Author: joona.palaste
Description:
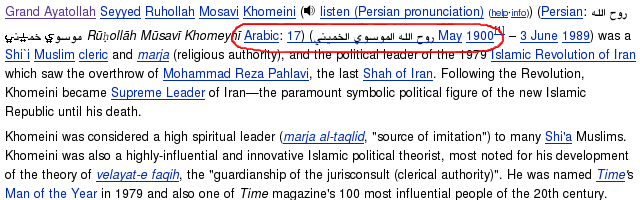
In the English Wikipedia article on Ruhollah Khomeini, having his name in the
native Arabic script (right-to-left) inside the normal English (left-to-right)
text of the article causes incorrect interleaving.
I am using Mozilla Firefox 2.0 on Fedora Core 5 Linux, and on my browser the
first two lines of the text look something like this:
"Grand Ayatollah Seyyed Ruhollah Mosavi Khomeini (listen (Persian pronunciation)
(help·info)) (Persian: [Arabic text]
[Arabic text] Rūḥollāh Mūsavī Khomeynī Arabic: 17) ([Arabic text] May 1900¹ - 3
June 1989) was a..."
I've placed "[Arabic text]" where it displays Arabic text so that this bug
report itself does not depend on the settings of the browser but illustrates the
issue as I see it. The problem is plainly visible: It is supposed to say that
Khomeini was born on 17 May 1900, but part of his Arabic name appears between
the day "17" and the month "May 1900". When checking the wiki markup source
code, everything looks OK, the Arabic text is correctly interleaved with the
western text.
Is this a bug with MediaWiki or with my browser?
Version: unspecified
Severity: normal
OS: Linux
Platform: PC
URL: http://en.wikipedia.org/wiki/Ruhollah_Khomeini