
User Details
- User Since
- Mar 29 2015, 4:07 PM (474 w, 2 h)
- Availability
- Available
- LDAP User
- Tarrow
- MediaWiki User
- T Arrow (WMDE) [ Global Accounts ]
Fri, Apr 26
Thu, Apr 25
Just to summarise the latest state of this ticket:
- It appears that the data / edits in the framenet wiki, when ingested into our queryservice updater cause the queryservice node to stall with a max utilisation of CPU
- This breaks the queryservice for all wikis
- Every time we re-add framenet edits to the update queue this behaviour reoccurs
- We've tried to update the queryservice to some newer versions. While we experienced some technical problems with the very latest version we found that a newer version still did not help
- We've tried to replay some of the framenet edits in other environments but we haven't been able to concretely reproduce this bug outside of our production environment
Wed, Apr 24
It's not a black box on chrome but a slightly more graceful error image:
Is this ready for an engineer to look at now or are you two still getting the design correct?
Mon, Apr 22
Thanks, possibly we need to be more careful how we do this rewriting in https://github.com/wbstack/mediawiki/blob/main/Dockerfile#L96 to better match what is done (for example) on Wikidata. I would describe this as a bug.
Fri, Apr 19
Thu, Apr 18
Moving to the product backlog; I believe this now requires some input from @Charlie_WMDE about what a more graceful failure method would look like
This issue doesn't seem to occur as regularly on Wikidata because they do not use tinyurl for shortening.
Wed, Apr 17
Tue, Apr 16
Ran
> WikiSiteStats::find(812)->delete() = true
Found using
WikiSiteStats objects 808/809 and 811/812 have duplicate wiki ids
First occurrence was 4 April 2024 at 22:02:00 UTC+1
Mon, Apr 15
Sun, Apr 7
Added some review but I'm sorry to say I had some questions which I guess need answering and looking at by someone (@Fring ?) next week while I'm out. I also made a short PR for some diagrams that I think describe the current simplified way we create ES indices. I wondered if adding to these for the new architecture (including creating both the shared indices and the aliases) would help communicate what this will look like: https://github.com/wbstack/api/pull/779
We're now using this task to address the specific issues we're seeing related to this dataset. Following on from T361551#9687832 I was able to intermittently reproduce this maybe around 20% of the time.
Thu, Apr 4
@Epidosis No worries! as you can see I wasn't 100% certain what it should be like either :)
This is now done since we seem to have a functional QS for most wikis. T361436 is where work will continue on investigating the unusual behaviour of this specific wikibase
Hey, I talked this over with some WMDE people and we confirmed we couldn't see any data missing.
Hey I'm trying to understand your report but I'm not sure I fully understand your expected output of this query:
07:38:27.936 [main] INFO o.w.query.rdf.tool.WbStackUpdate - Starting Updater 0.3.84 (3bcfddc0f526c9a227773e68fe29419343d33993) --wikibaseHost asdfasdf.wbaas.localhost --ids Q1,Q2 --entityNamespaces 120,122,146 --sparqlUrl http://queryservice.default.svc.cluster.local:9999/bigdata/namespace/qsns_b61b483051/sparql --wikibaseScheme http --conceptUri https://asdfasdf.wbaas.localhost
07:38:59.157 [main] INFO o.w.q.r.t.change.ChangeSourceContext - Checking where we left off
07:38:59.158 [main] INFO o.w.query.rdf.tool.rdf.RdfRepository - Checking for left off time from the updater
07:39:04.159 [main] INFO o.w.query.rdf.tool.rdf.RdfRepository - Checking for left off time from the dump
07:39:05.648 [main] INFO o.w.q.r.t.change.ChangeSourceContext - Defaulting start time to 30 days ago: 2024-03-05T07:39:05.648Z
07:39:23.157 [main] INFO o.w.query.rdf.tool.HttpClientUtils - HTTP request failed: java.util.concurrent.ExecutionException: java.io.EOFException: HttpConnectionOverHTTP@529a95d::SocketChannelEndPoint@45110cb4{queryservice.default.svc.cluster.local/10.102.88.47:9999<->/10.244.0.123:37970,ISHUT,fill=-,flush=-,to=7639/0}{io=0/0,kio=0,kro=1}->HttpConnectionOverHTTP@529a95d(l:/10.244.0.123:37970 <-> r:queryservice.default.svc.cluster.local/10.102.88.47:9999,closed=false)=>HttpChannelOverHTTP@77241e03(exchange=HttpExchange@5d1f6df8 req=TERMINATED/null@null res=PENDING/null@null)[send=HttpSenderOverHTTP@221f326(req=QUEUED,snd=COMPLETED,failure=null)[HttpGenerator@4f983b7a{s=START}],recv=HttpReceiverOverHTTP@189be08c(rsp=IDLE,failure=null)[HttpParser{s=CLOSED,0 of -1}]], attempt 1, will retry
07:39:25.159 [main] INFO o.w.query.rdf.tool.HttpClientUtils - HTTP request failed: java.util.concurrent.ExecutionException: java.net.ConnectException: Connection refused, attempt 2, will retry
07:39:29.161 [main] INFO o.w.query.rdf.tool.HttpClientUtils - HTTP request failed: java.util.concurrent.ExecutionException: java.net.ConnectException: Connection refused, attempt 3, will retry
07:39:37.166 [main] INFO o.w.query.rdf.tool.HttpClientUtils - HTTP request failed: java.util.concurrent.ExecutionException: java.net.ConnectException: Connection refused, attempt 4, will retry
07:39:47.167 [main] INFO o.w.query.rdf.tool.HttpClientUtils - HTTP request failed: java.util.concurrent.ExecutionException: java.net.ConnectException: Connection refused, attempt 5, will retry
07:40:01.558 [main] INFO org.wikidata.query.rdf.tool.Updater - Polled up to 1 at (0.0, 0.0, 0.0) updates per second and (0.0, 0.0, 0.0) ids per secondWed, Apr 3
Tue, Apr 2
Once this is done our next step is to enable all the batches we marked as failed from framenet-akkadian257
We killed the one QS pod and saw it's CPU return to 0. We let it soak for 5 mins and then rescaled back up the QS updater. Things seems to be happy and we'll allow the batches to catch up.
We saw a lot of uptime checks in the logs (obviously) and we also noticed that we started being charged (!) for these around the time the incident happened so we wondered if this was part of the issue. We manually changed the path of the uptime jobs in Google Cloud Dashboard to target something that will 404 in the hope that this solved our issue.
Could also be that the queryservice itself is straining under load. It seems to be out of memory
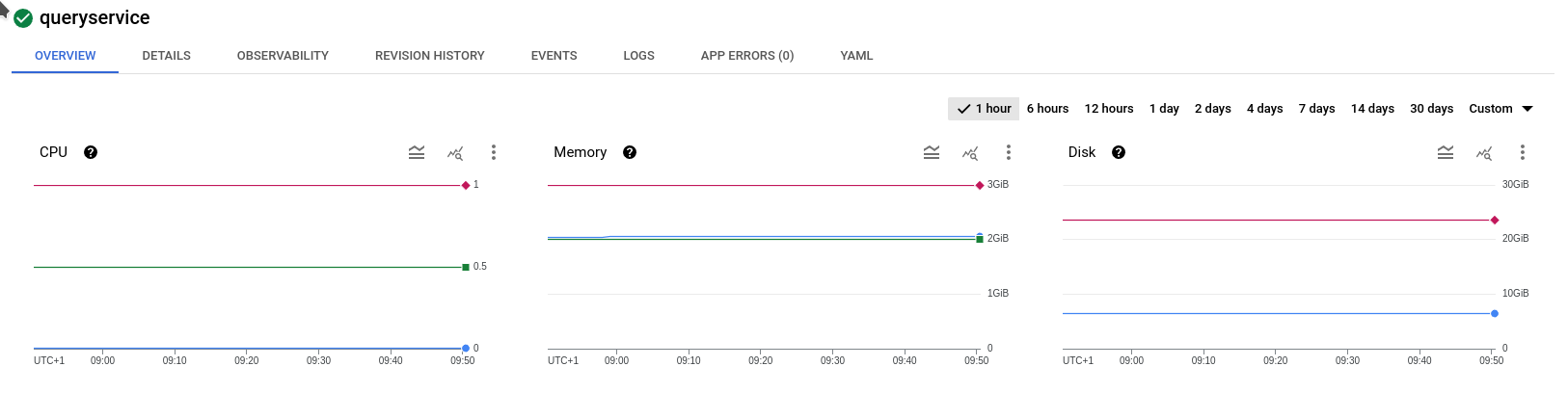
We plan to manually mark as failed all batches from this Wikis so they are no longer blocking the other wikis from updating
Mar 28 2024
Leaving this in review until tuesday as a flag just in case we suddenly see some service account keys being disabled
This has now been done thanks to WMDE IT
I think I'm still not being clear. I am proposing something like:
- Write a helm chart for an App of Apps
- Add a helmfile release for this app of apps
- Add the configuration for the app of apps to k8s/argo-config/... or similar
- Add configuration for each app (e.g. UI) to this directory too
I was (perhaps still not very clearly) imaging that we would then deploy instances of the ArgoCRDs also using helm+helmfile. I was thinking that we may well start with this App of App pattern which you can see at https://argo-cd.readthedocs.io/en/stable/operator-manual/cluster-bootstrapping/. From then on adding a "real" application (like the UI) would be done just by editing the definition of this top level app.