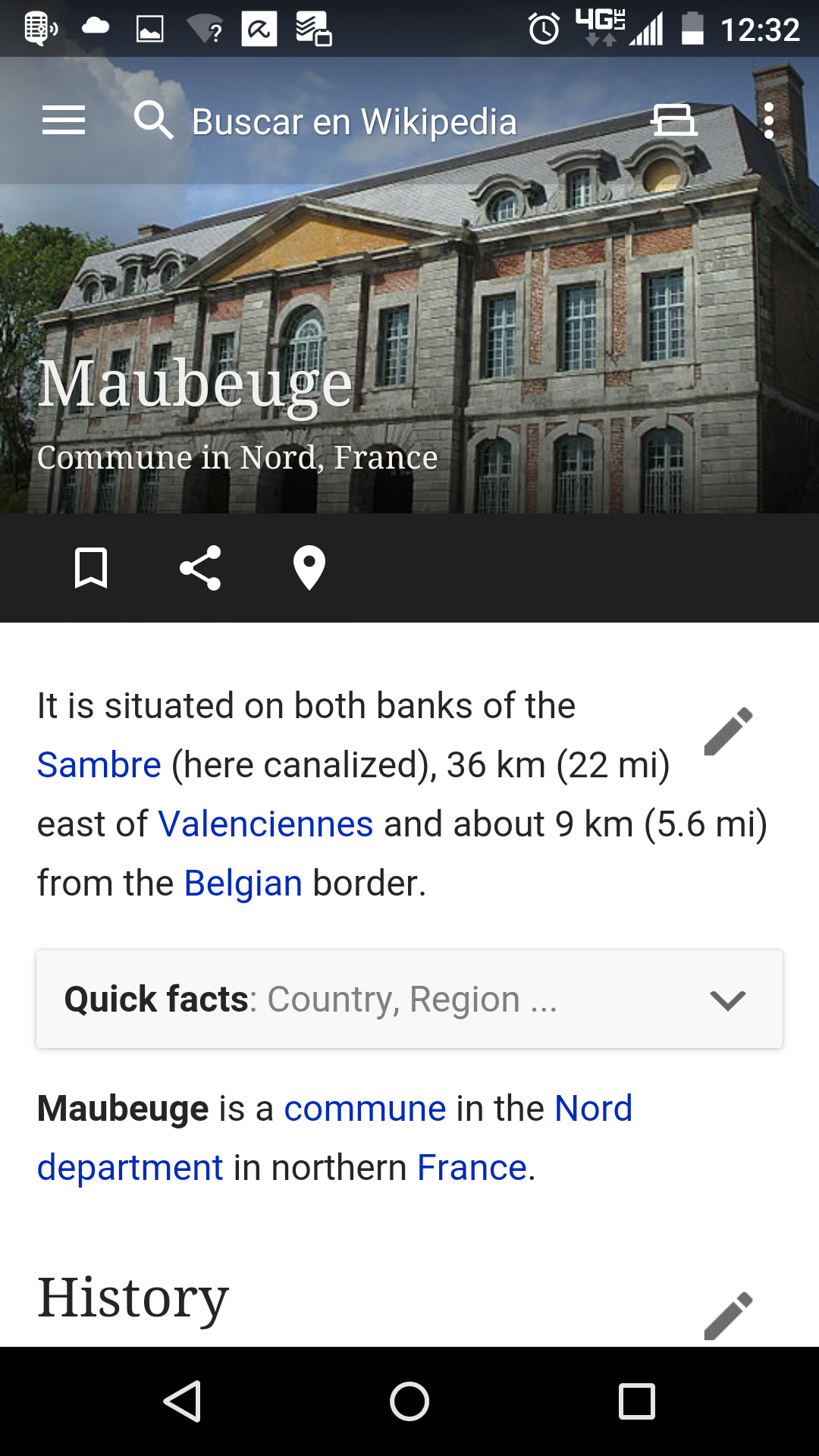
The English Wikipedia page Maubeuge begins with the following paragraphs:
{{Use dmy dates|date=October 2014}}
{{Infobox French commune...}}
'''Maubeuge''' is a [[Communes of France|commune]]...
It is situated on both banks of the [[Sambre]]...However, in version 2.1.144-r-2016-05-09 of the Android app, the paragraph "It is situated..." is displayed as the lead, with the true lead after the infobox.
Note: this only happens if Restbase is enabled. When using MW, the correct paragraph is shifted.