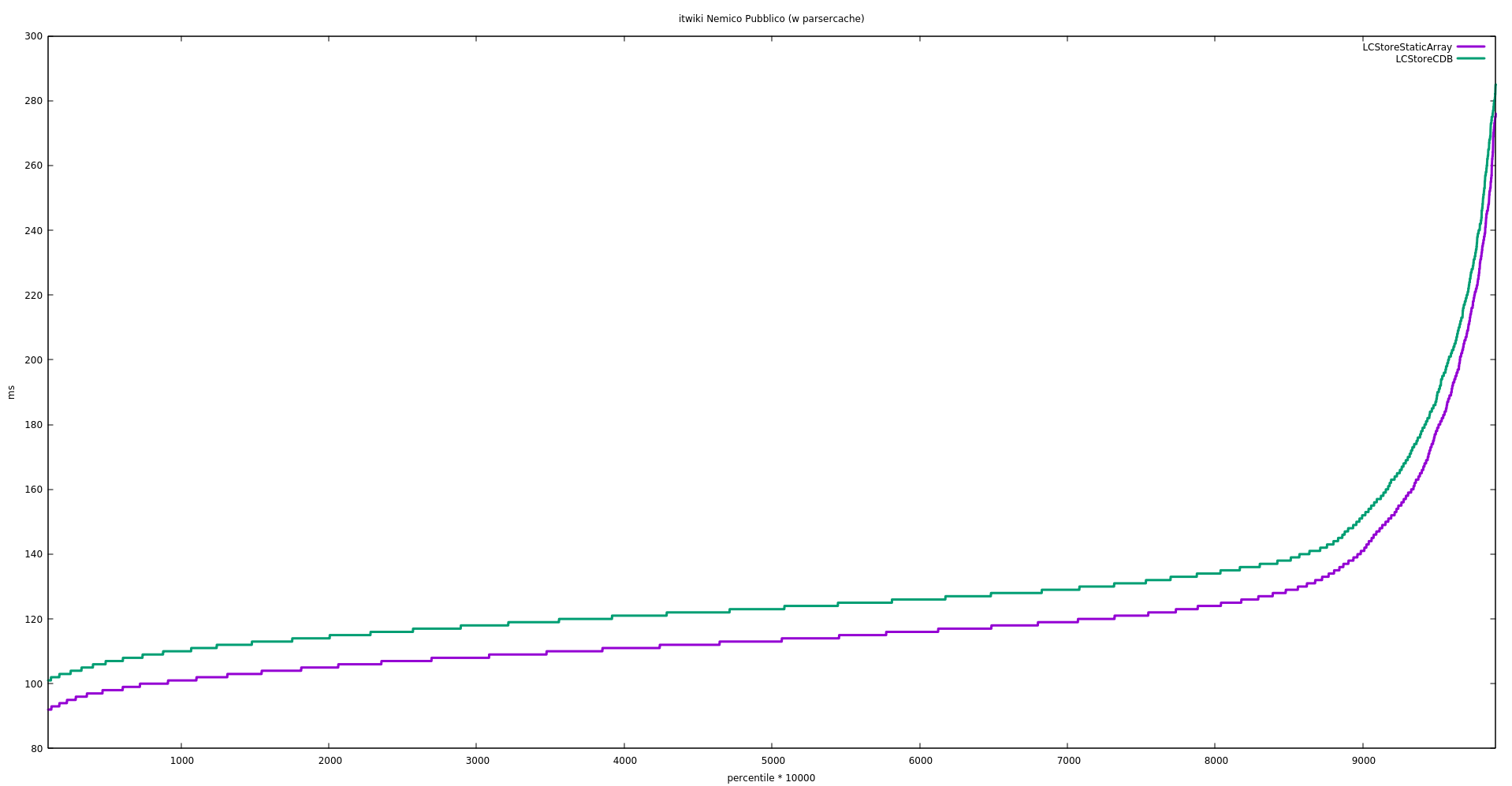
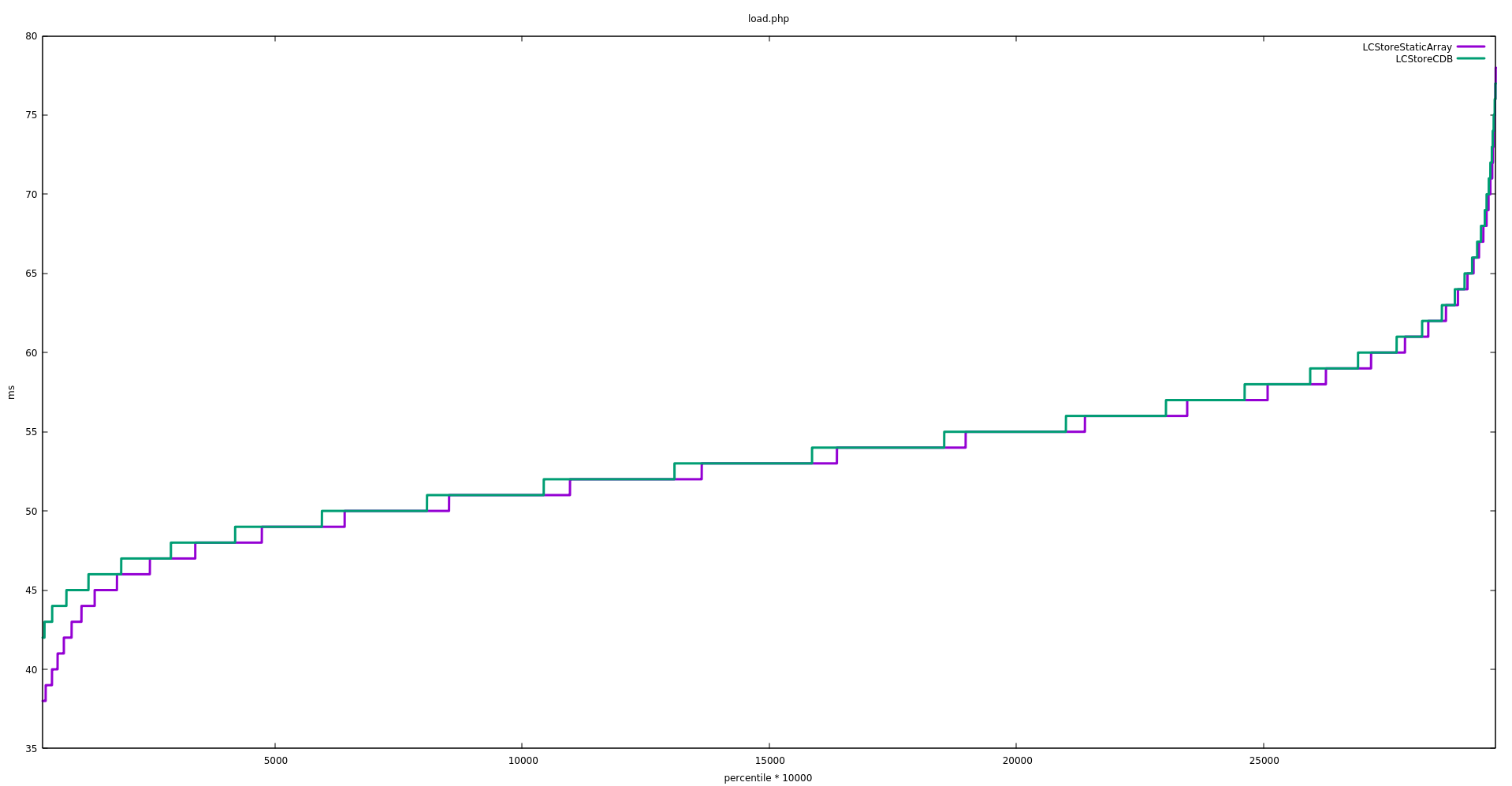
Facebook's Fred Emmott works on benchmarking HHVM's performance when running various open-source PHP frameworks. This puts him in contact with MediaWiki's codebase. He wrote in to suggest that we experiment with using plain PHP files instead of CDB for the l10n cache. We should try that and see whether it improves performance.
Deployment plan (see also T99740#5165753 by @Krinkle):
- Have Scap (also) generate l10n cache in the array format whenever it calls rebuildLocalisationCache.
- See also T105683.
- (From 2015: https://gerrit.wikimedia.org/r/224520.)
- 2020: https://gerrit.wikimedia.org/r/c/mediawiki/tools/scap/+/558243
- Enable array format for Beta Cluster wikis.
- (From 2015: https://gerrit.wikimedia.org/r/217702.)
- 2020: https://gerrit.wikimedia.org/r/#/c/operations/mediawiki-config/+/508724/
- Reverted, 2020: https://gerrit.wikimedia.org/r/651228
- Package new scap and have it deployed to production (T245530); then run a full scap.
- Enable array format for mwdebug1001/mwdebug2001 for performance testing (establish baseline on x002, detect difference if any, confirm difference in other DC). This is temporary. Undo afterward to reduce differences between debug and prod.
- Enable array format for group0 (i.e. testwikis, closed, mw.org, office).
- Enable array format for wikidata.org in production.
- Enable array format for commons.wikimedia.org in production.
- Enable array format for group1 in production.
- Enable array format for group2 in production. (all wikis)
- Update Scap config to no longer generate the old cdb format via rebuildLocalisationCache.
- Remove config switch.